






摘要
图像光栅化是计算机图形学中一个成熟的技术,而图像向量化,即光栅化的逆过程,仍然是一个主要的挑战。最近,基于深度学习的先进模型实现了向量化和向量图的语义插值,并展示了生成新图形的更好拓扑结构。然而,深度模型难以推广到域外测试数据。生成的SVG文件也包含了复杂且冗余的形状,这在进一步编辑时并不十分方便。具体来说,图像中的关键逐层拓扑结构和基本语义仍然没有得到很好的理解和充分的探索。在这项工作中,我们提出了逐层图像向量化,即LIVE,以将光栅图像转换为SVG文件,并同时保持其图像拓扑结构。LIVE可以生成具有逐层结构的紧凑SVG形式,这些形式在语义上与人类视角保持一致。我们逐步添加新的贝塞尔路径,并使用逐层框架、新设计的损失函数和组件级路径初始化技术来优化这些路径。我们的实验表明,LIVE呈现的向量化形式比之前的工作更合理,并且可以推广到新的图像。借助这种新学习的拓扑结构,LIVE为设计师和其他下游应用启动了人类可编辑的SVG文件。

图1:我们分层图像矢量化学习过程的示例。所提出的方法能够以分层粗到细的方式重建图像,仅使用少量路径。“N”表示路径编号。
1 引言
可缩放矢量图形(SVGs)[23],通过一系列参数化形状基元描述图像,最近因其在计算机图形学中的高实用价值而受到越来越多的关注。与使用有序像素表示视觉概念的光栅图像相比,矢量图像具有许多优势,如文件大小紧凑和分辨率无关性。最重要的是,矢量图像提供了分层拓扑信息,这对于图像理解和编辑至关重要。
在过去的几年中,我们见证了图像到矢量转换[14, 3, 24, 7, 29, 16]方面的各种成就,这主要得益于两个技术方向的发展:构建强大的生成模型和采用合适的可微分渲染方法。尽管这些方法在矢量化和生成方面具有令人期待的能力,但它们总是忽视了光栅图像背后隐藏的拓扑信息。这种信息的缺失总是导致矢量化学习不足,并需要额外的形状基元来弥补[14, 38, 15]。一些方法试图通过专注于特定的简单数据集[24, 25]或采用分割预处理方法[8, 7]来解决这一困境,但每种方法都有其自身的缺点和微妙之处。第一种工作学习探索字体或表情符号的几何信息,但不能推广到广泛领域。另一种考虑分割预处理方法需要繁重的预处理操作,并且会将高对比度纹理分割成多个小区域,导致冗余[8]。因此,社区中需要一种简单而有效的方法来捕获图像到矢量转换的分层表示。
在本文中,我们介绍了一种分层图像矢量化方法,称为LIVE,用于将光栅图像转换为矢量图形(即SVG)并具有分层表示。与之前的工作[15, 24]不同,LIVE是无模型的,不需要形状基元标签。这一属性帮助我们摆脱特定领域(如字体和表情符号)的限制,并绕过SVG数据集收集或泛化的困难。此外,LIVE具有直观且简洁的学习过程。在每一步中,我们追求的是最大化拓扑探索,而不仅仅是最小化像素差异。这一想法背后的关键洞察是,简单地最小化矢量化误差(例如,输入光栅图像与渲染矢量图形之间的MSE损失)将导致颜色均值误差。我们通过组件级路径初始化方法和一种新的无符号距离引导焦点损失函数(UDF损失)来实现这一点。此外,为了缓解在优化过程中总是出现的自交叉问题[24],我们提出了一个新的自交叉损失(Xing损失),通过向控制点优化添加约束来实现。
我们评估了我们提出的方法在各种任务中的有效性,包括图像到矢量转换和跨域插值(例如,剪贴画、表情符号、照片和自然图像),以展示LIVE的效果。我们在这项工作中主要贡献可以总结如下:
• 我们提出了LIVE,这是一个通用的图像矢量化流程,以分层方式优化矢量图。我们的渲染方案是完全可微的,并且可以生成与人类感知高度一致的分层SVGs。
