







DETR基于Transformer将目标检测视为集合预测问题,实现了最先进的性能,但需要超长的训练时间才能收敛。论文研究了DETR优化困难的原因,揭示了收敛缓慢因素主要是匈牙利损失和Transformer交叉注意机制。为了克服这些问题,论文提出了两种解决方案,即TSP-FCOS(基于Transformer的FCOS集合预测)和TSP-RCNN(基于Transformer的RCNN集合预测),不仅收敛速度比原始DETR快得多,检测精度方面也显着优于DETR和其它基线模型来源:晓飞的算法工程笔记 公众号
论文: Rethinking Transformer-based Set Prediction for Object Detection

Introduction
DEtection TRansformer(DETR) 作为第一个完全端到端的目标检测器,可以直接输出最终的预测集。虽然无需进一步的后处理,但需要超长的训练时间才能收敛。Faster RCNN模型只需要大约30个周期即可收敛,而DETR则需要500个周期,在8个V100上至少需要 10 天。因此,论文认为如何加速基于Transformer的DETR类检测器的收敛是一个具有挑战性的研究问题。
为了分析DETR优化困难的原因,论文进行了大量的实验,发现Transformer解码器从图像中获取对象信息的交叉注意模块是收敛缓慢的主要原因。为了追求更快的收敛速度,论文通过删除交叉注意力模块来进一步测试。论文发现仅包含编码器的DETR对小物体的检测有显着的改进,但对大物体的检测性能不佳。此外,论文的分析表明,匈牙利损失中的二分匹配的不稳定性也导致了收敛缓慢。
基于上述分析,论文提出了两种模型来显着加速基于Transformer的集合预测方法的训练,这两种模型都可以被视为具有特征金字塔的仅包含编码器的DETR的改进版本。具体来说,论文提出了TSP-FCOS(Transformer-based Set Prediction with FCOS)和TSP-RCNN(Transformer-based Set Prediction with RCNN),灵感分别来自于经典的一阶段检测器FCOS(全卷积单级目标检测器)和经典的两阶段检测器Faster RCNN。
TSP-FCOS加入了一种新颖的感兴趣特征(FoI)选择机制,帮助Transformer编码器处理多级特征。为了解决匈牙利损失中的二分匹配的不稳定性,论文还为两个模型设计了一个新的二分匹配方案,以加速训练中的收敛。在对COCO 2017检测基准的评估中,论文所提出的方法不仅收敛速度比原始DETR快得多,而且在检测精度方面也显着优于DETR和其他基线。
Background
One-stage and Two-stage Object Detectors
大多数目标检测方法可以分为两类:一阶段检测器和两阶段检测器。典型的一阶段检测器直接根据提取的特征图和图像中的(可变大小的)滑动窗口位置进行预测,而两阶段检测器首先根据滑动窗口位置生成初始区域,然后再细化每个区域的检测结果。
一般来说,两级检测器比一级检测器更准确,但计算成本也更高。然而,这两种检测器都是以检测和合并的方式开发的,都需要后处理步骤来确保每个检测到的对象只有一个区域而不是多个重叠区域作为检测结果。换句话说,许多最先进的目标检测方法没有关于集合预测的端到端训练目标。
DETR with an End-to-end Objective
与上述流行的目标检测器不同,DEtection TRansformer(DETR) 是第一种具有端到端优化目标的方法来进行集合预测的方法,通过二分匹配机制制定损失函数。
对DETR不熟悉的,可以看看之前的文章,【DETR:Facebook提出基于Transformer的目标检测新范式 | ECCV 2020 Oral】
定义
y
=
y
i
u
=
1
M
y={y_i}^M_{u=1}
y=yiu=1M 表示GT对象合集,
y
^
=
y
^
i
u
=
1
N
\hat{y}={\hat{y}_{i}}_{u=1}^{N}
y^=y^iu=1N 表示预测合集。由于
M
<
N
M < N
M<N,所以要用
∅
\emptyset
∅(无对象)将
y
y
y 填充到
N
N
N 的大小,填充后的合集用
y
ˉ
\bar{y}
yˉ 表示。
损失函数(即匈牙利损失)定义为:
$$
