







论文提出一种新颖的
POA自监督学习范式,通过弹性分支设计允许同时对多种尺寸的模型进行预训练。POA可以直接从预训练teacher生成不同尺寸的模型,并且这些模型可以直接用于下游任务而无需额外的预训练。这个优势显著提高了部署灵活性,并有助于预训练的模型在各种视觉任务中取得SOTA结果。来源:晓飞的算法工程笔记 公众号
论文: POA: Pre-training Once for Models of All Sizes

Abstract
大规模自监督预训练为一个基础模型处理多种不同的视觉任务铺平了道路。大多数预训练方法在一次训练中训练一个特定大小的单一模型。然而,在现实世界的场景中,由于各种计算或存储限制,需要大量的工作来开发一系列不同大小的模型进行部署。因此,在这项研究中,我们提出了一种新颖的三分支自监督训练框架,称为POA(Pre-training Once for All),来解决上述问题。我们的方法在现代自蒸馏范式中引入了一种创新的弹性student分支。在每个预训练步骤中,我们随机从原始student中抽样一个子网络来形成弹性student,并以自蒸馏的方式训练所有分支。一旦预训练完成,POA允许提取不同大小的预训练模型用于下游任务。值得注意的是,弹性student促进了多个不同大小模型的同时预训练,同时也作为各种大小模型的额外集合,增强了表示学习。大量实验证明了我们的POA的有效性和优势,包括k最近邻、线性探测评估以及多个下游任务的评估。它使用ViT、Swin Transformer和ResNet骨干网络实现了最先进的性能,并通过一次预训练会话生成了大约一百个不同大小的模型。代码可在以下链接找到:https😕/github.com/Qichuzyy/POA。
Introduction
通过自监督学习在大型模型中学习可泛化的视觉表示,近年来在各种视觉任务上取得了卓越的性能。然而,当部署到现实世界的应用程序时,大型模型必须根据计算、存储、功耗等各种资源限制进行调整。例如,一个良好设计的人工智能产品通常包括一套为不同场景量身定制的模型,比如Gemini Nano、Pro和Ultra。对于一个大型预训练模型,将其部署到具有不同资源约束的多个应用场景的常见解决方案包括额外的权重修剪、知识蒸馏,甚至从头开始重新训练一个小网络,这些都需要大量的开发工作。因此,这个问题引发了一个关键问题:是否可能进行一次预训练以同时生成多个具有不同大小的模型,每个模型都提供足够好的表示。
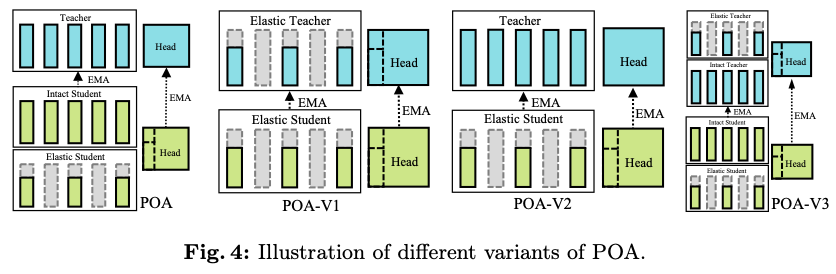