• 与LIVE一起,我们还引入了一般的初始化方法和新的损失函数,包括自交叉损失(Xing损失)和无符号距离引导焦点损失(UDF损失)。这些方法改进了从光栅图像生成SVGs的过程,减少了曲线交叉并最小化了形状失真。
• 综合实验表明,LIVE可以在各种域中生成精确且紧凑的SVGs。我们的SVG结果在简洁性和分层拓扑方面超过了之前的工作。
2 相关工作
在本节中,我们主要总结了先前的方法,并介绍了与我们论文密切相关的作品。
2.1 光栅化和矢量化
光栅化和矢量化是计算机图形学中的对偶问题。在过去的几十年里,许多光栅化工作都集中在有效的渲染[20, 11, 9, 19]或抗锯齿[6, 4, 2, 18]上。传统的矢量化方法[28, 32, 33, 13, 5, 34]在矢量化之前对图像进行了预分割。其中,[28]和[5]利用了经验性的两阶段算法,将分割的组件回归为多边形和贝齐曲线。研究人员还研究了独立于分割的其他方法,例如扩散曲线[21, 35, 37]和梯度网格[31]。深度学习的兴起激励研究人员通过可微分渲染来解决矢量化问题。Yang等人[36]提出,贝齐根可以通过自定义损失函数直接优化,通过使用小波光栅化[18]计算梯度。Li等人[14]通过对Reynolds传输定理[26]的公式进行微分,并使用Monta-Carlo边缘采样来找到形状梯度。同时,将可微分渲染技术与深度学习模型相结合是一个热门的研究方向。基于循环神经网络[10]、变分自编码器[10, 17]和变换器[27]的新网络被引入来解决矢量化和矢量图形生成问题。在[10]中,Ha等人介绍了SketchRNN,这是第一个基于RNN的草图生成网络。在[17]中,Lopes等人介绍了一个SVG解码器,并将其与像素VAE结合,以在潜在空间中生成新的字体SVGs。在[27]中,Rebeiro等人提出了Sketchformer,这是一个基于变换器的网络,可以从光栅图像中恢复草图。
2.2 图像拓扑
一个可编辑的SVG应该在对象和形状上组织良好。先前的工作已经探索了光栅图像和矢量化形状的这种图像拓扑。一个原型工作是Photo2ClipArt[8],在那里图像首先被分割成段,然后被矢量化,最后组合以形成视觉层次。类似的设计在其他研究工作中反复出现,如[30, 29]。然而,这些方法在很大程度上依赖于分割步骤的准确性,并且在恢复复杂场景的隐式形状几何形状方面显得笨拙。另一个研究分支设计了端到端框架,通过一次前向传递生成或编辑图像层次结构。例如,DeepSVG[3]使用VAE作为其主要结构,其中输入笔画首先通过编码器表示,然后通过解码器替换为重采样的笔画。然而,DeepSVG执行SVG到SVG的转换,这是一个相对简单的任务。风格化神经绘画[38]逐步重建图像,以风格化的笔画。他们的设计原则是贪婪搜索最佳笔画以最小化损失。然而,他们的主要焦点是光栅图像,而不是SVG。最后,Im2Vec[24]提出了Encoder-RNN-Rasterizer管道来矢量化图像并同时获得其拓扑结构。然而,生成形状的顺序并不稳健,该方法是特定领域的。与上述方法不同,我们的LIVE不需要预分割,也不需要深度模型,但显示出令人满意的探索图像拓扑的能力。
3 LIVE:分层图像矢量化
3.1 框架
我们提出了一种新的方法,以分层方式逐步生成与光栅图像拟合的SVG。给定任意输入图像,LIVE通过递归学习视觉概念,通过添加新的可优化闭合贝塞尔路径并优化所有这些路径。虽然各种形状基元都可以添加到SVG中,但我们考虑参数化闭合贝塞尔路径作为我们的基本形状基元,如在[24, 14]中的实现。有几个原因支持这一设置。首先,这种策略将大大减少LIVE学习过程的设计空间,并显著简化学习过程。此外,贝塞尔路径功能强大且易于逼近各种形状,这使得没有必要引入各种形状基元。最后,我们可以通过改变每个路径中的段数s来方便地控制形状复杂度。对于复杂的视觉概念,我们可以轻松增加段数以更好地重建输入,反之亦然。请注意,渲染操作通常是不可微的,这使得直接在仅有的目标光栅图像监督下优化路径变得困难。为了应对这一困境,我们利用了[14]中可微分渲染器的优势。