\mathcal{L}{\mathrm{Hungarian}}(\bar{y},\hat{y})=\sum{i=1}{N}\left\mathcal{L}_{class}{i,\hat{\sigma}(i)}+\mathbb{1}{{\bar{y}{i}\neq\emptyset}}\mathcal{L}_{b o x}^{i,\hat{\sigma}(i)}\right
\quad\quad (1)
$$
其中
L
c
l
a
s
s
i
,
σ
^
(
i
)
\mathcal{L}_{class}^{i,\hat{\sigma}\left(i\right)}
Lclassi,σ^(i) 和
L
b
o
x
i
,
σ
^
(
i
)
{\mathcal{L}}_{b o x}^{i,{\hat{\sigma}}(i)}
Lboxi,σ^(i) 分别是第
t
t
t 个GT和第
σ
^
(
i
)
{\hat{\sigma}}(i)
σ^(i) 个预测之间的分类损失和边界框回归损失。
σ
^
\hat{\sigma}
σ^ 是填充的GT合集
y
ˉ
\bar{{y}}
yˉ 和预测合集
y
^
\hat{y}
y^ 之间损失值最低的二分匹配:
$$
\hat{\sigma} = \mathop{\arg \min}\limits_{\sigma\in\mathfrak{G}_N}\sum^N_{i=1}\mathcal{L}{\mathrm{match}}(\bar{y}_i,\hat{y}{\sigma(i)})
\quad\quad (2)
$$
其中 G N \mathfrak{G}_N GN 是 N N N 的所有排列的合集, L m a t c h \mathcal{L}_{match} Lmatch 是成对匹配的损失值。
DETR在CNN主干网络的基础上构建Transformer编码器-解码器,消除了NMS后处理的需要。因为自注意力组件可以学习消除重复检测,以及匈牙利损失可以鼓励二分匹配中每个对象一个目标。
在论文工作的同时,已经有一些DETR的变体来提高其训练效率和准确性。与这些工作相比,论文探索使用仅包含编码器的Transformer进一步简化检测头设计。
Improving Ground-truth Assignments
DETR中的匈牙利损失可以视为一种为预测结果分配GT标签的端到端方式。在DETR之前,有一些工作尝试启发式的GT分配规则来完成这项任务,但这些工作并不直接优化基于合集的目标,并且仍然需要NMS后处理步骤。
Attention-based Object Detection
基于注意力建模一直是自然语言处理(NLP)领域的主力,在最近的目标检测研究中也变得越来越流行。在DETR之前,有一些工作尝试将注意力模块插入到经典的检测架构中,取得不错的效果,但这些方法都没有尝试过端到端的集合预测目标。
What Causes the Slow Convergence of DETR?
为了确定收敛慢的主要因素,论文使用DETR及其变体进行了一系列实验,这些实验建立在ResNet-50主干之上,并在COCO 2017验证集上进行了评估。
Does Instability of the Bipartite Matching Affect Convergence?
作为DETR中的一个独特组件,基于二分匹配的匈牙利损失可能由于以下原因而不稳定:
- 二分匹配的初始化本质上是随机的。
- 匹配不稳定可能是由不同训练时期的噪声条件引起的。
为了检查这些因素的影响,论文提出了一种新的DETR训练策略,即匹配蒸馏。使用经过预训练的DETR作为教师模型,将其预测的二分匹配作为学生模型的GT标签分配。教师模型中的所有随机模块(即dropout和批量归一化)都关闭,以确保提供的匹配是确定性的。这消除了二分匹配的随机性和不稳定性,从而保证了匈牙利损失的稳定。
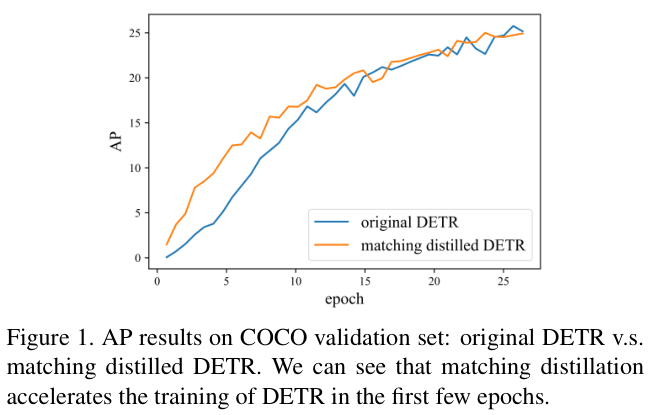
如图 1 所示,通过对比原始DETR和匹配的蒸馏DETR,匹配蒸馏策略确实有助于DETR在前几个时期的收敛,但这种影响在大约15个周期后就变得微不足道。这意味着DETR的二分匹配的不稳定性只是导致收敛缓慢的部分原因(特别是在训练早期),不一定是主要原因。
Are the Attention Modules the Main Cause?
