







K均值聚类是最基础的一种聚类方法。K均值聚类,就是把看起来最集中、最不分散的簇标签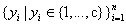
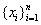
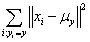
在这里,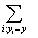
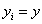
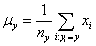
上式的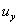
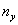
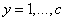
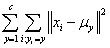
然而,上述的最优化过程的计算时间是随着样本数n的增加呈指数级增长的,当n为较大的数值的时候,很难对其进行高精度的求解。因此在实际应用中,一般是将样本逐个分配到距离其最近的聚类中,并重复进行这一操作,直到最终求得其局部最优解。
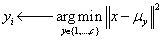
k-means算法流程如下所示:
1)给各个簇中心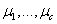
2)更新样本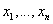
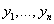
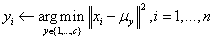
3)更新各个簇中心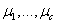
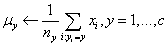
上式中,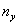
4)直到簇标签达到收敛精度为止,重复上述2,3步的计算
matlab代码如下所示:
n = 300 ;
c = 3 ;
t = randperm(n) ;
%横坐标 + 纵坐标
x = [randn(1,n/3)-2 randn(1,n/3) randn(1,n/3)+2 ;
randn(1,n/3) randn(1,n/3)+4 randn(1,n/3)]' ;
%随机种子
m = x(t(1:c),:) ;
x2 = sum(x.^2,2) ;
s0(1:c,1) = inf ;
for o = 1 : 100
m2 = sum(m.^2,2) ;
% (a-b)^2 = a^2 + b^2 - 2 * a * b
[d,y] = min(repmat(m2,1,n)+repmat(x2',c,1)-2*m*x') ;
for t = 1 : c
m(t,:) = mean(x(y==t,:)) ;
s(t,1) = mean(d(y==t)) ;
end
% norm(A) 返回矩阵A的二范数
% 矩阵的二范数 : A' * A 的最大特征值开平方
% A = [0 1 2 ; 3 4 5 ; 6 7 8] ;
% norm(A) = sqrt(max(eig(A'*A))) = 14.2267
if norm(s-s0) < 0.001
break ;
end
s0 = s ;
end
figure(1) ;
clf ;
hold on ;
plot(x(y==1,1),x(y==1,2),'bo') ;
plot(x(y==2,1),x(y==2,2),'rx') ;
plot(x(y==3,1),x(y==3,2),'gv') ;生成的图像如图所示。
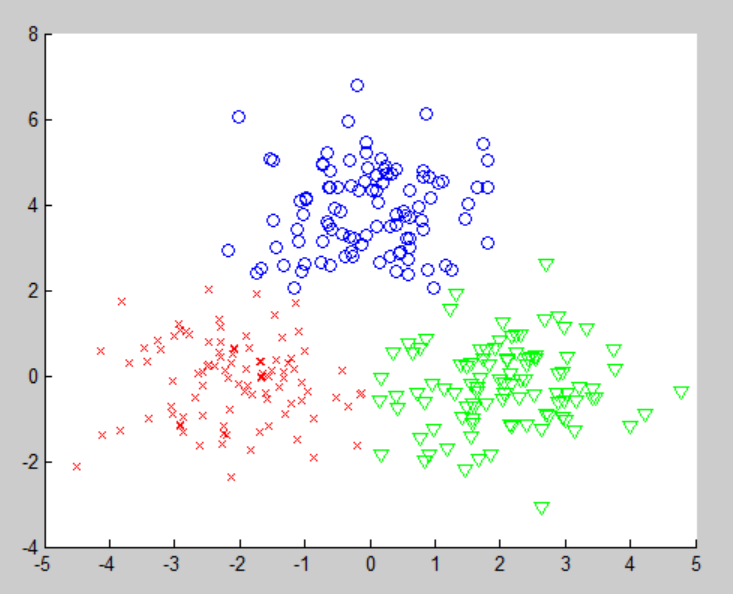
在这个例子中,K均值聚类算法得到了较好的聚类结果。。。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