算法1显示了整个流程。简而言之,我们首先引入了一个组件级初始化方法,选择主要组件作为初始化点。然后我们运行一个递归流程,逐步根据路径数调度序列ℕ添加n条路径。在每一步中,我们基于一些新提出的目标函数优化图形,包括基于无符号距离的焦距(UDF)损失和自交叉(Xing)损失,以获得更好的重建质量和自交叉问题的优化结果。除了分层表示能力外,我们的方法还能够使用最小数量的贝塞尔路径重建图像,与其它方法相比,显著减少了SVG文件大小。更多细节将在以下章节中介绍。
Algorithm: LIVE
Output: Scalable Vector Graphic (SVG) containing paths P and colors C
1. Initialize:
P = [] // List of path control points
C = [] // List of path colors
w = 1.0 // Pixel-wise loss weight
α, β = 1.0, 0.01 // Learning rates
2. For n in ℕ:
a. Generate new points p ∈ ℝ^(n×4) and new colors c ∈ ℝ^(n×4)
b. Initialize p and c:
p, c = init(n, w)
c. Concatenate new points and colors to existing lists:
P = concat([P; p])
C = concat([C; c])
d. For j = 1 to t:
i. Render the image from paths and colors:
I^ = render(P, C)
ii. Compute the loss:
L = L_UDF(I - I^) + λ * L_Xing(P)
iii. Update path control points:
P = P - α * dL/dP
iv. Update colors:
C = C - β * dL/dC
e. Update the pixel-wise loss weight:
w = ||I - I^||^2
3. Output the SVG:
SVG = {P, C}
3.2 组件级路径初始化
我们发现贝塞尔路径的初始化在LIVE中至关重要。一个糟糕的初始化会导致拓扑提取失败并生成冗余形状。为了克服这一缺陷,我们引入了组件级路径初始化,这极大地帮助了优化过程。
组件级路径初始化的设计原则是基于每个组件的颜色和大小来识别路径的最合适的初始位置。一个组件是一个具有统一填充颜色的连接区域。正如我们之前提到的,LIVE是一个渐进式学习流程。给定前一阶段的SVG输出,我们优先考虑下一个学习目标,以便组件既大又缺失。我们通过以下步骤来验证这样的组件:a) 我们计算当前渲染的SVG与真实图像之间的像素级颜色差异。b) 我们拒绝小于预设阈值cα的颜色差异。在我们的论文中,经验上cα=0.1。小于cα的颜色差异被认为是正确渲染的。c) 对于其他区域,我们将所有大于cα的有效颜色差异值均匀量化为200个区间。量化是近似均匀分布的。d) 最后,我们根据量化结果识别最大的连接组件,并使用其质心作为我们下一个路径的初始位置。如果我们想添加K更多路径,那么我们选择前K个组件进行下一阶段的初始化。请注意,对于每个路径,我们考虑圆初始化方法,即所有控制点均匀地初始化在一个圆上[24]。经验上,这个简单的策略有助于简化优化过程,并被证明是有帮助的。