与其他现代目标检测器相比,DETR的另一个独特之处是对Transformer模块的使用,其注意力图在初始化阶段几乎是均匀的,但在收敛的训练过程中逐渐变得越来越稀疏。先前的工作表明,用稀疏模块(例如卷积)替换BERT中的一些注意力头可以显着加速其训练。因此,论文很自然地想知道DETR中注意力模块的稀疏动态对其收敛缓慢有多大贡献。
在分析DETR的注意力模块对其优化收敛的影响时,论文特别关注交叉注意力部分的稀疏性变化。因为交叉注意力模块是解码器中的对象查询从编码器中获取对象信息的关键模块,不精确(优化不足)的交叉注意力可能使得解码器不能从图像中提取准确的上下文信息,从而导致定位不良,尤其是对于小物体。
论文在不同训练时期收集交叉注意力的注意力图来对DETR模型进行评估。由于注意力图可以解释为概率分布,因此论文使用负熵作为稀疏性的直观度量。具体来说,给定一个
n
×
m
n \times m
n×m 注意力图,先通过
1
m
∑
j
=
1
m
P
(
a
i
,
j
)
log
P
(
a
i
,
j
)
\frac{1}{m}\sum_{j=1}^{m}{\cal P}(a_{i,j})\,{\log}{\cal P}(a_{i,j})
m1∑j=1mP(ai,j)logP(ai,j) 计算每个 KaTeX parse error: Undefined control sequence: \inn at position 2: i\̲i̲n̲n̲ 位置的稀疏性,其中
a
i
,
j
a_{i,j}
ai,j 表示从源位置
i
i
i 到目标位置
j
j
j 的注意力分数,然后对每层中所有注意力头和所有源位置的稀疏度进行平均。
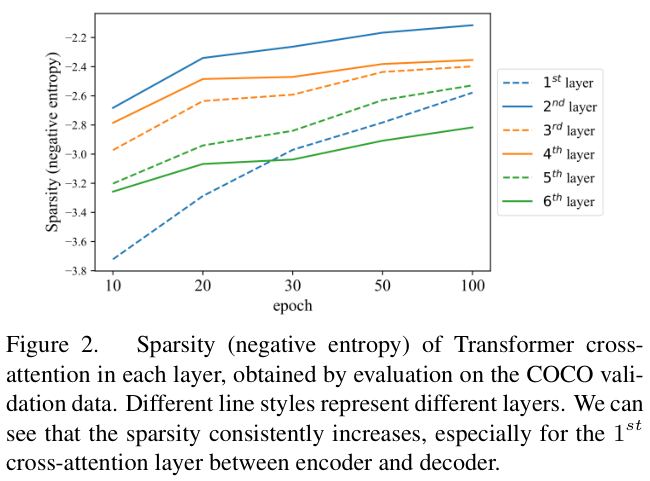
图 2 展示了不同层在不同训练时期的稀疏性,可以看到交叉注意力的稀疏性持续增加,即使在100个训练周期之后也没有达到稳定水平。这意味着,与前面讨论的早期二分匹配不稳定因素相比,DETR的交叉注意力部分才是导致收敛缓慢的主要因素。
Does DETR Really Need Cross-attention?
论文的下一个问题是:能否从DETR中删除交叉注意模块以加快收敛速度,但又不牺牲其在目标检测中的预测能力?论文通过设计仅包含编码器版本的DETR并将其收敛曲线与原始DETR进行比较来回答这个问题。
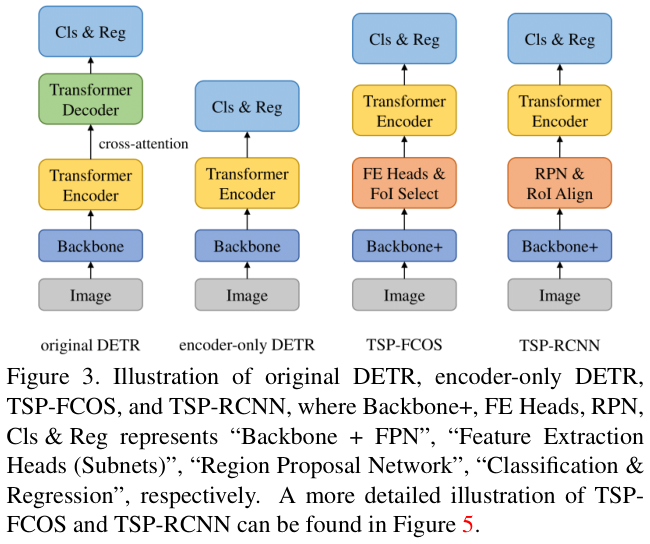
