






机器学习需要知道的关键知识
- 机器学习需要知道的关键知识
- 摘要
- 机器学习介绍Introduction
- 学习算法表示评估优化Learning Represention Evaluation Optimization
- 泛化能力最重要It is Generalization that counts
- 仅仅拥有数据是不够的Data alone is not enough
- 过拟合有多方面的解释Overfitting has many faces
- 高维问题Intuition Fails in high Dimensions
- 理论证明并不是看上去那样Theoretical Guarantees are not what they seem
- 特征工程是关键Feature Engineering is the key
- 数据比算法更有用More Data Beats A Clever Algorithm
- 多尝试几个模型Learn Many ModelsNot just one
- 简便并不意味着准确Simplicity does not imply accuracy
- 能表示并不意味着可学习Representable does not imply learnable
- 相关性并不代表因果关系Correlation does not imply Causation
- 总结
摘要
机器学习算法主要从数据中建立模型,获得泛化能力,在处理未知的数据时,根据建立的模型得出想要的结论。这种算法,可以轻松解决人工编程所不能解决的问题,而且在数据倍增的今天,这种算法在很多领域得到了很好的应用,比如垃圾邮件过滤,产品推荐系统,等等。这篇文章主要介绍机器学习中一些要注意的重点和常见问题,还有一些要规避的陷阱。
机器学习介绍(Introduction)
机器学习主要是基于数据驱动,算法从现有的已经标记的数据中学习“经验”,用这些经验来判断未来的未标记的数据。现有的机器学习算法有很多种类,本文主要是基于“分类(classification)”算法来进行介绍,当然相关的问题和知识在机器学习领域都是共通的。分类算法是从特征数据(feature values)到数据种类(class)的映射。将训练数据集(training set) 输入学习器(learner)进行训练,输出一个分类器(classifier),这个分类器可以正确输出未知数据的种类。
学习=算法表示+评估+优化(Learning = Represention + Evaluation + Optimization)
- 表示(Represention)
一个分类器需要表示成计算机能理解的语言,在选择学习器的时候,往往决定了算法的学习能力,学习器一旦确定下来,那么它能学到的分类器的范围(这个范围可以叫做假设空间(hypothesis space))也就确定了,这往往决定了学习算法的极限。如果分类器不在这个假设空间之中,那么这个算法是不会学习到。 - 评估(Evaluation)
一个评估函数(evaluation function)也可以叫做目标函数(objective function) 或 评分函数(scoring function),评估函数用来评估分类器的好坏,评估函数又可以能会跟我们在训练分类器时用的评估函数不一样。 - 优化(Optimization)
最后需要一个方法,在假设空间(hypothesis space)中,找到最优的分类器,优化器的选择时机器学习算法的关键,他决定了学习的效率,和分类器的准确率。
