







文章目录
上一篇:LearnGL - 18 - Instancing/Instanced Rendering - 多实例渲染1 - glDrawElementsInstanced,使用的是 UBO 的方式来作为多实例属性,但是 UBO 大小限制相当大
这一片:我们使用了另一个接口:glVertexAttribDivisor 处理,将 多实例属性大小的问题,分散到了每一个绘制实例,这样,多实例属性的数量可以提供到和正常的 uniform 的使用数量、大小一样
然后绘制效果可达 600W+ 个小陨石的性能
实践
应用层
C++ 应用层的改动,添加了一个动态的 Attribute 功能
AttributeSetting_t
这个数据结构是为了方便不同 shader 可以添加自定义的属性
struct AttributeSetting_t {
public:
// 属性类型,非 CUSTOM 的都是内置的
Attribute_Type type;
// 属性名字
std::string name;
// glBindBuffer
// buffer 的目标类型
GLenum buffer_target;
// buffer 实例对象
GLuint buffer_obj;
// glVertexAttribPointer
// 分量数量
GLint component_size;
// 分量类型
GLenum component_type;
// 是否归一化
GLboolean component_normalized;
// 单个属性的字节长度,如果是0的话,意味着紧密排列着
GLsizei component_stride;
// 在 buffer 段中的地址的字节偏移量
const void* attris_pointer_offset;
// glVertexAttribDivisor
// 是否多实例属性
bool instancing;
// 间隔实例数量(即:每间隔多少个绘制实例就使用下一个属性,如果为0的话,则多实例将被禁用)
GLuint divisor;
// attribute location 的偏移
GLuint loc_offset;
};
AttributeSetting_t 外部的使用
mat->instancing = true;