在原始DETR中,解码器负责生成每个对象查询的检测结果(类别标签和边界框)。相比之下,DETR的仅包含编码器版本(由论文推出)直接使用Transformer编码器的输出进行对象预测。具体来说,对于
H
×
W
H\times W
H×W 的图像和
H
32
×
W
32
\frac{H}{32}\times\frac{W}{32}
32H×32W 的编码器特征图,每个特征被输入到检测头以预测检测结果。由于编码器自注意力本质上与非自回归解码器中的自注意力相同,对于仅包含编码器的DETR来说,集合预测训练仍然是可行的。图 3 比较了原始DETR和仅包含编码器的DETR,以及论文新提出的两个模型(TSP-FCOS和TSPRCNN)。
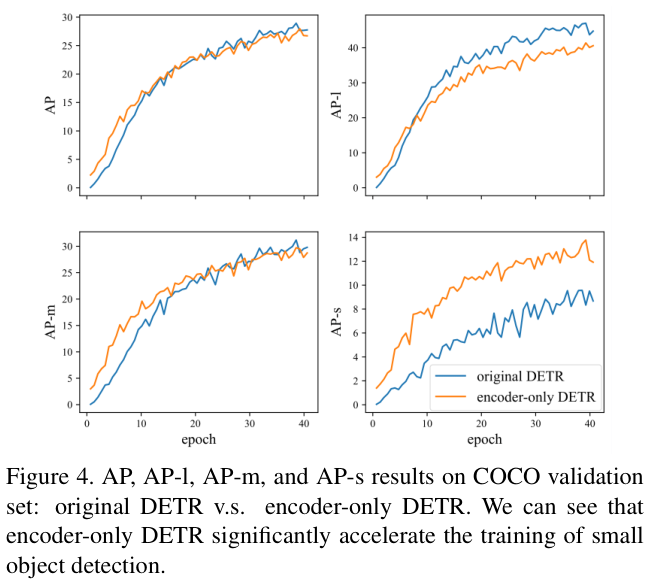
图 4 展示了原始DETR和仅包含编码器的DETR的平均精度(AP)曲线,包括总体AP曲线(记为AP)以及大(AP-l)、中(AP-m)、和小(AP-s)物体的精度曲线。总体曲线(左上角)显示仅包含编码器的DETR的性能与原始DETR一样好,这意味着论文可以从DETR中删除交叉注意力部分,而不会造成太多性能下降,这是一个积极的结果。从剩余的曲线中论文可以看到,仅包含编码器的DETR在小物体上显着优于原始DETR,在中物体上部分优于原始DETR,在大物体上表现不佳。论文认为,一个潜在的解释是大对象可能包含太多潜在可匹配的特征点,这对于仅包含编码器的DETR中的滑动点方案(特征点预测)来说很难处理。另一个可能的原因是编码器处理的单个特征图对于预测不同尺度的对象不具有鲁棒性。
The Proposed Methods
根据上面的分析,为了加速DETR的收敛,论文需要解决二分匹配的不稳定问题和Transformer模块中的交叉注意力问题。具体来说,为了利用仅包含编码器的DETR的加速潜力,论文需要克服其在处理各种尺寸物体方面的弱点。
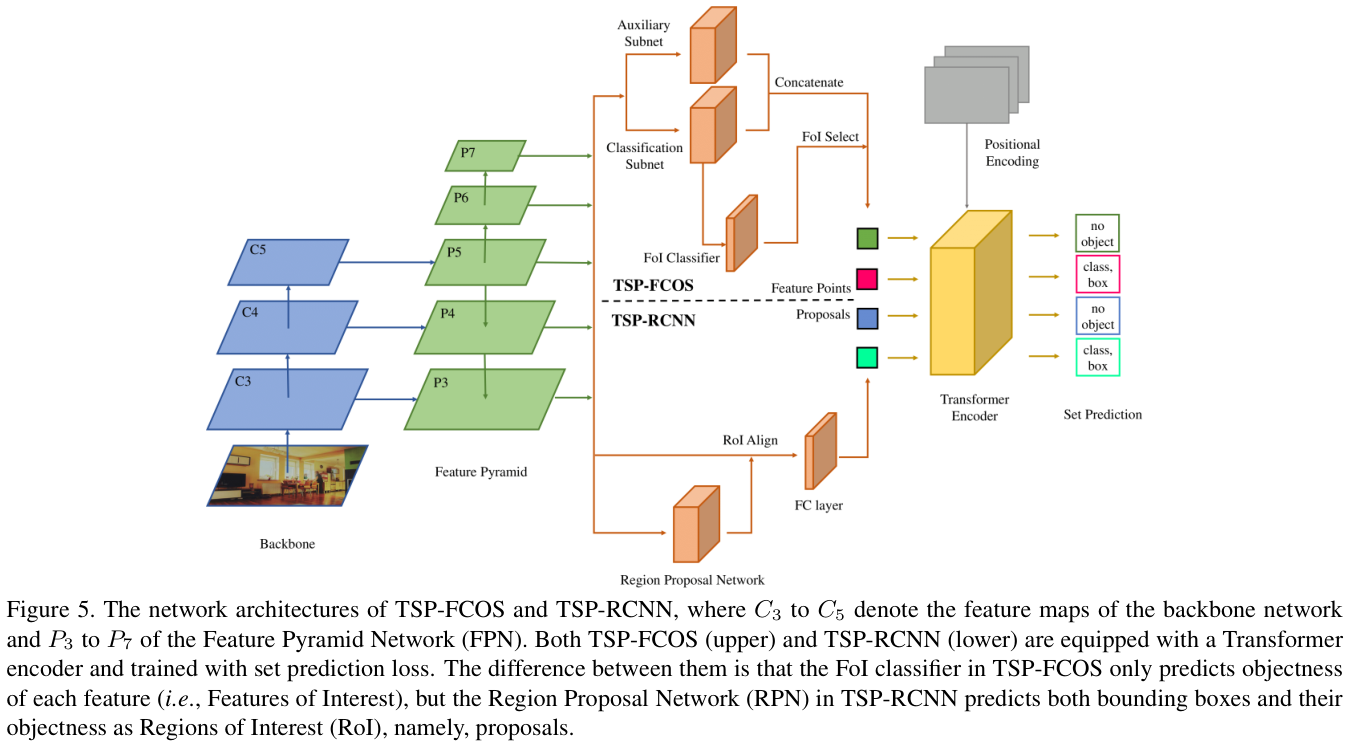
最近,FCOS(全卷积单阶段目标检测器)的成功表明,特征金字塔网络(FPN)的多级预测是解决这个问题的一个很好的方案。受这项工作的启发,论文提出了第一个模型,即基于Transformer的FCOS集合预测(TSP-FCOS)。在TSP-FCOS的基础上,论文进一步加上两阶段架构,提出了第二个模型,即基于Transformer的RCNN集合预测(TSP-RCNN)。