图下的表中列举了这三部分的例子:
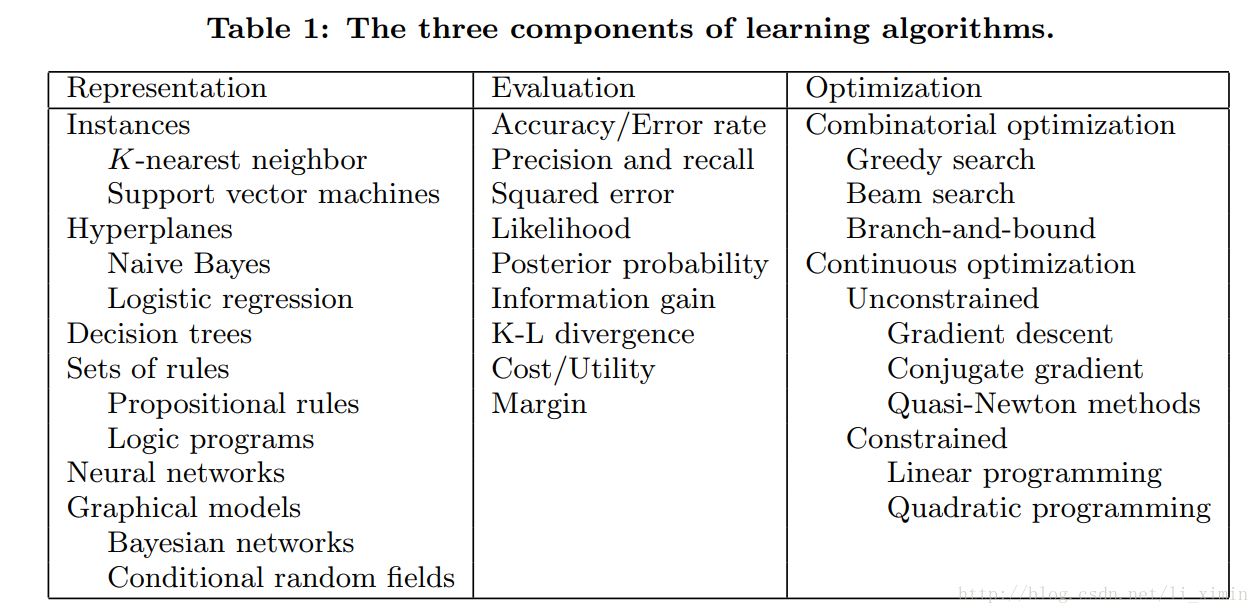
现在没有统一的简单标准来说明如何选择这些算法。
泛化能力最重要(It is Generalization that counts)
机器学习最基本的目标就是获得在训练数据集之外的泛化(generalize)能力。算法的目标不是为了在训练集上的预测误差达到最小,而是让算法在整体数据上获得良好的预测能力。初学者往往会用测试数据集来用做训练数据,这是极其错误的做法,测试数据集应该在最终模型训练成型准备发布时再使用,用于最终验证模型的泛化能力。如果在训练过程中,想要验证训练效果,那么数据集可以分为训练集,验证集和测试集。训练集用于训练模型,验证集用于训练过程中,对模型进行验证;测试集用于最终结果的测试。如果这样划分减少了训练能用的数据集,那么可以使用交叉验证法。目标函数只是我们为达到泛化能力的一种验证手段,并不是根本目标,所以有些情况下,局部最优解可能优于全局最优。(全局最优很有可能造成模型的过拟合,我们需要的是提高泛化能力,而不是在训练集上找到最好的模型。)
仅仅拥有数据是不够的(Data alone is not enough)
泛化能力作为训练模型的目标还拥有另一个结论:无论你拥有多少数据,都是远远不够的。机器学习对于数据的预测是基于全体数据的分布,如果你获得数据对于整体数据全集没有代表性,或者说没有同样的分布,训练出来的模型就会有较大的误差。对于任意两个不同的算法,对于所有问题集的平均性能是相同的,(No Free Lunch 原理,NFL)。
但是在现实生活中,需要处理的问题都不会代表所有问题集,它往往是某个特定问题的分布。选择算法的关键就是找到一个能够简单描述该问题的模型。
回归机器学习的发展,学习就是从较少的数据中,获得更多知识和更准确的模型。编程就像建筑,需要我们从地基和构架一点点开始建造,而机器学习就像是种田,我们播好了种子,剩下的就让它自由生长,从数据中获取营养。成长的质量由算法和数据共同决定。
过拟合有多方面的解释(Overfitting has many faces)
分类器在训练集的准确可以达到很高(比如90%),但是在测试集上进行测试时却降低为50%,说明模型过拟合。模型没有能够从训练数据中将分布学习出来,而是通过“死记硬背”将训练数据“记”了下来,没有学会“举一反三”,相对应的是欠拟合,分类器在训练集上的训练准确性很低。
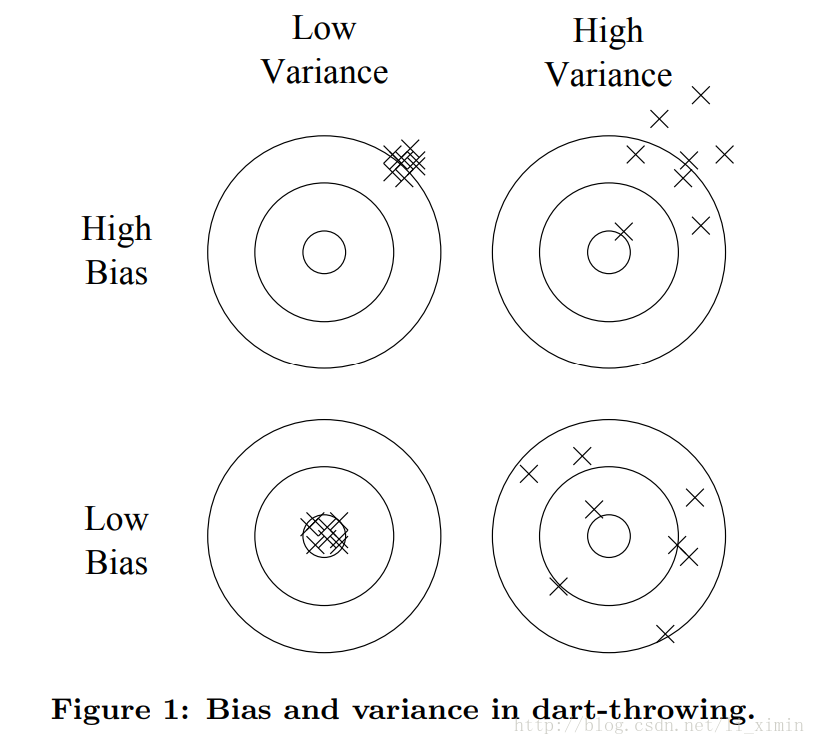
分类器的泛化能力可以分成两个部分:偏差(bias)和方差(variance),如上图所示,偏差代表了同样特征的分类跟真实分类之间的误差,而方差代表了拥有同样特征的数据得到同一种分类(这个分类也许与真实分类有差距,这就要取决于偏差)的趋势,偏差与方差之间往往需要权衡,最好做到偏差和方差都很低。强负分类样本假设比弱正分类样本假设更好,因为后者的学习器需要更多的数据来避免过拟合。
过拟合有很多种方法来处理和避免:
- 交叉验证
- 正则化惩罚
数据的噪音(比如一个错误标签的样本)确实是会加重过拟合,但是过拟合的真正原因不是噪音导致的。
高维问题(Intuition Fails in high Dimensions)
机器学习中最大的问题就是维数灾难(curse of dimensionality),即许多算法在低维数据上可以很好工作,但是在高维数据上就会很棘手,在机器学习中,这种表现更为突出。机器学习有更多的数据,更高维的特征向量,特征的维度更多,对应需要训练的参数维度也更高,计算的相关性也更多,如果真正相关的少量特征隐藏在很多维度的特征向量中,这让算法很难进行学习。