我们组件级路径初始化的优点是它在缺失区域的颜色和大小之间保持了良好的平衡。与DiffVG[14]和Neural Painting[38]不同,前者随机初始化路径,后者基于MSE初始化笔触,我们的方法关注的是与RGB值无关的语义影响组件。在向现有图形添加新路径时,我们的初始化方法总能识别出具有相似颜色的最大缺失组件,并填充主要区域。
3.3 损失函数
3.3.1 用于重建的UDF损失
在之前的工作[14, 24, 25]中,一个常用的损失函数是均方误差(MSE)‖I−I^‖22,其中3代表RGB,w×h代表图像大小。MSE损失简单而高效,但对于图像比较来说,它会偏向整个目标图像的平均颜色,如图2所示。这种现象是因为MSE是使用所有可用像素计算的,而并非所有像素都与优化路径相关。因此,我们鼓励只关注有效的像素并忽略不相关的像素。
为了解决这个问题,我们引入了无符号距离引导的焦点(UDF)损失,它根据每个像素到形状轮廓的距离来区别对待每个像素。直观地说,UDF损失强调靠近轮廓的差异并抑制其他位置的差异。通过这样做,LIVE保护自己免受MSE的平均颜色问题,因此保持了颜色重建的准确性。


图2:顶部线条显示了在学习第一条路径时UDF损失与MSE损失之间的差异。MSE损失偏向于目标图像的平均颜色,而我们的UDF损失则保留了目标形状的颜色。最好在彩色中查看。底部块展示了第一条路径的UDF损失优化过程示例。为了更好地可视化,我们将所有值归一化到[0,1]范围内。较深的颜色(灰色或红色)意味着更高的值。
为了不失一般性,我们假设在单路径的情况下制定我们的UDF损失。我们渲染路径并计算每个像素到路径的有符号距离,表示为di,i∈{1,…,h×w}。然后我们通过以下方式对无符号距离|di|进行阈值化、翻转和归一化:
di′=ReLU(τ−|di|)∑j=1w×hReLU(τ−|dj|),(1)
其中i和j是像素的索引,τ是距离阈值。我们默认将τ设置为10。接下来,我们制定我们的无符号距离引导的焦点损失:
ℒUDF=13∑i=1w×hdi′∑c=13(Ii,c−Îi,c)2,(2)
其中i索引I中的像素,c索引RGB通道。在UDF损失的帮助下,我们能够密切注意路径轮廓,并避免来自内部或远处区域的影响。图2展示了无符号距离引导的焦点损失的学习过程。为了在我们的LIVE框架中支持多路径,我们可以通过对所有路径上的di′取平均值来轻松扩展方程2。
3.3.2 Xing损失用于解决自交互问题
我们注意到,在优化过程中,一些贝塞尔路径可能会发生自交互,导致有害的伪影和不适当的拓扑结构[36, 24]。虽然可能会期望额外的路径可以覆盖这些伪影,但我们强调这会使生成的SVG复杂化,并不能有效地探索底层的拓扑信息。为此,我们引入了自交互(Xing)损失来缓解这个问题。
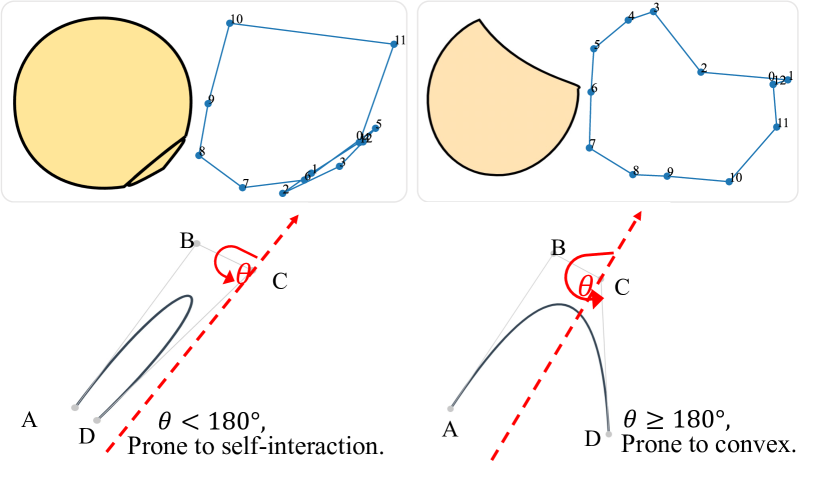
图3:自交互问题的说明。左上角的一对展示了一个带有自交互的圆和其相邻控制点之间的连线。右上角的一对展示了一个没有自交互的形状。底部展示了我们的Xing损失。在一个三次贝塞尔曲线中,我们鼓励第一个(A→B)和最后一个(C→D)控制点连接之间的夹角(θ)大于180°。
假设我们论文中的所有贝塞尔曲线都是三次的,通过分析大量优化后的形状,我们发现一个自交互的路径总是会与其控制点的连线相交,反之亦然。图3展示了示例。这表明,除了优化贝塞尔曲线外,另一种潜在的解决方案是在控制点上添加约束。假设一个三次贝塞尔曲线的控制点按顺序为A、B、C和D,我们添加一个约束,即A→B和C→D之间的夹角(图中的θ)应该大于180°。我们首先通过以下方式确定∠ABC的特性(锐角或钝角)和sin(θ)的值:
D1 = sign(A→B×B→C), D2 = A→B×C→D/||A→B||||C→D||, (3)
其中sign(⋅)是一个符号函数,如果D1>0则返回1,如果D1≤0则返回0,×是向量积,返回一个实数。然后我们将Xing损失公式化为:
L_Xing = D1(ReLU(-D2)) + (1-D1)(ReLU(D2)). (4)
公式4的基本思想是,我们只优化θ<180°的情况(通过ReLU(±D2)实现)。第一个术语是为了D1=1的情况设计的,第二个术语是为了D1=0的情况设计的。结合UDF损失和Xing损失,我们的最终损失函数L由以下公式给出:
L = L_UDF + λL_Xing, (5)
其中λ经验上设置为0.01,以平衡两个损失。

图4:Emoji数据集和Pics数据集的示例。
3.4 数据集
现有的矢量图形数据集[16, 3]主要集中在字体或图标的生成上,但并未探索更广泛的图像领域。此外,也没有可用作评估基准的测试集。在本文中,我们在两个数据集上测试我们的模型,一个是主要从[1]收集的emoji子集的Emoji数据集,另一个是从不同领域收集图像的Pics数据集。图4展示了Emoji和Pics数据集的一些示例。
Emoji 数据集
我们从NotoEmoji项目[1]中收集了134个形状、颜色和组合各异的emoji。虽然该项目提供了各种字体和图标,但我们主要收集了笑脸图像,并将所有收集的图像调整到240×240的分辨率。与[24]中使用的emoji相比,我们的Emoji数据集包含了更多的图像并展示了更多的多样性。由于[1]中的图像相对简单且呈现清晰的拓扑信息,我们主要使用这个数据集来评估层状表示的探索。
Pics 数据集
除了Emoji数据集,我们还引入了Pics数据集,其中包含153个图像,包括字体、图标和复杂的剪贴画图像。与Emoji数据集相比,Pics数据集对图像矢量化来说更加复杂和具有挑战性。此外,Pics数据集中的某些图像具有各种背景,进一步增加了矢量化的难度。我们主要使用这个数据集来检验层状建模和具有更少路径的紧凑SVG。
请注意,我们的LIVE是一个无模型方法,两个数据集仅用于评估。除了这两个数据集,我们还在一些现实照片上评估了LIVE。
3.5 实施细节
我们在PyTorch[22]中实现了LIVE,并使用Adam优化器[12]进行优化,点和颜色优化的学习率分别为1和0.01。在我们的实验中,默认每个路径使用四个段。圆的半径设置为5像素用于圆的初始化。对于每个优化步骤,所有参数都训练500次迭代。由于我们的方法是逐步向画布添加新路径的,因此每一步中的新路径数量是灵活的。考虑到效率和矢量化质量,我们将第i步优化中的路径数量设置为min(2^(i-1), 32)。其他数量设置策略也有效,比如每次添加一个路径或自定义设置。
4 实验

图5:定性重建比较。我们使用不同的路径数量将LIVE与Im2Vec和DiffVG进行比较。我们选择了四条路径(每个图像中的组件数量)和20条路径(Im2Vec中的默认值)进行比较。直观地看,LIVE仅使用四条路径就能实现完美的重建结果,更多的路径并不会降低性能。
4.1矢量化质量
我们首先通过定量和定性分析评估LIVE的矢量化质量,测量输入目标与SVG渲染图像之间的差异。
定性比较。