TSP-FCOS
TSP-FCOS结合了FCOS和DETR仅含编码器的的优点,结构如图5(上半部分)。TSP-FCOS具有一个新颖的组件,即Feature of Interest(FOI)选择,使Transformer编码器能够处理多级特征,以及使用新的二分匹配方案以实现更快的集合预测训练。
- Backbone and FPN
TSP-FCOS在主干网络和特征金字塔网络(FPN)的设计上遵循FCOS,使用CNN主干网络从输入图像中提取特征,再基于主干网的特征图构建FPN产生多级特征,帮助仅包含编码器的DETR检测各种尺度的对象。
- Feature extraction subnets
为了与其他阶段检测器(例如FCOS和RetinaNet)进行公平比较,论文遵循他们的设计,在不同的金字塔特征之间共享两个特征提取头。其中之一称为分类子网(头),用于FoI分类。另一个称为辅助子网(头),两个子网的输出被串联起来,然后由FoI分类器进行选择。
- Feature of Interest (FoI) classifier
在Transformer的自注意力模块中,计算复杂度与序列长度成二次方,所以不能直接使用特征金字塔上的所有特征。为了提高自注意力的效率,论文设计了一个二元分类器来选择有限的部分特征,并将它们称为感兴趣的特征(FoI)。二元FoI分类器使用FCOS的GT分配规则进行训练,经过分类后,得分最高的特征被选为FoI并输入Transformer编码器。
- Transformer encoder
在FoI选择之后,Transformer编码器的输入是一组FoI及其相应的位置编码,Transformer编码器的每一层都会通过自注意力来聚合不同FoI的信息。编码器的输出通过共享前馈网络预测每个FoI的类别标签(包括“无对象”)和边界框。
- Positional encoding
遵循DETR的设计,将Transformer的位置编码推广到2D图像场景。对于具有归一化位置
(
x
,
y
)
∈
0
,
1
2
(x,y)\in\ 0,1^{2}
(x,y)∈ 0,12 的特征点,其位置编码定义为
P
E
(
x
)
:
P
E
(
y
)
P E(x):P E(y)
PE(x):PE(y) ,其中
:
:
: 代表串联,函数
P
E
PE
PE 定义为:
$$
\begin{array}{c}