为了解决这一挑战,论文引入了一种名为POA(Pre-training Once for All)的新型自监督学习范式。POA建立在流行的teacher-student自蒸馏框架之上,具有一个额外的创新性弹性student分支。弹性student分支通过参数共享嵌入了一系列子网络,这是基于观察到对于现代网络结构来说,较小尺寸的模型是较大尺寸模型的子网络。此外,该分支的参数与原始的或完整的studennt共享。在每个预训练步骤中,从完整student中随机抽样一部分参数,形成相应的弹性studennt。原始完整student和弹性student都被训练以模拟teacher网络的输出。teacher本身通过对student参数的指数移动平均(EMA)不断优化,包括采样的弹性student。弹性student有助于在不同参数子集上进行有效和高效的预训练,从而成功地从预训练teacher中提取出高性能子网络,用于后续的下游场景。它还作为一种训练正则化形式,通过强制teacher和各种子网络之间的输出匹配来促进稳定的训练过程。
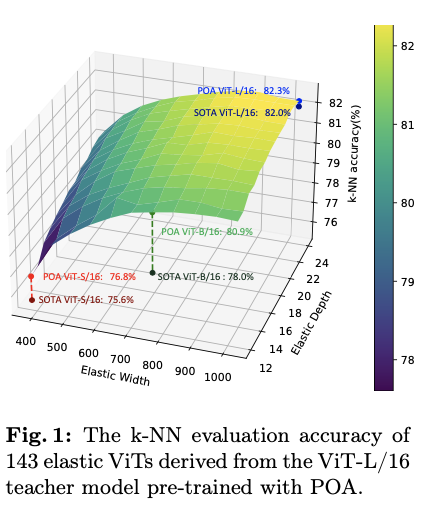
POA代表了第一个能够同时训练多个不同尺寸模型的自监督学习方法,每个模型在不需要进一步预训练的情况下,都能获得适用于不同资源约束的高质量表示。图1显示了通过POA预训练的ViT-L模型提取的143个子网络的k最近邻(k-NN)评估结果。通过选择不同的弹性宽度和深度,预训练teacher模型可以根据可用计算资源定制的适用于下游应用的合适模型,生成足够数量的候选子网络以供选择。值得注意的是,由于在同视图蒸馏上进行了精心设计,每个子网络都经过了良好训练,并表现出优越性能。特别是,ViT-S、ViT-B和ViT-L模型创造了新的基准,与那些由现有方法预训练的模型相比取得了SOTA结果。
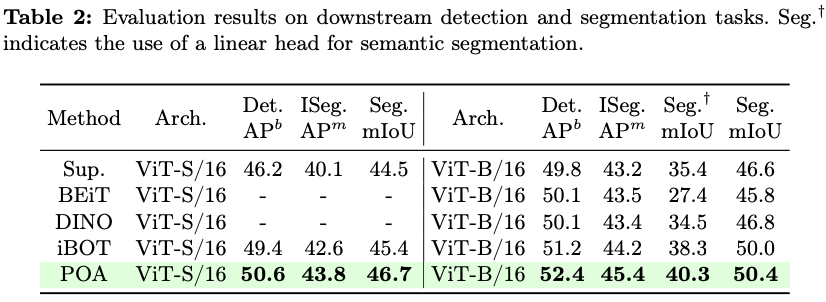
为了严格评估方法的有效性,使用三种广泛使用的骨干架构,即ViT、Swin Transformer和ResNet,进行了大量实验。每个骨干架构都在ImageNet-1K数据集上进行了预训练,并使用k-NN和线性探测分类评估,以及在下游密集预测任务进行评估,如目标检测和语义分割。POA在单次预训练会话中跨多种模型尺寸实现了最先进的准确性。
本文的技术贡献总结如下:
POA是第一个将无监督表示学习和一次性模型生成集成到单个预训练会话中的预训练范式,解决了社区很少探讨的一次性预训练挑战。这对实际部署非常重要,因为实际部署通常需要一套模型。- 提出了一个新颖而优雅的组件,称为弹性
student(Elastic Student),具有一系列弹性算子,可以使POA与包括ViT、Swin Transformer和ResNet在内的流行骨干结构兼容,具备生成各种大小模型的能力。此外,还作为模型集成来平滑训练过程并改善学到的表示。 - 通过对
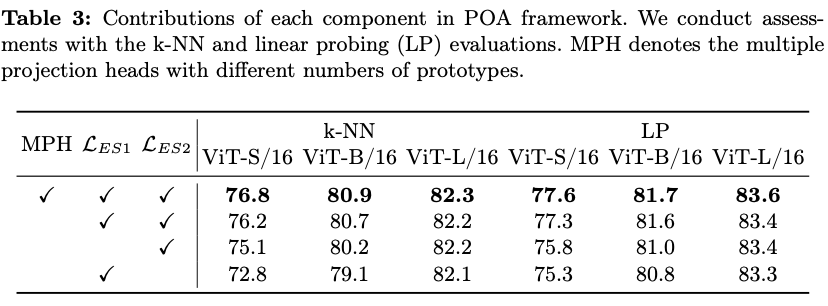
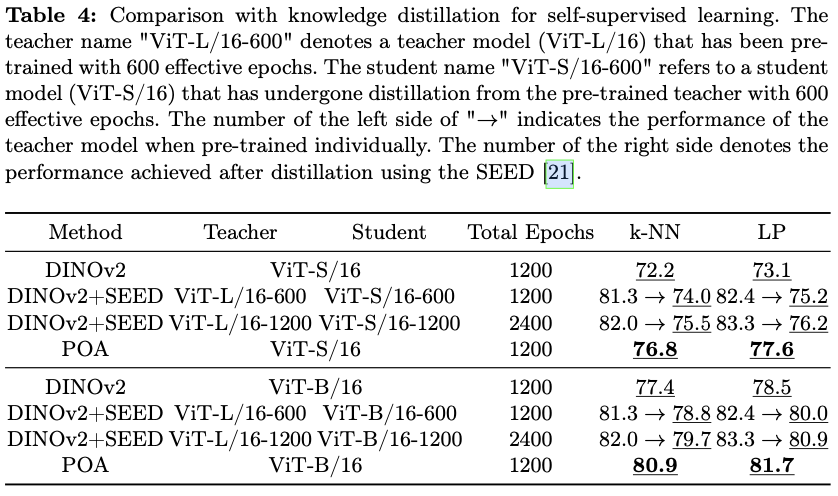