图5展示了与之前最先进的方法包括DiffVG [14]和Im2Vec [24]的视觉比较。为了公平起见,我们设置了路径数量为4(这些表情符号中的组件数量)和20(Im2Vec中的默认设置)进行评估。显然,我们的LIVE能够实现更忠实的重建,具有更好的组件形状和颜色,而其他方法可能仍然存在其他伪影。因此,所提出的LIVE更好地解耦了不同组件的几何形状。更多结果在补充材料中。
定量结果。
接下来,我们在Emoji和Pics数据集上对矢量化结果进行量化。为了公平比较,路径数量设置为4,这是DiffVG中的默认设置。为了展示LIVE可以用最少的路径重建一个图像,我们从简单的Emoji数据集的8到64条路径,以及复杂的Pics数据集的32到256条路径进行变化。为了比较,我们计算了整个数据集中每张图像的均方误差(MSE)。
Emoji和Pics基准测试的结果报告在图6中。显然,LIVE的MSE比DiffVG低得多,尤其是当路径数量较少时。当只使用少量路径时,LIVE能够拟合所需的形状,从而得到更好的结果。增加过多的路径会饱和矢量化性能。
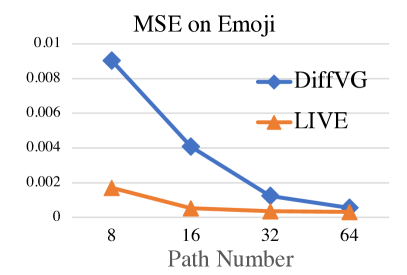
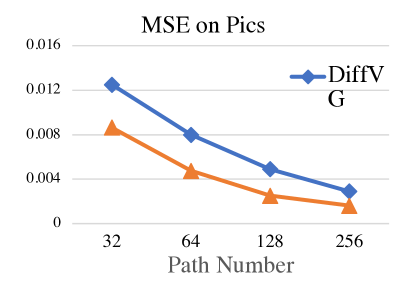
图6:Emoji数据集和Pics数据集上的MSE与路径数量关系图。我们的LIVE在重建结果上比DiffVG表现得更好,尤其是在路径数量较少的情况下。
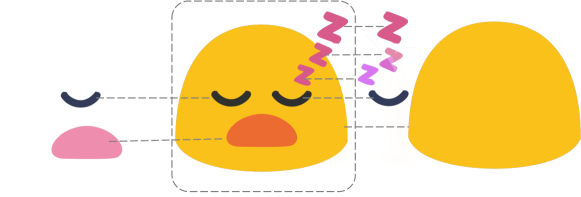

图7:表情符号和剪贴画图像的分层表示图示。当视觉线索易于建模时,LIVE可以直接对每个独立组件进行建模,呈现出合理且清晰的分层表示。

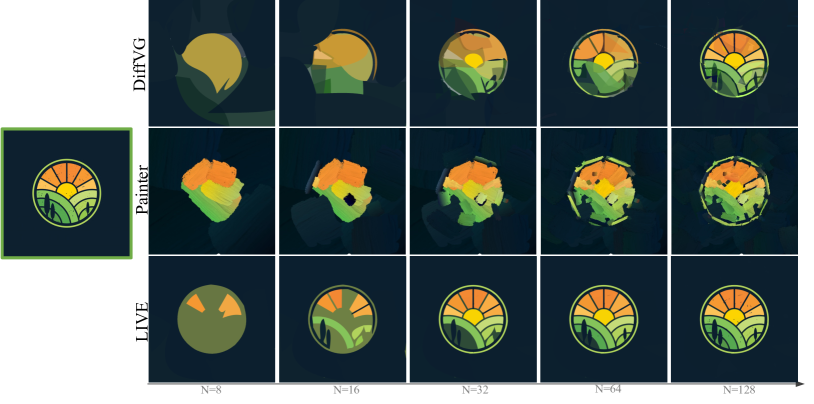
图8:我们展示了DiffVG [14]、Neural Painting [38]和我们的LIVE在不同路径/笔画数量下的结果。这两张图片分别来自Pics数据集和[38]中的测试图像。请注意,Neural Painting不仅设计用于重建。我们仍然与它进行视觉比较,因为它的渐进学习方式与我们的LIVE相似。我们使用红色框来强调差异。请放大查看细节。更多结果将在补充材料中展示。
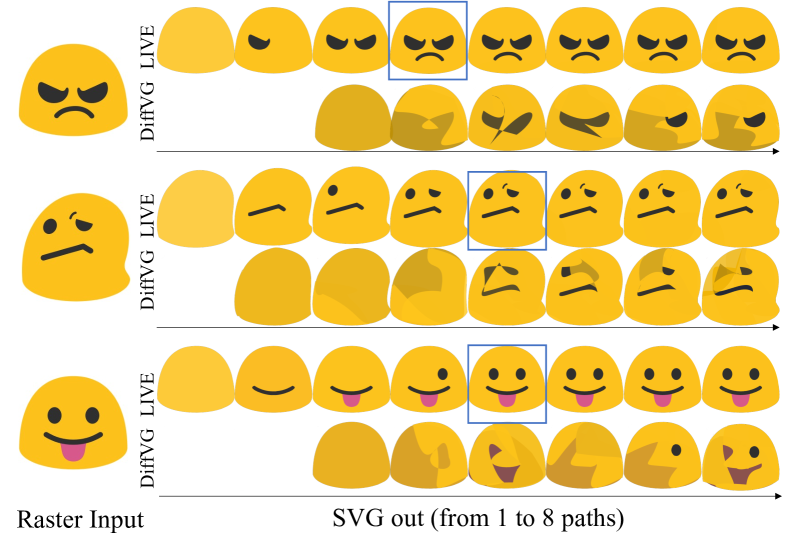
图9:DiffVG和LIVE的矢量化结果。LIVE明确地对每个视觉概念进行了矢量化,没有任何冗余和伪影。蓝色框表示LIVE矢量化了所有概念,增加更多的路径不会损害结果。


图10:两个插值示例。前两行展示了在两个生成的SVG之间线性插值贝塞尔控制点的插值结果。后两行展示了将LIVE与简单的VAE结合的结果。灰色框标记输入的光栅图像。中间的图像表示插值。
4.2 层级表示
除了矢量化质量和效率之外,LIVE的主要目标是构建层级表示。经验上,LIVE能够明确地矢量化每个独立的视觉概念,并探索简单图像(如表情符号和简单剪贴画)的层级表示。我们在图7中展示了LIVE的层级表示能力。如图所示,每个组件都被清晰地学习为一个单独的贝塞尔路径。与那些利用分割预处理或使用大量路径的矢量化方法不同,我们可以将每个组件学习为一个完整的形状。在图9中,我们比较了LIVE和DiffVG在表情符号基准上的矢量化结果。
对于像照片和自然图像这样的复杂图像,拓扑线索相对难以建模。然而,LIVE仍然展示出令人满意的“从粗到细”学习风格的能力,如图8所示。在相同数量的路径下,LIVE更有可能实现更好的重建性能。此外,我们注意到LIVE在局部信息建模方面比其他方法做得更好,如图中的红色框所示。这可能可以用我们的渐进学习和初始化方法来解释。在每一步中,LIVE鼓励新路径去拟合局部细节。虽然之前的路径已经成功重建了主要上下文,但新添加的路径将只关注初始化的局部区域,并通过UDF损失的强制执行。一项全面的用户研究也证明了LIVE的优越性(请参阅补充材料)。
