









Hadoop资源管理由两部分组成:资源表示模型和资源分配模型。其中,资源表示模型用于描述资源的组织方式,Hadoop采用“槽位”(slot)组织各节点上的资源;而资源分配模型则决定如何将资源分配给各个作业/任务,在Hadoop中,这一部分由一个插拔式的调度器完成。
Hadoop引入了“slot”概念表示各个节点上的计算资源。为了简化资源管理,hadoop将各个节点上的资源(CPU、内存和磁盘等)等量切分成若干份,每一份用一个slot表示,同时规定一个Task可根据实际需要占用多个slot。通过引入“slot”这一概念,Hadoop将多维度资源抽象简化成一种资源(slot),从而大大简化了资源管理问题。
更进一步说,slot相当于任务运行“许可证”。一个任务只有得到该“许可证”后,才能够获得运行的机会,这也意味着,每个节点上的slot数目决定了该节点上的最大允许的任务并发度。为了区分Map Task和Reduce Task所用资源量的差异,slot又被分为Map slot和Reduce slot两种,它们分别只能被Map Task和Reduce Task使用。Hadoop集群管理员可根据各个节点硬件配置和应用特点为它们分配不同的Map slot数(由参数mapred.tasktracker.map.tasks.maximum指定)和Reduce slot数(由参数mapred.tasktracker.reduce.tasks.maximum指定)。
在分布式计算领域中,资源分配问题实际上是一个任务调度问题。它的主要任务是根据当前集群中各个节点上的资源(包括CPU、内存和网络等资源)剩余情况与各个用户作业的服务质量(Quality of Service)要求,在资源和作业/任务之间做出最优的匹配。由于用户对作业服务质量的要求是多样化的,因此分布式系统中的任务调度是一个多目标优化问题,更进一步说,它是一个典型的NP问题。
在Hadoop中,由于Map Task和Reduce Task运行时使用了不同种类的资源(不同种类的slot),且这两种资源之间不能混用,因此任务调度器分别对Map Task和Reduce Task单独进行调度。而对于同一个作业而言,Reduce Task和Map Task之间存在数据依赖关系,默认情况下,当Map Task完成数目达到总数的5%(可通过参数mapred.reduce.slowstart.completed.maps配置)后,才开始启动Reduce Task(Reduce Task开始被调度)。
一个作业从提交到开始执行的过程如果所示,整个过程大约需7步
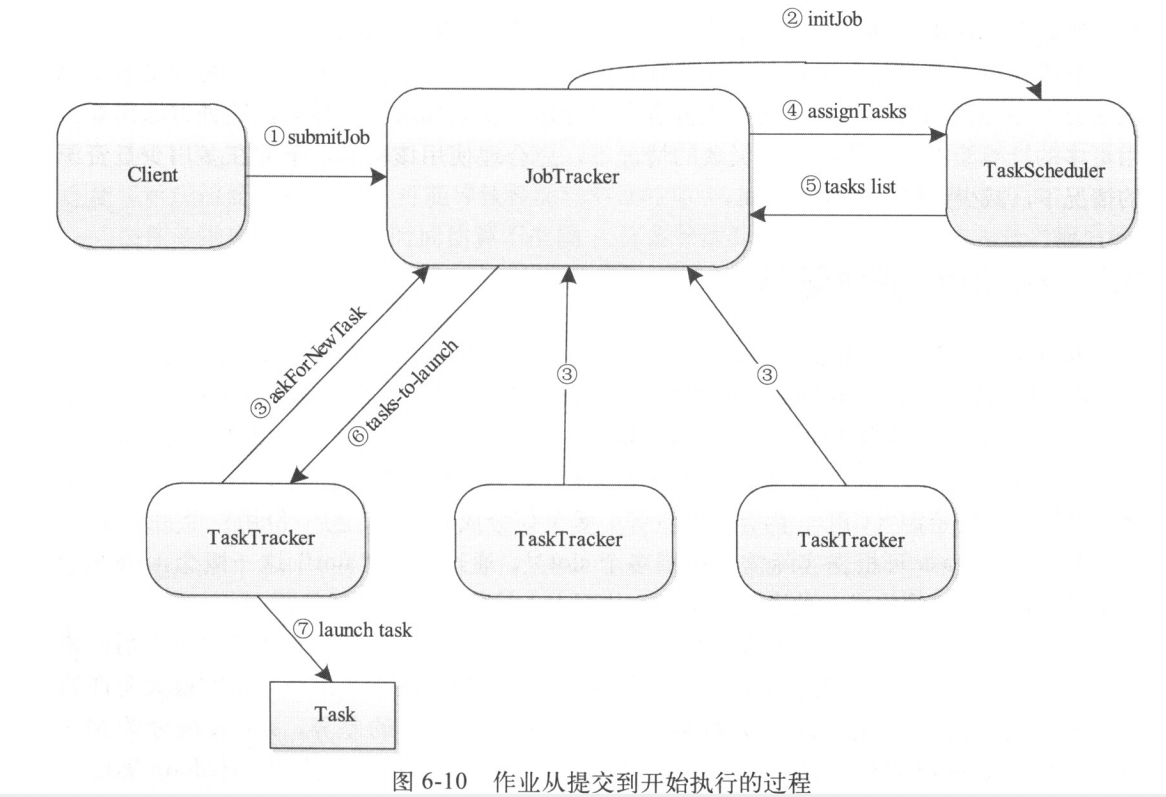
1)步骤1:客户端调用作业提交函数将程序提交到JobTracker端
2)步骤2:JobTracker收到新作业后,通知任务调度器(TaskScheduler)对作业进行初始化;
3)步骤3:某个TaskTracker向JobTracker汇报心跳,其中包含剩余的slot数目和能否接收新任务等信息;
4)步骤4:如果该TaskTracker能够接收新任务,则JobTracker调用TaskScheduler对外函数assignTasks为该TaskTracker分配新任务;
5)步骤5:TaskScheduler按照一定的调度策略为该TaskTracker选择最合适的任务列表,并将该列表返回给JobTracker
6)步骤6:JobTracker将任务列表以心跳应答的形式返回给对应的TaskTracker;
7)步骤7:TaskTracker收到心跳应答后,发现有需要启动的新任务,则直接启动该任务















04-01
 381
381
381
10-02
306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