比如说,最近邻算法,当他在数据样本维数增多的情况下,算法也变得复杂,在离样本最近的距离上可能会有很多样本都出现,大大加大了算法的分类难度。这只是高维数据上问题之一,我们在三维空间上的直觉,在高维空间中会变得无法运用。
如果数据是在二维或者三维空间上,那么我们很容易找到数据分类的边界,但是如果在更高维度的空间上,我们就很难理解和分清分类边界(有种说法是当人类可以看到更高维空间的事物,那么就不需要机器学习了)。在高维空间上,我们很难理解发生了什么,创建一个好的分类器就比较困难。有时候,天真的以为多加一些特征有益于提高分类器的准确性,但是更多的时候,维数带来的灾难比利益更可怕,尤其是在增加的特征值上跟分类没有任何相关性。
幸运的是,在大多数应用中,所有特征不是均匀分布到所有实例空间上,一些相关的特征都是集中在某一些低维度特征上,学习器可以直接利用这些特征,或者让算法做降维处理。
理论证明并不是看上去那样(Theoretical Guarantees are not what they seem)
现在的大多数论文都有很多理论证明。很多证明都是在数据充足的情况下确保算法有良好的泛化性。理论上已经证明了机器学习在概率上的可行性;另一种普遍的理论证明是如果有无限的数据,学习器会保证输出一个正确的分类器。
在机器学习实际使用中,理论证明不是实际决策的准则,但是可以帮助我们更好的理解和使用算法。理论和实践相结合正式机器学习发展的主要动力,但是要注意的是:学习是一个很复杂的现象,仅有理论上的证明和算法的实现,并不意味着理论证明是算法能实现的原因。
特征工程是关键(Feature Engineering is the key)
特征是机器学习算法的关键,如果能够从数据中提取很优质的特征,那么学习算法实现将会很简单,相反,如果数据中没有特征,那么学习器什么也学不到。特征工程就是这个作用,他有很多方面,包括数据转化,数据相关性等等介绍。
一个机器学习工工程,需要有很多步骤,数据收集,数据整合,数据清理,数据整合,还有特征工程过程中的试错,机器学习不是一蹴而就的工程,而是要不停迭代,调试的。即便今天可以取得不错的结果,如果数据分布慢慢开始变化,那么算法也要开始变化以适应新的数据分布。
有些特征数据可能直接对分类结果产生影响,有些则不会,但是你需要考虑的是,当一些特征组合在一起就可能提取出更好的特征。如何提取这些信息,是非常费时的,如果稍有不慎,还有可能造成分类的过拟合。
数据比算法更有用(More Data Beats A Clever Algorithm)
根据以往的经验来说,拥有巨量数据的一般算法表现出来的性能会比拥有少量数据的优质算法好得多。但是这就会出现一个问题:扩展性(scalability)。在以前机器学习的瓶颈是时间,内存,训练数据成为瓶颈,但是在大数据时代,数据已经不再是瓶颈。如今成为瓶颈的是时间,拥有巨量的数据但是训练所花费的时间就很长。这就会成为一个悖论,拥有很多数据就意味着可以训练更复杂的分类器,但是所花的时间是不可估量的。所以有很多研究学者在研究如何最快学到最复杂的分类器,很多论文也在这方面做改进。

看上图,对于二分类问题来说,许多算法都能找到他们的分类边界,在更高维的数据上,这种相同分类效果的不同分类边界就会更多。
在实践中,往往都是从较为简单的学习器开始尝试(比如先用朴素贝叶斯,而后用logsitc回归;先用k邻近法,后用支持向量机)。越复杂的算法,需要调的超参数也越多,越复杂。往往会花费很多时间去调参。