k-NN、线性探测和下游密集任务评估的彻底评估,在多个指标上展现出优于现有最先进预训练方法的性能。此外,将POA与自监督蒸馏(SEED)进行了比较,SEED是一种专为自监督学习设计的知识蒸馏方法,进一步验证了POA的有效性。
POA Self-supervised Learning Framework
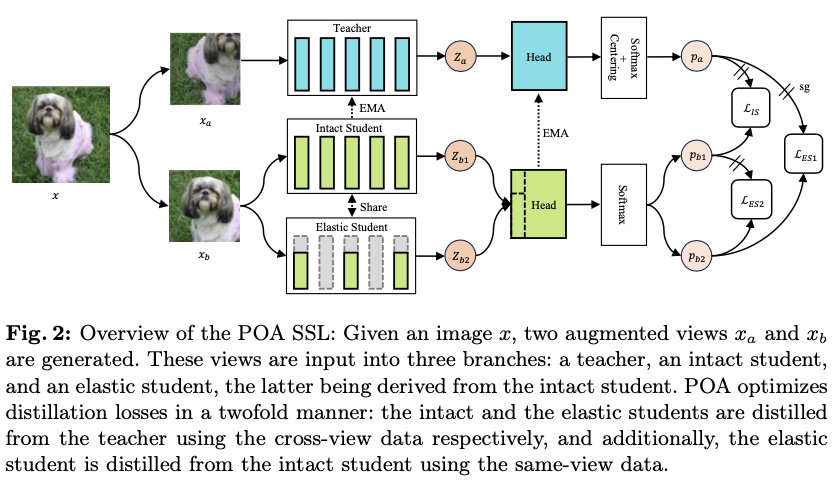
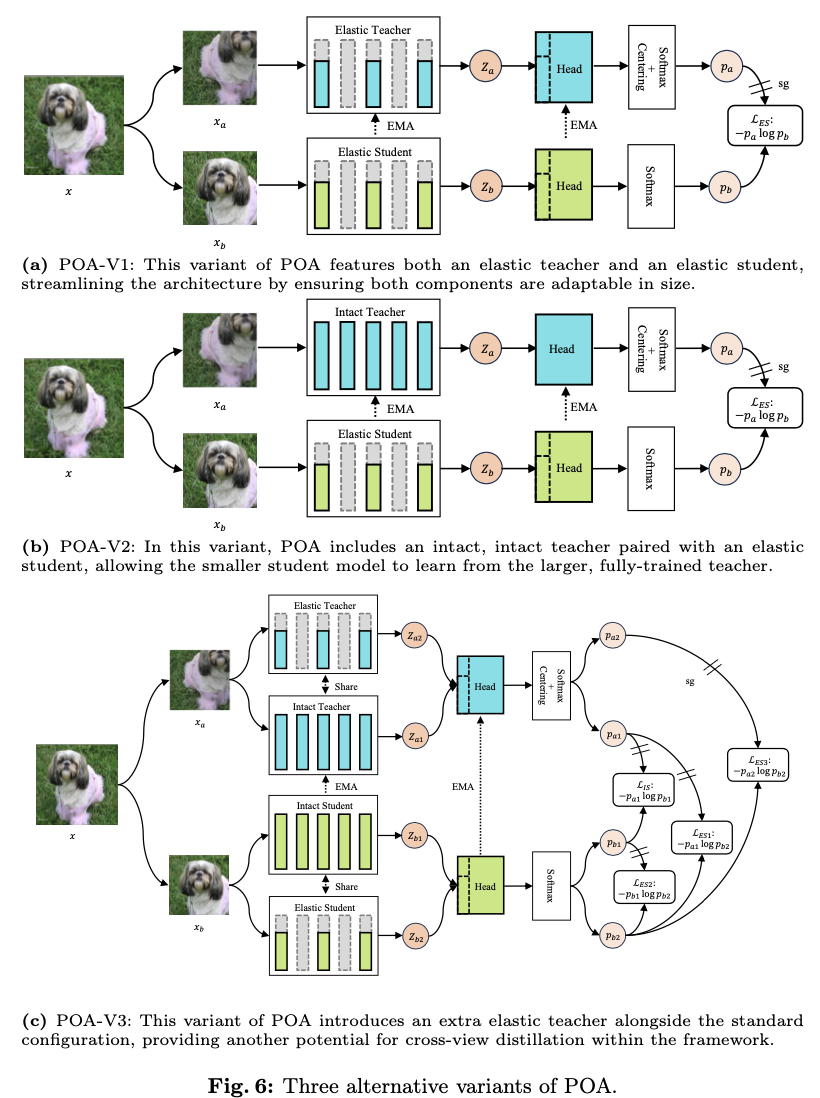
论文的主要目标是通过单次自监督预训练会话来预训练多种规模的模型,受到自蒸馏技术最新进展的启发,提出了一个名为POA的新型SSL(Self-supervised Learning)框架。POA架构如图2所示,包括一个teacher模型、一个完整的student模型、一个弹性student模型以及对应的头部。teacher模型使用student模型的指数移动平均(EMA)进行更新。弹性student模型是完整student模型的派生版本,其主干网络和头部参数是共享的。
在两个方面利用蒸馏技术:完整student和弹性student都是通过使用同一图像不同视图的teacher模型进行蒸馏,而弹性student还通过使用相同视图的完整student进行学习。交叉视图蒸馏作为一种表示学习形式,如所介绍的那样。值得注意的是,除了仅使用完整student进行常规EMA更新外,弹性student在每个预训练步骤中还提供一个随机抽样的子网络,参与teacher模型的EMA优化。这个过程实际上模拟了多个子网络的集成,这在监督学习领域也被证明是有益的。同视图蒸馏是完整student和弹性student之间的标准知识蒸馏,提升了弹性student的质量。
Design of Elastic Student
弹性student是一个子网络,其参数是从完整student中提取的。在transformer主干网络的背景下,宽度指的是标记的维度,而在卷积主干网络中,宽度表示通道数。深度则定义为transformer或卷积网络中基本块的数量。给定宽度和深度的值,会产生一定的网络结构。为简单起见,论文将重点放介绍ViT的弹性设计。
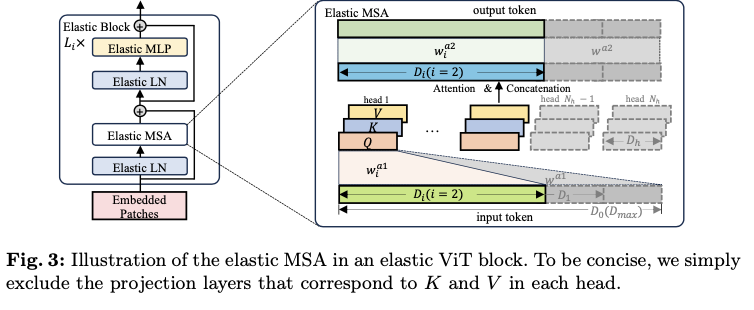
ViT的基本块主要由多头自注意力(MSA)模块和多层感知器(MLP)模块组成。在每个模块之前应用层归一化(LN),并在每个模块后使用残差连接。如图3的左侧所示,弹性块是指在ViT原始基本块中调整宽度后堆叠的弹性MSA、MLP和LN。在论文的方法中,弹性student分支是通过在每个训练迭代中组装特定数量的这些弹性块来构建的。
一个原始或完整的MSA模块由三个主要组件组成,即输入投影层,包含注意力和连接的操作符,以及输出投影层。将投影层定义为(
w
∗
,
b
∗
w^{\ast}, b^{\ast}
w∗,b∗ ),其中
w
∗
w^{\ast}
w∗ 表示线性转换权重,
b
∗
b^{\ast}
b∗ 表示相应的偏置,