mat->instanc_count = INSTANCING_COUNT;
// mesh renderer - component
MeshRenderer* mr = new MeshRenderer();
mr->setQueue(RenderQueueType::Transprent);
getOwner()->addComp(mr);
GameObject* go = getOwner();
vec3 loc_scl = go->getTrans()->local_scale;
for (size_t i = 0; i < INSTANCING_COUNT; i++) {
mat4 tMat, rMat, sMat, com_rMat;
tMat = glm::identity<mat4>();
rMat = glm::identity<mat4>();
sMat = glm::identity<mat4>();
com_rMat = glm::identity<mat4>();
// s
vec3 s = vec3(
loc_scl.x + ran_range(0.0f, -0.9f),
loc_scl.y + ran_range(0.0f, -0.9f),
loc_scl.z + ran_range(0.0f, -0.9f));
// r
vec3 r = vec3(
ran_range(-360.0f, 360.0f),
ran_range(-360.0f, 360.0f),
ran_range(-360.0f, 360.0f));
// t
float y_scale = INSTANCING_COUNT < 30000 ? 1.0f : ((float)INSTANCING_COUNT / 30000);
vec3 t = vec3(ran_range(80.0f, 100.0f), ran_range(-10.0f, 10.0f) * y_scale, 0.0f);
// s
sMat = glm::scale(sMat, s);
// r
rMat = glm::rotate(rMat, D2R(r.y), vec3(0, 1, 0));
rMat = glm::rotate(rMat, D2R(r.x), vec3(1, 0, 0));