PE(x){2i}={\sin}(x/10000^{2i/d{model}})
\
PE(x){2i+1}={\sin}(x/10000^{2i/d{model}})
\end{array}
\quad\quad (3)
$$
其中
d
_
m
o
d
e
l
d\_{model}
d_model 是FoI的维度。
- Faster set prediction training
给定一组检测结果和GT对象,集合预测损失将它们连接在一起,为模型优化提供一个目标。由于匈牙利二分匹配损失可能会导致训练早期阶段收敛缓慢,论文设计了一种新的二分匹配方案来更快地训练TSP-FCOS的集合预测。
受FCOS的GT分配规则的启发,只有当特征点位于对象的边界框中并且处于恰当的特征金字塔级别时,才能将特征点分配给GT对象。接下来,执行公式 2 的匹配以确定检测结果与GT对象在公式 1 的匈牙利损失中的最佳匹配。
TSP-RCNN
基于TSP-FCOS和Faster RCNN的设计,结合它们的优点进行两阶段边界框细化作为集合预测,这需要更多的计算资源,但可以更准确地检测目标。这个想法催生了TSP-RCNN(基于Transformer的RCNN集合预测),网络架构如图 5(下半部分)。
TSP-FCOS和TSP-RCNN的主要区别如下:
- Region proposal network
在TSP-RCNN中,没有使用两个特征提取头和FoI分类器来产生Transformer编码器的输入,而是遵循Faster RCNN的设计,使用区域提议网络 (RPN) 来获取一组感兴趣区域 (RoI)来进一步细化。与TSP-FCOS中的FoI不同,TSP-RCNN中的每个RoI不仅包含目标分数,还包含预测的边界框。论文应用RoIAlign从多级特征图中提取RoI信息,特征被扁平化后经过全连接的网络的处理作为Transformer编码器的输入。
- Positional encoding
RoI(提案)的位置信息由四个标量
(
c
x
,
c
y
,
w
,
h
)
(cx,c y,w,h)
(cx,cy,w,h) 定义,其中
(
c
x
,
c
y
)
∈
0
,
1
2
(cx, cy) \in 0,1^{2}
(cx,cy)∈0,12 表示归一化中心坐标,
(
w
,
h
)
∈
0
,
1
2
(w,h)\in0,1^{2}
(w,h)∈0,12 表示归一化高度和宽度。论文使用
P
E
(
c
x
)
:
P
E
(
c
y
)
:
P
E
(
w
)
:
P
E
(
h
)
P E(c x):P E(c y):P E(w):{P}E(h)
PE(cx):PE(cy):PE(w):PE(h) 作为提案的位置编码,其中
P
E
PE
PE 和
:
:
: 的定义方式与RoI相同。
- Faster set prediction training
TSP-RCNN也使用集合预测损失进行训练。与TSP-FCOS不同,论文借用Faster RCNN的GT分配规则来进行更快的集合预测训练。具体来说,当且仅当边界框之间的交并(IoU)分数大于0.5时,才可以将提案分配给真实对象。
Experiments
Implementation Details
- TSP-FCOS
在FCOS之后,分类子网和辅助子网都使用四个具有 256 个通道和组归一化的
3
×
3
3\times3
3×3 卷积层。在FoI选择中,从FoI分类器中选择前700个评分特征位置作为Transformer编码器的输入。
- TSP-RCNN
与原始的Faster RCNN不同,论文将 2 个非共享的卷积子网应用于
P
3
−
P
7
P_{3}{\mathrm{-}}P_{7}
P3−P7 作为RPN的分类和回归头,使用RetinaNet风格的锚框生成方案。论文发现这提高了RPN的性能,同时减少了计算开销。在RoI选择中,论文从RPN中选择得分最高的 700 个特征。应用RoI对齐操作和全连接层从RoI中提取建议特征。
- Transformer encoder
由于TSP-FCOS和TSPRNN都只有编码器,而DETR有Transformer编码器和解码器。为了能在FLOP方面与DETR-DC5进行比较,使用具有8个注意力头的宽度为512的6层Transformer编码器,其中前馈网络(FFN)的隐藏大小设置为2048。在训练过程中,论文随机丢弃编码器的70%输入,以提高集合预测的鲁棒性。
- Training
论文遵循Detectron2的默认设置,其中使用具有多尺度训练时间增强的36周期 (
3
×
3\times
3×)设置。
Main Results
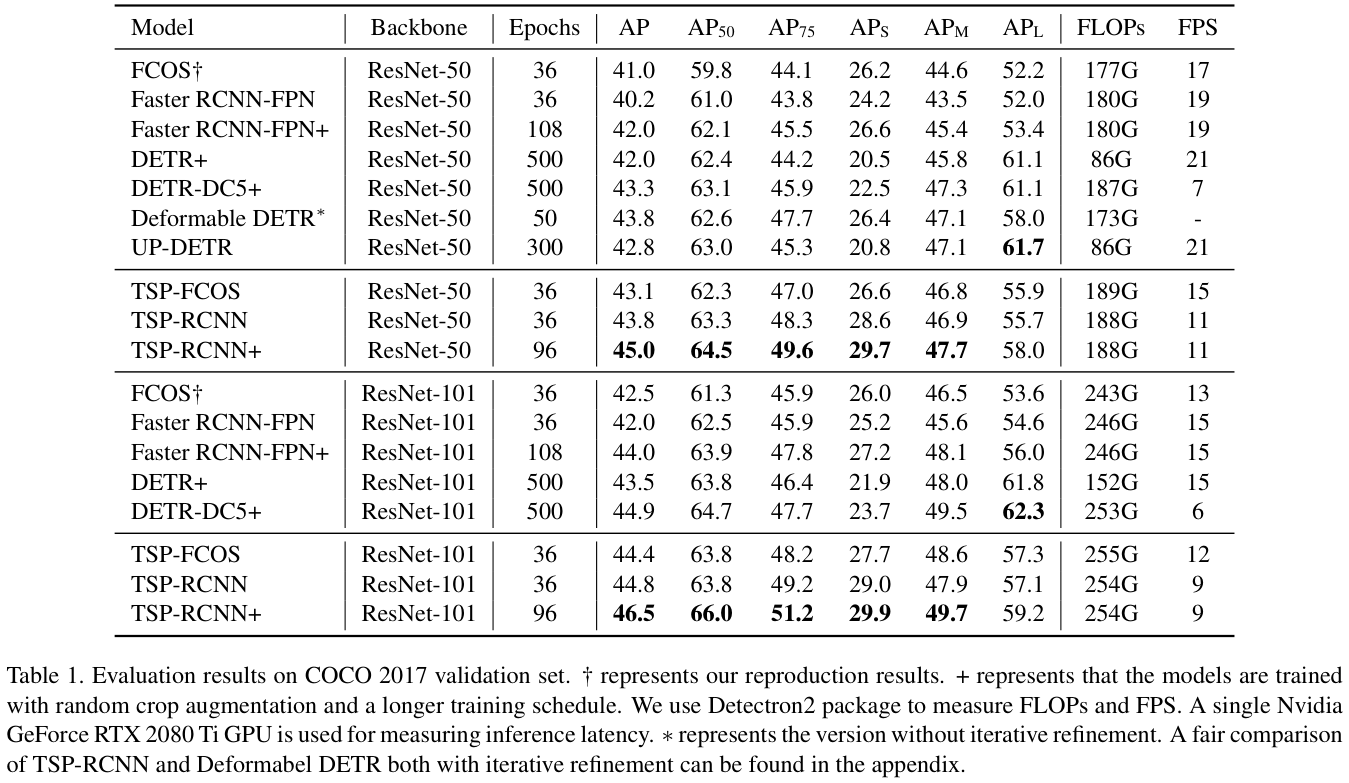
表 1 展示了在COCO 2017验证集上的主要结果,TSP-FCOS和TSP-RCNN明显优于原始FCOS和Faster RCNN,而且TSP-RCNN在整体性能和小目标检测方面优于TSP-FCOS,但在推理延迟方面稍差。
