







DETR能够消除物体检测中许多手工设计组件的需求,同时展示良好的性能。但由于注意力模块在处理图像特征图方面的限制,DETR存在收敛速度慢和特征分辨率有限的问题。为了缓解这些问题,论文提出了Deformable DETR,其注意力模块仅关注参考点周围的一小组关键采样点,通过更少的训练次数实现比DETR更好的性能来源:晓飞的算法工程笔记 公众号
论文: Deformable DETR: Deformable Transformers for End-to-End Object Detection

Introduction
现代物体检测器采用许多手工制作的组件,例如锚点生成、基于规则的训练目标分配、非极大值抑制 (NMS) 后处理,导致其并不是完全端到端的。DETR的提出消除了对此类手工制作组件的需求,并构建了第一个完全端到端的物体检测器。DETR采用简单的架构,结合卷积神经网络 (CNN) 和Transformer编码器-解码器,利用Transformer的多功能且强大的关系建模功能,达到了很不错的性能。
尽管DETR具有有趣的设计和良好的性能,但它也有自己的问题:(1)需要更长的训练周期才能收敛。(2)DETR在检测小物体方面的性能相对较低,没有利用多尺度特征。
上述问题主要归因于Transformer组件在处理图像特征图方面的缺陷。在初始化时,注意力模块将几乎统一的注意力权重投射到特征图中的所有像素。长时间的训练对于注意力权重学习如何关注稀疏的有意义的位置是必要的。另一方面,Transformer编码器中的注意力权重计算与像素成二次计算度。因此,处理高分辨率特征图的计算和存储复杂度非常高。
在图像领域,可变形卷积是处理稀疏空间位置的强大而有效的机制,自然就避免了上述问题。但它缺乏元素关系建模机制,而这正是DETR成功的关键。
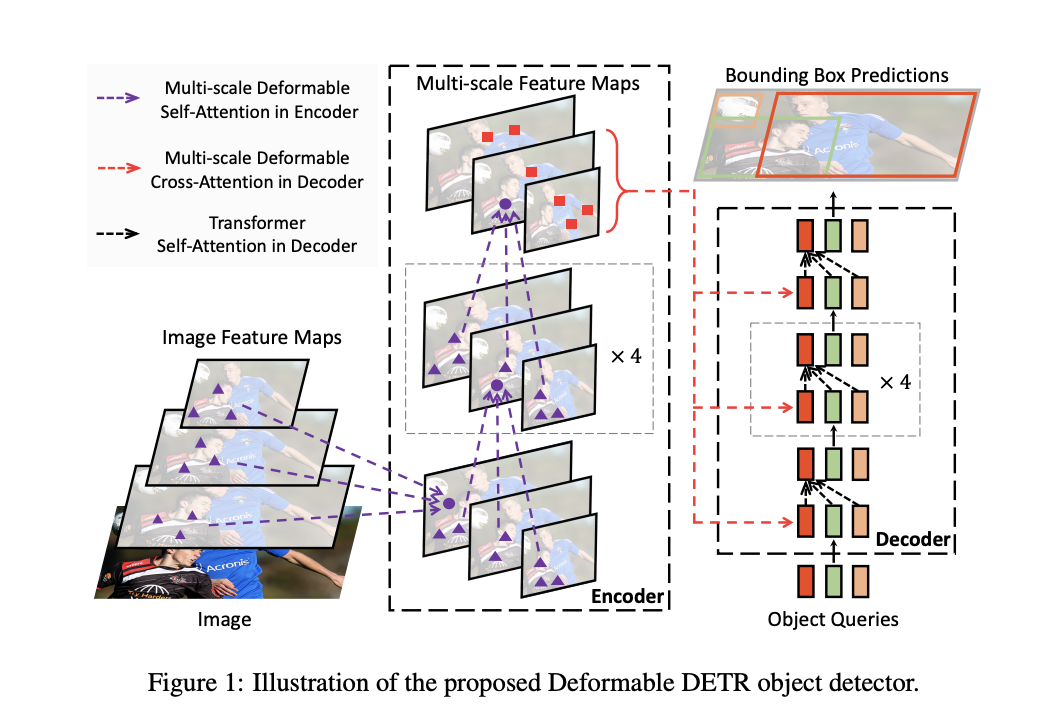
在本文中,论文提出了Deformable DETR,结合可变形卷积的稀疏空间采样和Transformers的关系建模能力,缓解了DETR收敛速度慢和计算复杂度高的问题。可变形注意模块仅关注一小组采样位置,相当于所有特征图像素中突出关键元素的预过滤器。该模块可以自然地扩展到多尺度特征架构,而无需FPN的帮助。在Deformable DETR中,论文利用(多尺度)可变形注意力模块来代替处理特征图的Transformer注意力模块,如图 1 所示。
Revisiting Transformers and DETR
Multi-Head Attention in Transformers.
定义 q ∈ Ω q q\in\Omega_{q} q∈Ωq 为查询元素下标,索引特征 z q ∈ R C {z}_{q}\in {\mathbb{R}}^C zq∈RC , k ∈ Ω k k\in\Omega_{k} k∈Ωk 为键元素下标,索引特征 x _ k ∈ R C x\_k \in \mathbb{R}^C x_k∈RC, C {C} C 是特征维度, Ω q \Omega_{q} Ωq 和 Ω _ k \Omega\_{k} Ω_k 分别为查询元素和键元素的集合。
多头注意力特征的计算可表示为:
$$
\mathrm{MultiHeadAttn}(z_{q},x)=\sum_{m=1}^{M}W_{m}[\sum_{k\in\Omega_{k}}A_{m q k}\cdot W_{m}^{\prime}x_{k}],
\quad\quad (1)
$$
其中 m m m 为注意力头下标, W m ′ ∈ R C v × C W_{m}^{\prime}\in\mathbb{R}^{C_{v}\times C} Wm′∈RCv×C 和 W m ∈ R C × C v W_{m}\in{\mathbb{R}^{ {C}\times C_{v}}} Wm∈RC×Cv 为可学习的权重(默认 C v = C / M {C}_{v}=C/M Cv=C/M)。注意力权重 A m q k ∝ e x p { z q T U m T V m x k C v } A_{m q k}\propto{exp}\lbrace\frac{z_{q}^{T}\,U_{m}^{T}\,\,V_{m}\,x_{k}}{\sqrt{C_{v}}}\rbrace Amqk∝exp{ CvzqTUmT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