rMat = glm::rotate(rMat, D2R(r.z), vec3(0, 0, 1));
// t
tMat = glm::translate(tMat, t);
// 公转角度
com_rMat = glm::rotate(com_rMat, D2R(ran_range(-360.0f, 360.f)), vec3(0, 1, 0));
// trs 矩阵
instancingMat[i] = (com_rMat * tMat * rMat * sMat);
}
Pass* pass = mat->getPasses().at(0);
assert(instancing_mMat_buffer_obj == NULL);
if (instancing_mMat_buffer_obj == NULL) {
instancing_mMat_buffer_obj = new GLuint();
glGenBuffers(1, instancing_mMat_buffer_obj);
glBindBuffer(GL_ARRAY_BUFFER, *instancing_mMat_buffer_obj);
glBufferData(GL_ARRAY_BUFFER, INSTANCING_COUNT * sizeof(glm::mat4), &instancingMat[0], GL_STATIC_DRAW);
}
// GLSL 每个 vertex attribute (顶点属性)最大长度与 vec4 一样
// 而一个 mat4 有4个 vec4,所以需要遍历处理
for (size_t i = 0; i < 4; i++) {
AttributeSetting_t attrib_setting = {
Attribute_Type::CUSTOM,
"instancing_mMat",
// glBindBuffer
GL_ARRAY_BUFFER,
*instancing_mMat_buffer_obj,
// glVertexAttribPointer
4,
GL_FLOAT,
GL_FALSE,
sizeof(mat4),
(void*)(sizeof(vec4) * i),
// glVertexAttribDivisor
true,
1,
// loc offset