∗
\ast
∗ 表示层的名称。如图3的右侧所示,给定一个标记维度
D
m
a
x
=
N
h
⋅
D
h
D_{max}=N_h \cdot D_h
Dmax=Nh⋅Dh ,其中
N
h
N_h
Nh 是注意力头的数量,
D
h
D_h
Dh 是头部维度,具有长度
T
T
T 的输入序列
z
∈
R
T
×
D
m
a
x
z \in \mathbb{R}^{T \times D_{max}}
z∈RT×Dmax 最初被投影以形成查询
Q
∈
R
T
×
D
h
Q \in \mathbb{R}^{T \times D_h}
Q∈RT×Dh 、键
K
∈
R
T
×
D
h
K \in \mathbb{R}^{T \times D_h}
K∈RT×Dh 和值
V
∈
R
T
×
D
h
V \in \mathbb{R}^{T \times D_h}
V∈RT×Dh 。为了生成弹性MSA,定义了M+1个弹性宽度,包括
D
m
a
x
D_{max}
Dmax ,间隔为
D
h
D_h
Dh:
KaTeX parse error: Undefined control sequence: \label at position 96: …\quad M < N_h. \̲l̲a̲b̲e̲l̲{eq:elastic_wid…
对于每个弹性宽度
D
i
D_i
Di ,从完整MSA中的相应输入投影层(
w
a
1
w^{a1}
wa1 ,
b
a
1
b^{a1}
ba1 )中提取生成每个头部的
Q
Q
Q 、
K
K
K 和
V
V
V 的权重
w
i
a
1
∈
R
D
h
×
D
i
w^{a1}_i \in \mathbb{R}^{D_h \times D_i}
wia1∈RDh×Di 和偏置
b
i
a
1
∈
R
D
h
b^{a1}_i \in \mathbb{R}^{D_h}
bia1∈RDh ,如
w
i
a
1
=
w
a
1
[
:
,
:
D
i
]
⋅
α
i
w^{a1}_i = w^{a1}[:, :D_i]\cdot\alpha_i
wia1=wa1[:,:Di]⋅αi 和
b
i
a
1
=
b
a
1
b^{a1}_i = b^{a1}
bia1=ba1 。这里,
α
i
\alpha_i
αi 表示用于应对输入维度减少的缩放因子,计算公式为
α
i
=
D
m
a
x
/
D
i
\alpha_i = D_{max}/D_i
αi=Dmax/Di 。随着宽度的减小,弹性MSA中的注意力头数量自然减少到
N
h
−
i
N_h - i
Nh−i 。类似地,对于输出投影层(
w
a
2
w^{a2}
wa2 ,
b
a
2
b^{a2}
ba2 ),权重
w
i
a
2
∈
R
D
i
×
D
i
w^{a2}_i \in \mathbb{R}^{D_i \times D_i}
wia2∈RDi×Di 和偏置
b
i
a
2
∈