为了与最先进的DETR模型进行比较,论文在DETR中使用类似的训练策略,其中应用了96周期(
8
×
8\times
8×)训练设置和随机裁剪增强。用TSP-RCNN+ 表示TSP-RCNN的增强版本,还复制了增强型Faster RCNN(即Faster RCNN+)的结果。比较这些模型,TSP-RCNN获得了最先进的结果,但TSP-RCNN+在大物体检测上仍然不如DETR-DC5+,可能是因为DETR使用的编码器-解码器方案的归纳偏差及其较长的训练设置。
Model Analysis
对于模型分析,论文评估了在默认设置下训练的几个模型,即使用36周期(
3
×
3\times
3×)设置并且没有随机裁剪增强。
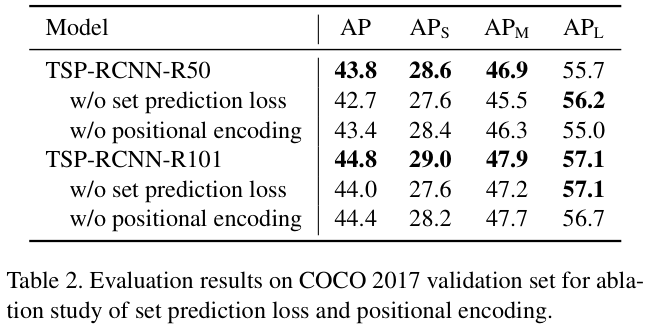
表 2 展示了使用ResNet-50和ResNet-101作为主干网络的TSP-RCNN的消融研究结果。集合预测损失和位置编码对于TSP机制都非常重要,而集合预测损失对TSP-RCNN的改进贡献大于位置编码。
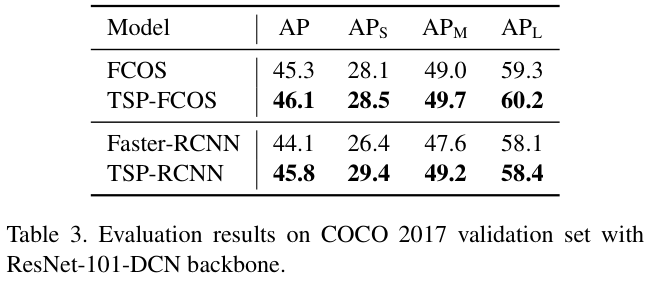
表 3 展示了将TSP-FCOS和TSP-RCNN与可变形ResNet-101作为主干网络的FCOS和Faster RCNN进行比较。从结果中论文可以看出,TSP机制与可变形卷积有很好的互补性。
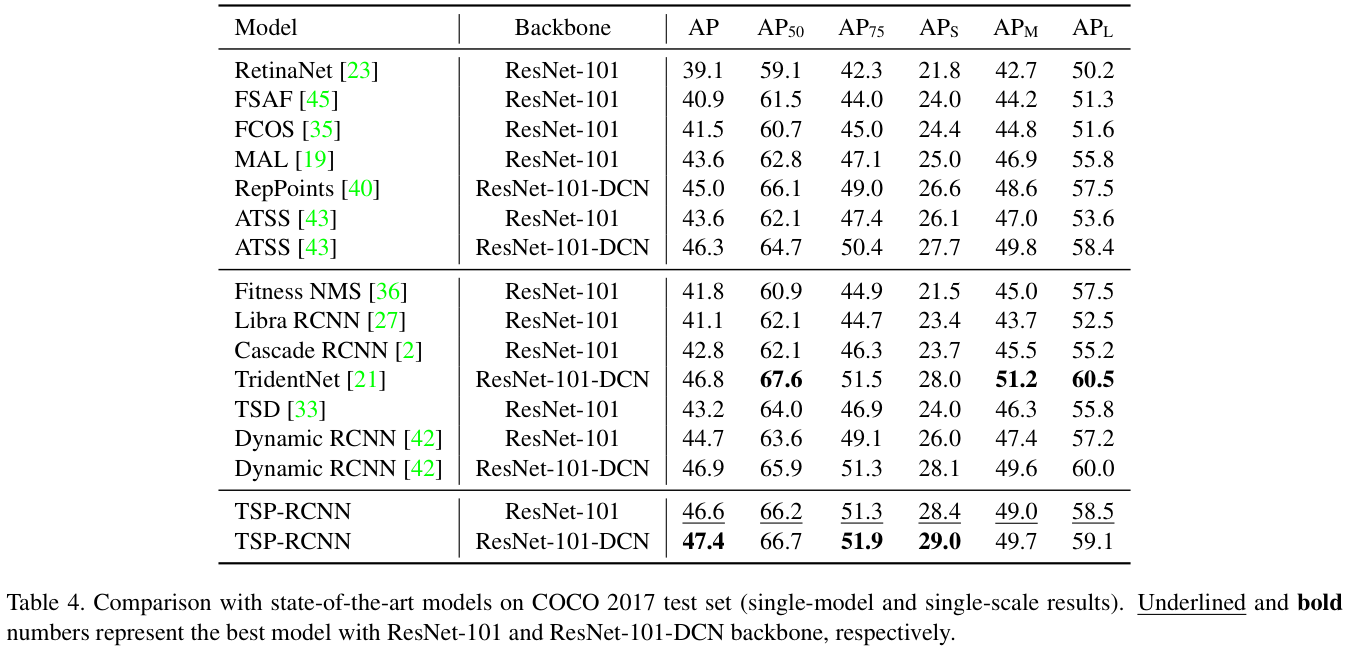
表 4 展示了TSP-RCNN与多个检测模型进行比较,这些模型也使用ResNet-101或可变形卷积网络(DCN)变体作为主干网络,使用
8
×
8\times
8× 周期和随机裁剪增强。
Analysis of convergence
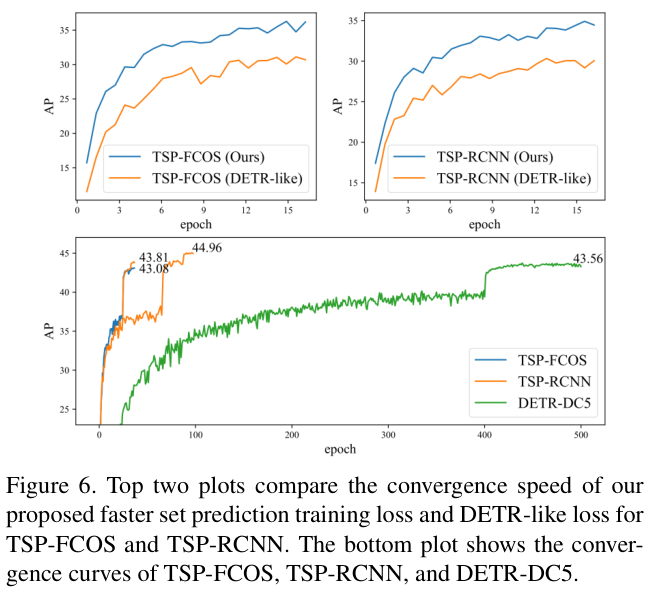
图 6 的上半部分比较了更快的集合预测训练和DETR的原始集合预测训练的收敛速度,论文提出的更快的训练技术一致地加速了TSP-FCOS和TSP-RCNN的收敛。
图 6 的下半部分绘制了TSP-FCOS、TSPRCNN和DETR-DC5的收敛曲线,论文提出的模型不仅收敛得更快,而且实现了更好的检测性能。
如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