4.3 插值
在现有的矢量化方法中,一些基于VAE的方法探索了插值的应用[24, 3, 16]。尽管我们的LIVE不是基于VAE模型,但我们展示通过与基于光栅图像的VAE模型集成,实现插值是很容易的。
在实现VAE插值之前,我们首先进行了一项有趣的插值实验:给定两个由LIVE生成的语义相似的SVG,我们直接线性插值每个有序路径的控制点。通常,由于形状和控制点的无序,两个SVG很难进行插值。相比之下,我们的LIVE不会受到这个问题的影响,因为优化后的有序拓扑结构。经验上,即使只是简单地线性插值控制点,LIVE仍然呈现出了合理的结果,如图10所示。
接下来,我们将我们的方法与VAE模型集成。我们在MNIST数据集上训练了一个简单的VAE模型。接下来,我们选择了两个随机图像,我们线性插值这两个潜在向量以获得插值图像,并使用我们的LIVE矢量化结果图像序列。为了形成一个连续的序列,我们将前一个结果视为下一个样本的初始化。图10中的结果表明,结合一个普通的VAE模型,我们的方法也适用于插值。鉴于高效的优化方法和出色的泛化能力,当与强大的图像生成模型结合时,LIVE可以更实际地实现插值目标。
4.4 消融研究
圆初始化

图11:不同初始化方法的示例。对于每一对三元组,我们展示了初始化(第一列)、输出(第二列)和细节(第三列)。放大以看得更清楚。
我们首先研究了控制点初始化的有效性。图11比较了圆形初始化和随机初始化。显然,圆形初始化显著减少了与随机初始化相比的伪影。此外,我们注意到圆形初始化更有可能获得更好的矢量化结果,如第一行所示。原因是,通过圆形初始化控制点,闭合路径被强制为凸形,并获得了更精细的优化结果。
Xing Loss。
为了理解所提出的Xing loss的有效性,我们进行了一项消融研究,通过图12的可视化来调查Xing loss的影响。在Xing loss的帮助下,我们清楚地缓解了在相同优化条件下自相交的问题。给定对控制点的约束,圆形形状倾向于不相交。这表明所提出的Xing loss是一个直观、简单但有效的目标函数,用于缓解自相交问题。更多结果将在补充材料中展示。
4.5讨论
局限性和未来工作。
LIVE展示了分层矢量化结果,这可以用于进一步的剪贴画创作或其他应用。然而,仍有一些问题我们可以讨论。首先,分层操作的效率不如单次优化。其他一些方法也存在这个问题[38]。一个有趣的未来研究方向是如何将深度模型的高效推理与基于优化的方法的泛化能力结合起来。其次,引入渐变颜色和为每个片段自适应地选择段数和颜色类型将是值得探索的。第三,对于更复杂的图像,如风景或人物照片,结合分层矢量化与像素空间中的深度模态分割将是一个有趣的主题。我们将这些留给未来的工作。
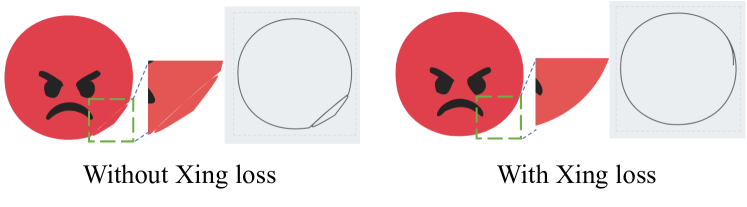
图12:Xing损失效果的图示。每个三元组展示了生成的SVG、细节以及面部的笔触。通过添加Xing损失,我们大大缓解了自交互问题。请放大查看细节。
潜在的负面影响。
图像到矢量技术可能会被非法地在线转换和复制矢量图形资源,特别是那些容易重用和修改的字体或其他图像。为了减轻这些问题,可以通过在光栅图像上使用水印来保护图形的版权。此外,尽管我们的论文实现了图像的合理分层建模,但通过检查每个组件是否足够完整,仍然可以区分从光栅图像转换的结果。这些行动将避免类似算法的滥用。
5 结论