R
D
i
b^{a2}_i \in \mathbb{R}^{D_i}
bia2∈RDi 被提取为:
KaTeX parse error: Undefined control sequence: \label at position 93: … b^{a2}[:D_i]. \̲l̲a̲b̲e̲l̲{eq:w_b_extract…
ViT块中的原始或完整MLP模块包含两个投影层。第一层(
w
m
1
,
b
m
1
w^{m1}, b^{m1}
wm1,bm1 )将嵌入维度扩展了
s
s
s 倍,通常在ViT结构中设置为4。然后,第二层(
w
m
2
,
b
m
2
w^{m2}, b^{m2}
wm2,bm2 )将其投影回原始维度。弹性MLP的两个层的参数以类似于公式2描述的方式提取,如下所示:
KaTeX parse error: Undefined control sequence: \label at position 227: … \end{aligned} \̲l̲a̲b̲e̲l̲{eq:mlp_extract…
对于弹性LN,直接使用原始LN内部参数的前
D
i
D_i
Di 个元素,类似于公式2中的偏置提取。
要从包含
L
m
a
x
L_{max}
Lmax 个块的完整ViT中创建一个包含
L
i
L_i
Li 个弹性块的子网络,引入了一组N+1个弹性深度,定义为
L
i
=
L
m
a
x
−
i
,
∀
i
∈
{
0
,
1
,
.
.
.
,
N
}
,
N
<
L
m
a
x
L_i = L_{max} - i,~~\forall i \in \{0, 1, ..., N\},~~N < L_{max}
Li=Lmax−i, ∀i∈{0,1,...,N}, N<Lmax 。对于特定深度
L
i
L_i
Li ,根据块ID在等间隔上选择相应的块。激活深度
L
i
L_i
Li 的每个块ID
B
I
D
j
L
i
BID^{L_i}_j
BIDjLi 可以表示为:
KaTeX parse error: Undefined control sequence: \label at position 142: ….., L_i - 1\}. \̲l̲a̲b̲e̲l̲{eq:block_id_ex…
因此,通过结合弹性宽度和深度,可以生成总共
(
N
+
1
)
⋅
(
M
+
1
)
(N+1)\cdot(M+1)
(N+1)⋅(M+1) 个不同的子网络。例如,通过将弹性宽度设置为384,弹性深度设置为12,可以直接从如ViT-L的完整网络中提取一个ViT-S。在预训练的每次迭代中,随机选择其中一个子网络作为弹性student分支。
Distillation between Views
POA根据其三个分支执行蒸馏。给定输入图像
x
x
x 的一对全局增强视图,表示为
x
a
x_a
xa 和
x
b
x_b
xb ,teacher编码器
