







个人阅读笔记,如有错误欢迎指正!
期刊:NeurlPS 2020 [2007.05084] Attack of the Tails: Yes, You Really Can Backdoor Federated Learning (arxiv.org)
问题:
已有很多关于联邦后门防御的方法,探索联邦学习是否真正具有鲁棒性。
创新:
证明了后门攻击在联邦学习中难以防御
如果一个模型容易受到输入扰动形式的推理时间攻击(即对抗性样本),那么它将容易受到训练时间后门攻击。此外,模型扰动后门的范数由(基于实例的)常数乘以对抗样本的扰动范数的上界(如果存在的话)决定。

1 后门检测是np难问题; 2边缘样本攻击难以被基于梯度的检测技术发现。

边缘样本后门迫使模型对看似简单的输入进行错误分类,这些输入难以成为训练或测试数据的一部分,即它们位于输入分布的尾部
方法:
数据中毒:在攻击者的数据集中插入干净和后门数据点的混合;后门数据点以特定类为目标,并使用首选目标标签
模型中毒:采用类似但算法不同的方法,训练具有投影梯度下降(PGD)的模型,在每一轮FL中,攻击者的模型不会显著偏离全局模型
p-edge-case example定义

主体方法
黑盒攻击
为p-edge-case数据中注入后门,以一定的比例混合和
实现攻击
PGD攻击(梯度下降攻击)
对手使用梯度下降。为了抵御防御(某一客户端运行梯度下降的算法过长,被服务器检测异常对其进行范数裁剪防御),对手周期性地将模型参数投影到以上一次迭代的全局模型中心的球上(以为中心,
为半径)
设定攻击预算,使
,则可保证对手发送的任何模型
都不会被基于范数的防御机制检测到
模型替代的PGD攻击
结合上步与模型替代攻击策略
其中模型参数在发送到服务器之前进行缩放,以抵消来良性节点的贡献。假设存在一恶意客户端,用
代替其原本模型
。缩放因子
用来控制
构建由和
混合而成的p-edge-case example数据集,其中长尾部分大于干净数据集
构建p-edge-case example数据集方法:假设对手有一组候选的边缘样本和一些良性样本,向DNN提供良性样本,并收集倒数第二层的输出向量。通过拟合簇数量等于类数量的高斯混合模型来得到一个生成模型,攻击方可以用它评估任何给定样本的概率密度,并在需要时过滤掉。
在实验设置和附录中详细寻找了一下该论文构造边缘后门数据集的方法,发现并未使用到正文中提到的生成模型,而还是基于常规的后门数据的收集和标签反转策略。
后门存在难以被检测证明
本文还提供了关于所提出的后门边缘数据难以被检测的证明,详细过程请参照正文
实验
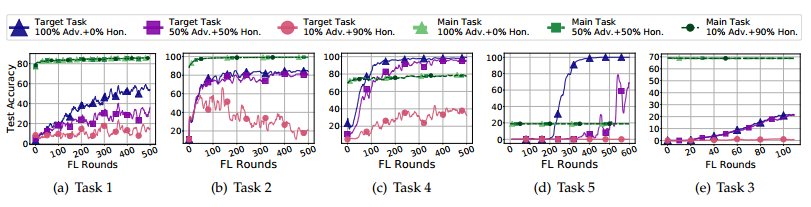
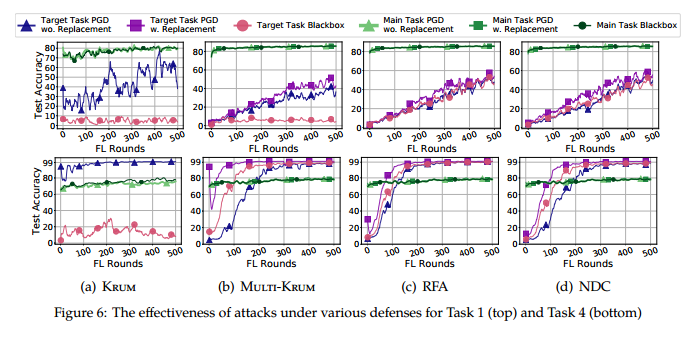
结果表明,黑盒和PGD边例攻击都是有效的,并且持续时间长。在所有经过测试的SOTA防御下,PGD边缘情况攻击尤其具有高持久性,且部分严格防御边缘后门的情况会导致良性的客户端的数据被排除。
攻击的准确性
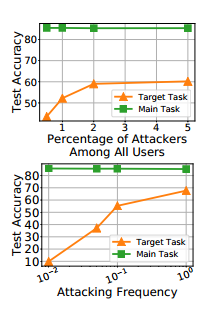
不同攻击者数与不同攻击频率结果
与SOTA防御方法对比
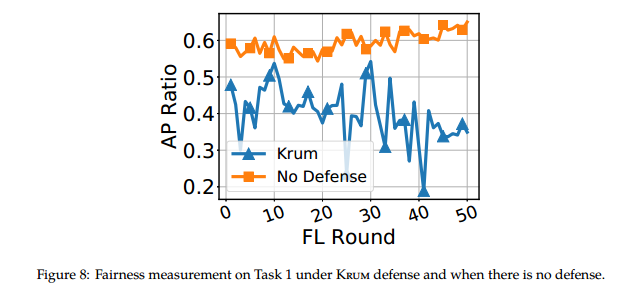
针对边缘攻击的防御方法可能存在的公平性问题:Krum和Multi-Krum中可信客户端的模型可能也被排除,弱DP噪声引起精度下降。

任务1中Krum防御和无防御对比
总结:本文实际上采用的后门攻击方法与常规方法类似,只不过将后门数据集换成了分布中的长尾数据,即本文提出的边缘数据。提供了一个很好的切入点,并且整篇文章论述下来也非常的丝滑。如果作者能对正文中提到的生成模型进行详细的描述和实验,相信能有更好的效果。















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