在这项工作中,我们提出了分层图像矢量化(LIVE)框架,该框架使图像矢量化具有分层表示。LIVE通过组件路径初始化和新的损失函数逐步推断输入的光栅图像:一个用于矢量化的UDF损失和一个用于缓解自交互问题的Xing损失。通过LIVE,我们可以明确地矢量化简单表情符号或剪贴画的单个组件,并探索复杂自然图像的“从粗到细”表示。为了简化图像矢量化的评估,我们还提出了两个数据集,Emoji和Pics。除了图像矢量化,LIVE还可以与其他方法结合,探索其他应用,如插值。
附录
附录A 用户研究
我们进行了一项用户研究*,以定量比较我们的LIVE与DiffVG和Neural Painting。我们从emoji和pics数据集中随机选择了21张图片,并邀请了20名用户选择最佳学习处理方法。DiffVG、Neural Painting和我们的LIVE的平均得分分别为14.3%、11.9%和73.8%。结果表明,大多数人认为LIVE能够实现最佳的分层表示。
附录B 更多定性比较
我们还对更多的emoji图片进行了测试,如图13所示。在没有额外修饰的情况下,LIVE明确地解构了视觉概念,其中每个新路径都可以适应输入图像中的特定组成部分。增加更多的路径不会降低性能。

图13:更多层表示的示例。给定一张简单的图像,我们的LIVE能够以分层的方式学习图像中的每个组件。在这里,我们展示了使用8条路径的学习进度,其中每个输出都会将一条新路径附加到之前的输出结果上。
附录 CXing损失权重
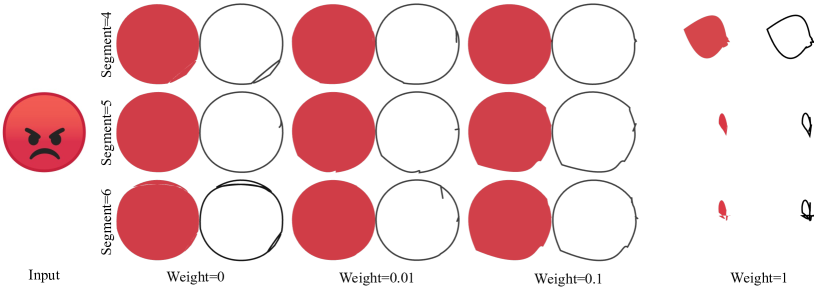
图14:Xing损失权重的影响。我们展示了不同段数下首次生成路径的结果以供说明。每一对中,左边是生成的SVG输出,右边是相应的贝塞尔曲线。
我们在图14中评估了Xing损失的影响。一般来说,增加Xing损失可以大大降低自交互问题的风险。我们注意到,较小的Xing损失权重可以达到最佳结果,而较大的权重(例如1.0)总是导致优化失败。经验上,我们默认将Xing损失权重设置为0.01。
附录D LIVE生成的SVG的有序性
LIVE生成的SVG的一个有趣特性是优化后的贝塞尔路径的确定性顺序,这是由于渐进式学习管道和我们的组件级初始化方法。我们通过线性插值两个生成的SVG来展示这个特性。我们比较了DiffVG(带随机种子)、DiffVG(带固定种子)和我们的LIVE的结果。显然,DiffVG(带随机种子)的插值结果是混乱的,因为路径顺序不是确定的。即使我们固定了所有随机种子,DiffVG的表现仍然不如我们的LIVE。
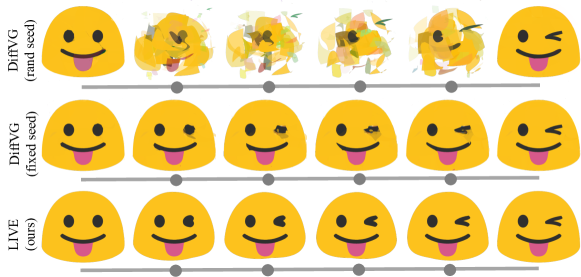
图15:使用DiffVG(随机种子)、DiffVG(固定种子)和我们的LIVE方法线性插值生成的两个SVG图像。
附录E更多插值结果
接下来,我们在图16中展示了更多的插值结果。与仅在两个图像之间进行插值不同,我们进一步在四个随机选择的图像之间插值生成新的图像。从整体上看,图16所示的结果表明,将VAE模型与我们的LIVE方法结合使用可以达到与其他基于VAE的矢量化方法相似的结果。
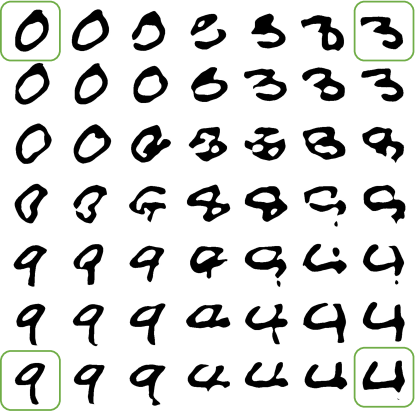
图16:我们绘制了MNIST数据集中四个数字之间的线性插值结果。我们使用绿色方框强调光栅图像。其余所有图像都是由VAE模型和我们的LIVE方法生成的插值SVG图像。
附录F更多矢量化质量
在本节中,我们展示了更多比较我们的LIVE与DiffVG和Neural Painting的例子。结果如下图所示,左侧(绿色方框内)是输入图像,右侧是不同方法的输出。经验上,在相同条件下(即路径/笔画的数量),我们的LIVE可以展现出更好的表示结果,特别是在路径数量较少时。请放大查看细节。


















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