E
T
E_{T}
ET 使用
x
a
x_a
xa 作为输入提取特征
Z
a
=
E
T
(
x
a
)
Z_a = E_{T}(x_a)
Za=ET(xa) 。同时,
x
b
x_b
xb 被输入到完整student编码器
E
I
S
E_{IS}
EIS 和弹性student编码器
E
E
S
E_{ES}
EES 中,分别产生特征
Z
b
1
=
E
I
S
(
x
b
)
Z_{b1} = E_{IS}(x_b)
Zb1=EIS(xb) 和
Z
b
2
=
E
E
S
(
x
b
)
Z_{b2} = E_{ES}(x_b)
Zb2=EES(xb) 。从teacher编码器输出的特征
Z
a
Z_a
Za 经过teacher头部
H
T
H_T
HT 处理,然后使用Sinkhorn-Knopp(SK)算法进行居中处理,并使用温度缩放softmax进行归一化,生成概率
p
a
p_a
pa ,如下所示:
KaTeX parse error: Undefined control sequence: \label at position 201: … \end{aligned} \̲l̲a̲b̲e̲l̲{eq:prob_teache…
其中
P
P
P 是原型(logits?)的数量,
τ
>
0
\tau > 0
τ>0 是温度参数。类似地,通过使用student头部
H
I
S
H_{IS}
HIS 和
H
E
S
H_{ES}
HES 处理输出来计算完整和弹性student编码器的概率
p
b
1
i
p^i_{b1}
pb1i 和
p
b
2
i
p^i_{b2}
pb2i 。然后,这些输出通过一个针对student量身定制的温度参数
τ
′
\tau'
τ′ 的温度缩放softmax函数进行处理。值得注意的是,
H
I
S
H_{IS}
HIS 和
H
E
S
H_{ES}
HES 共享相同的参数,只是
H
E
S
H_{ES}
HES 的第一个投影层进行公式2的相应调整,以便对齐相应的维度。为简单起见,省略了
p
b
1
i
p^i_{b1}
pb1i 和
p
b
2
i
p^i_{b2}
pb2i 的显式表达式,因为它们遵循与公式5类似的计算方式。对于完整student分支,使用跨视图数据从teacher进行蒸馏如下:
KaTeX parse error: Undefined control sequence: \label at position 59: … \log(p_{b1}). \̲l̲a̲b̲e̲l̲{eq:distill_is}…
弹性student分支在POA框架中发挥着至关重要的作用。为了确保这一分支的充分训练,采用了从teacher和完整student分支进行的双重蒸馏。第一次蒸馏涉及到teacher模型,利用跨视图数据来引导表示学习。第二次是与完整student模型进行的蒸馏过程,使用同视图数据。这种同视图蒸馏负责将完整student学到的表示转移到弹性student分支。这种双重蒸馏过程的损失函数制定如下