i
};
pass->attributes->push_back(attrib_setting);
}
底层遍历属性处理
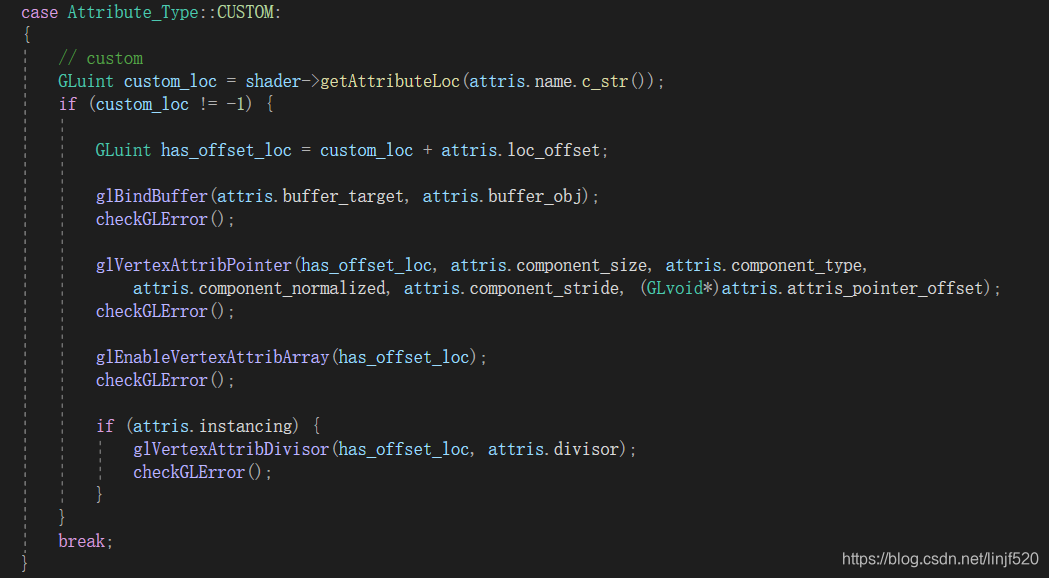
Vertex Shader
还是和之前一样,只有 顶点着色器 有改动,相比前一篇的实现方式来说,这种方式最大的好处是:
- 突破了 UBO 大小限制问题
- 不用在 shader 中指定 instancing 的数量
// jave.lin - testing_instancing_divisor.vert
#version 450 compatibility
#extension GL_ARB_shading_language_include : require
#include "/Include/my_global.glsl"
// vertex data
in vec3 vPos; // 顶点坐标
in vec2 vUV0; // 顶点纹理坐标
in vec3 vNormal; // 顶点法线
in mat4 instancing_mMat; // 多实例的 model matrix
// vertex data - interpolation
out vec2 fUV0; // 给 fragment shader 传入的插值
out vec3 fNormal; // 世界坐标顶点法线
out vec3 fWorldPos; // 世界坐标
void main() {
mat4 new_mMat = mMat * instancing_mMat; // 将原来的 mMat 累计变换到新的 model matrix
mat4 it_mMat = transpose(inverse(new_mMat)); // 求得新的逆矩阵的转置矩阵,用于变换法线用
// vec4 worldPos = mMat * vec4(vPos, 1.0); // 原来直接 model matrix 变换即可
vec4 worldPos = new_mMat * vec4(vPos, 1.0); // 现在使用新的 model matrix 变换
fUV0 = vUV0; // UV0
fNormal = normalize(mat3(it_mMat) * vNormal); // 用新的 it_mMat 矩阵来将模型空间的法线,变换到,世界坐标法线