学习器一般分为两种,一种是学习器的模型固定了,比如线性分类,还有一种是学习器的规模随数据的变化而变化,比如决策树。固定规模的学习器能从大量数据中获取更好的效果,但是变化规模的学习器就不一定了,表面上,他们从数据中得到更好的功能,实际上它收到算法的限制,比如落入极小值点,或者计算成本增加。在设计学习器和训练分类器之间没有严格的界限,任何可用的信息都可以直接设计或者由数据训练进入分类器。
多尝试几个模型(Learn Many Models,Not just one)
以前的结果经验表明,如果仅仅只选取最优的一个模型,效果没有几个模型结合在一起的效果好,如果将一些不同模型结合在一起,结果会大很多,所以现在有模型集成(model ensembles)算法(bagging boosting,stacking),这是因为在大大降低方差的同时,只增加了少量偏差。
简便并不意味着准确(Simplicity does not imply accuracy)
奥卡姆剃刀原理阐述了如无必要,勿增实体(entities should not be multiplied beyond necessity),在机器学习中,往往用这个原理来选两个相同训练误差之中模型最简单的那个模型,简单的模型可能会拥有更高的测试误差。但是在现实中,往往有很多反例,”No Free Lunch”原理也表明了剃刀原理的不现实。
换个角度来看奥卡姆剃刀原理,把原理中的复杂性,看作为机器学习中学习器的假设空间。更小的假设空间就会有更好的泛化能力。然而这并不能作为我们选择模型的原因,我们选择模型是因为模型表现得更优异,而不是更简单。
但有些研究者发现,在更大的假设空间上学习与较小的假设空间相比,学习器更不容易出现过拟合。所以假设空间的大小只能作为模型选择一个大概指导,真正决定机器学习性能的是最后学习选取的模型。
能表示并不意味着可学习(Representable does not imply learnable)
模型可以建立并不代表模型就能学习,在一些连续的样本空间上,要表示一个很简单的函数可能会需要许多不同的参数;还有在一些假设空间中,虽然模型可以描述,但是要找到正确的模型有可能也是不现实的。所以一些选择模型的问题,可以转化为“这个模型可学吗?”,并不是这个“模型是否可以实现”。
相关性并不代表因果关系(Correlation does not imply Causation)
数据之间的相关性并不能代表数据之间的因果关系,但是在算法中,相关性的结果就已经被当做因果关系了。通常,机器学习预测结果的目标是为我们的行为做一个指导。但是如果缺少实践,学习的结果将很难得到验证。一些学习算法能提取数据中潜在的因果关系。换句话说,数据相关性有时也是因果关系的一小部分,我们利用这一点进行更深入的调查,研究。
总结
本文很概况的讲述了机器学习领域的一些共同问题,对于深入了解机器学习算法有很好的指导作用。在工程实践(如建模,调参等等)中,拥有这些认识,可以帮助我们更好的提高工作效率,也有助于构建算法及调试算法的灵感。
原文推荐网址:
http://www.cs.washington.edu/homes/pedrod/class
http://www.videolectures.net















 5717
5717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