KaTeX parse error: Undefined control sequence: \label at position 128: … \log(p_{b2}). \̲l̲a̲b̲e̲l̲{eq:distill_es}…
请注意,在这两个损失函数中,对所有原型求和,以计算相应概率分布之间的交叉熵损失。
Overall Loss of POA
根据SSL方法,采用多裁剪策略从单个图像中创建各种失真视图。除了之前提到的两个全局视图外,还生成
v
v
v 个分辨率较低的局部视图
x
l
1
,
x
l
2
,
.
.
.
,
x
l
v
x_{l_1}, x_{l_2}, ..., x_{l_v}
xl1,xl2,...,xlv 。这些局部视图由两个student共同处理,以促进局部到全局的对应关系。完整和弹性student的局部蒸馏损失计算如下:
KaTeX parse error: Undefined control sequence: \label at position 90: …log(p_{l_i1}), \̲l̲a̲b̲e̲l̲{eq:local_disti…
KaTeX parse error: Undefined control sequence: \label at position 172: …log(p_{l_i2}), \̲l̲a̲b̲e̲l̲{eq:local_disti…
其中,
p
l
i
1
p_{l_{i1}}
pli1 和
p
l
i
2
p_{l_{i2}}
pli2 分别是完整和弹性student分支对于局部视图
l
i
l_i
li 产生的概率。完整和弹性student的总蒸馏损失通过将它们与因子
λ
\lambda
λ 相加来计算:
KaTeX parse error: Undefined control sequence: \label at position 310: … \end{aligned} \̲l̲a̲b̲e̲l̲{eq:total_disti…
为了确保弹性student的每个子网络都得到充分的训练,在主干网络之后引入了多个投影头(MPH)。每个投影头具有完全相同的结构,只是原型数量不同。对于每个投影头,根据公式10计算完整和弹性student的蒸馏损失
L
S
i
\mathcal{L_S}_i
LSi 。最终,在具有
H
H
H 个投影头的POA框架中,整体损失函数被表述为:
L
=
1
H
∑
i
=
1
H
L
S
i
\mathcal{L} = \frac{1}{H} \sum^H_{i=1}\mathcal{L_S}_i
L=H1∑i=1HLSi 。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