fWorldPos = worldPos.xyz; // 世界坐标
gl_Position = vpMat * worldPos; // Clip pos
}
运行效果
30000 个陨石
60000 个陨石
12W 个陨石
24W
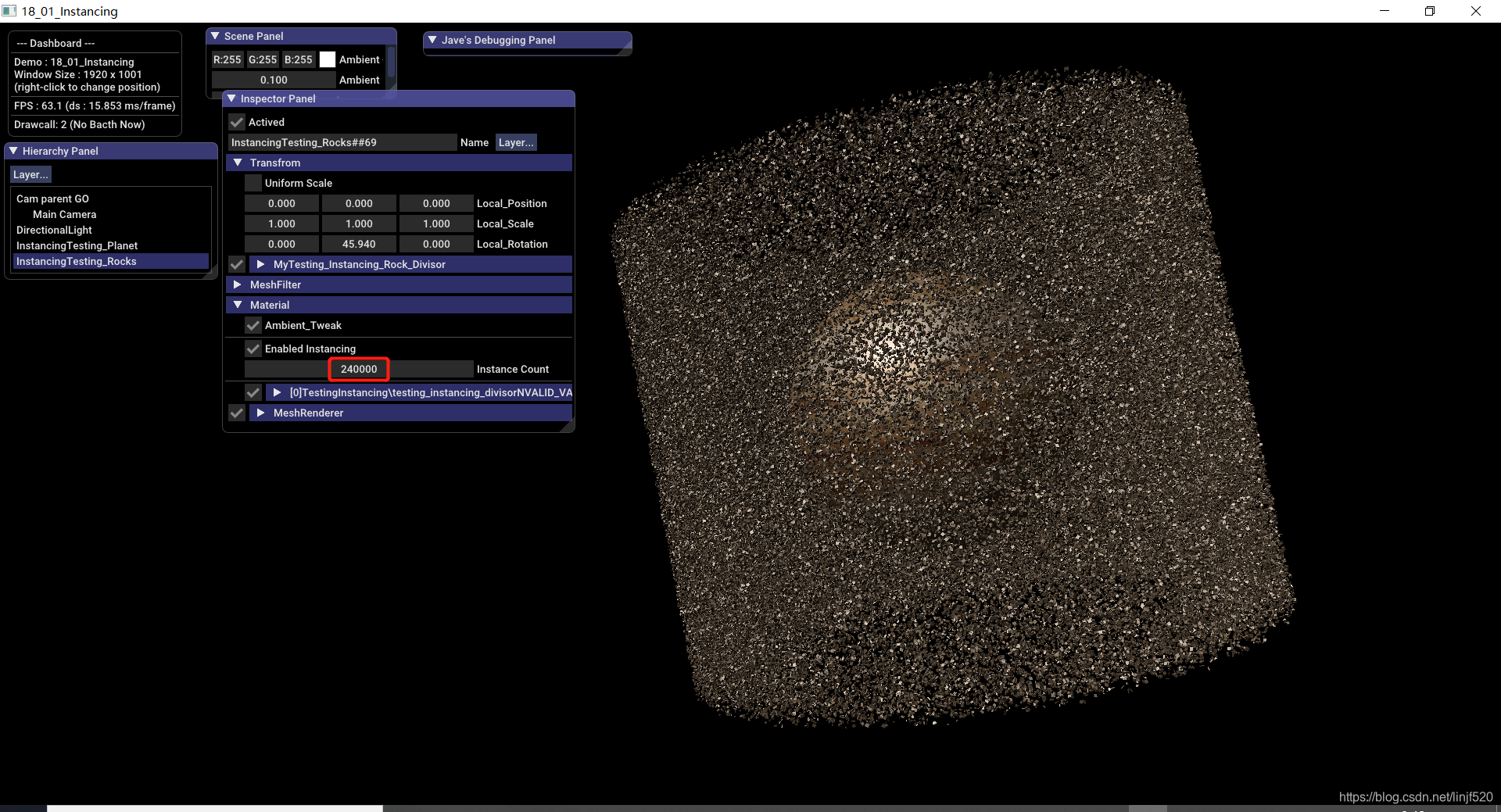
48W
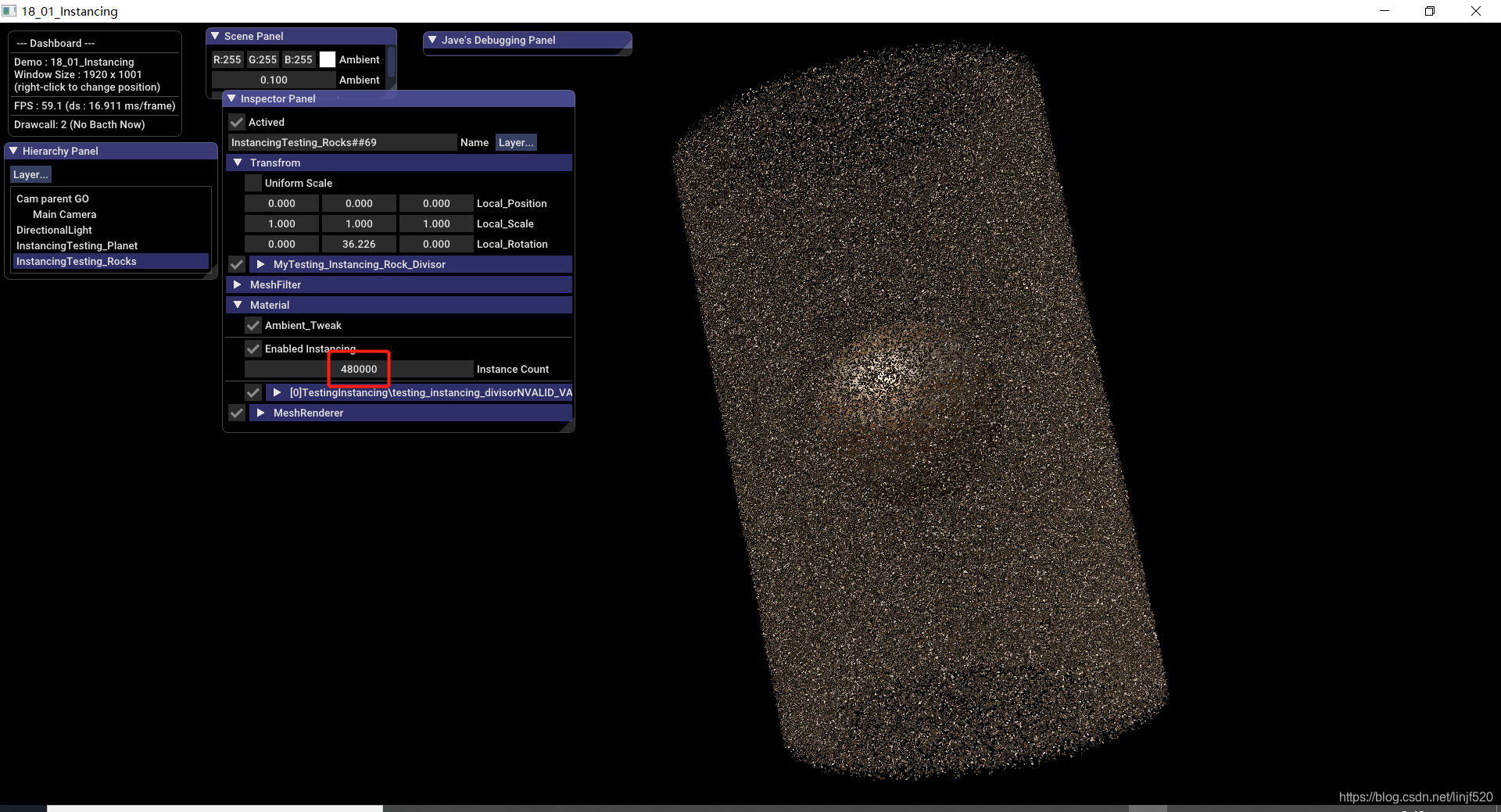
好烦,直接 600W 吧!
首先,因为我每次 2^N 的添加大小,发现性能还是杠杠的,所以我干脆弄大一些数值,一番10+倍
然后惊呆了,我的应用层为了初始化 600W个 model matrix,就用了 2分钟,因为计算量非常大
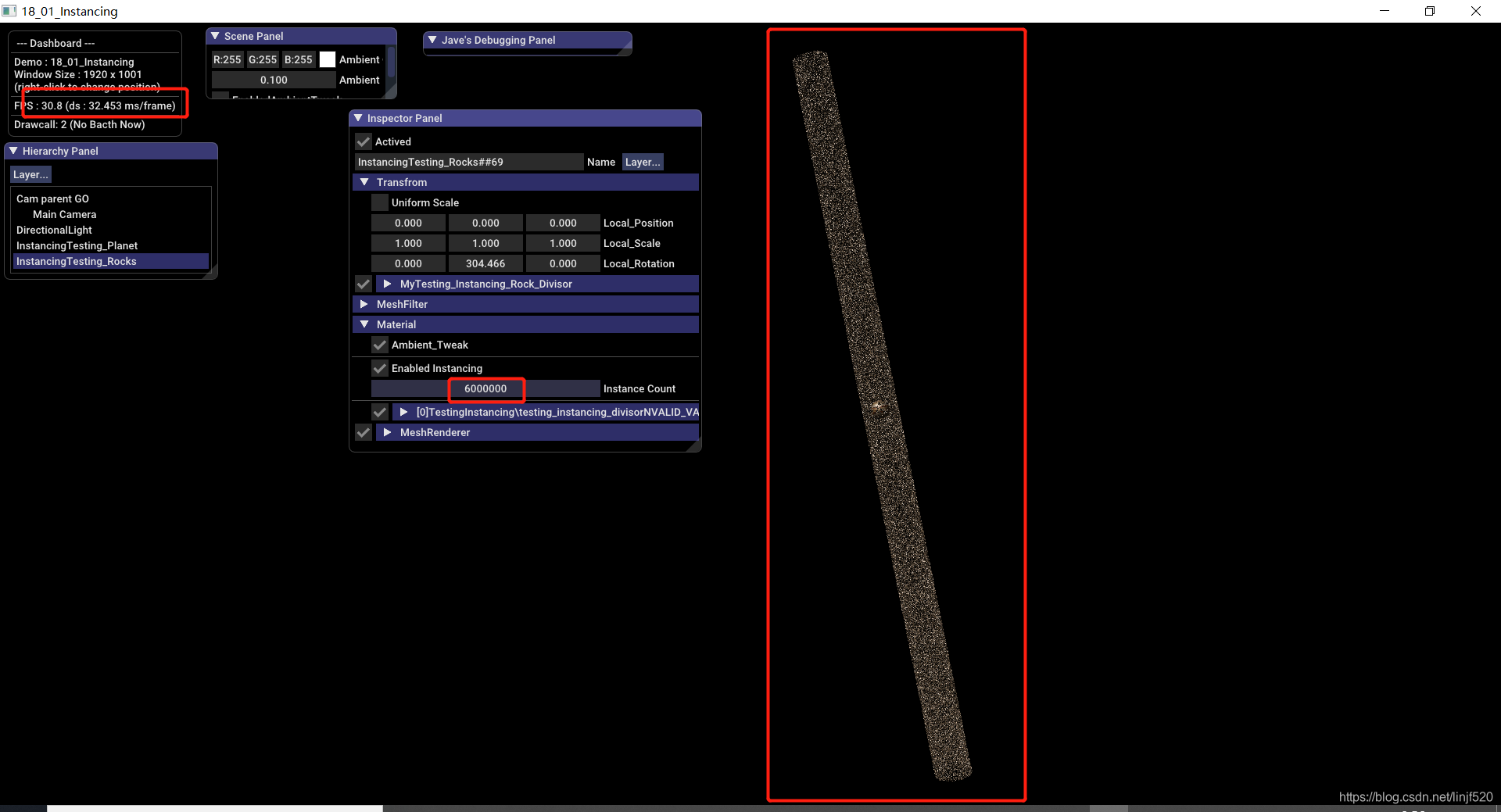
然后我的相机由原来的 far:1000,设置到:10000了

600W 顶点数
我的一个陨石实际是一个 Cube
这个 Cube 我还是简化过的,只有 8 个顶点,因为使用了索引
600W * 8 = 4800W 个顶点
我的显卡还是一般般的游戏本的
但这个绘制性能提升还是杠杠的!
下面是我几年前的游戏本中的显卡
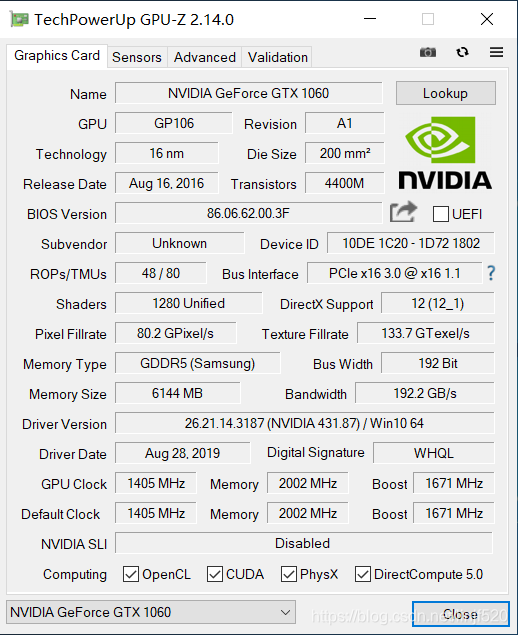
后续优化
后续还会有另一篇 instancing 的其他方式,使用的是缓存纹理对象的方式
扩展
缓存纹理这种方式在市场上应用比较多
特别是 “GPU 蒙皮 Like” 的方式应用优化大批量动画的方式
为何我加个 “Like” 因为不是真的实时计算蒙皮的方式
而是在 CPU 层,先将对应动画的蒙皮的顶点坐标 Baking(烘焙)到一张1维纹理,将:动画帧数、顶点索引、顶点位置,都写入,然后 Vertex Shader 读取顶点位置即可
唯一缺点:
- 不便于动画混合
- 还有如果超慢镜头(子弹时间)时,动画的可能会有跳帧(但是可以通过帧之间的数据做插值也是可以的)
References
- OpenGL 红宝书 第9版 第三章
- 实例化















 1788
1788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









