









0,预备知识
0.1,中心极限定理

0.2,均值的标准误差

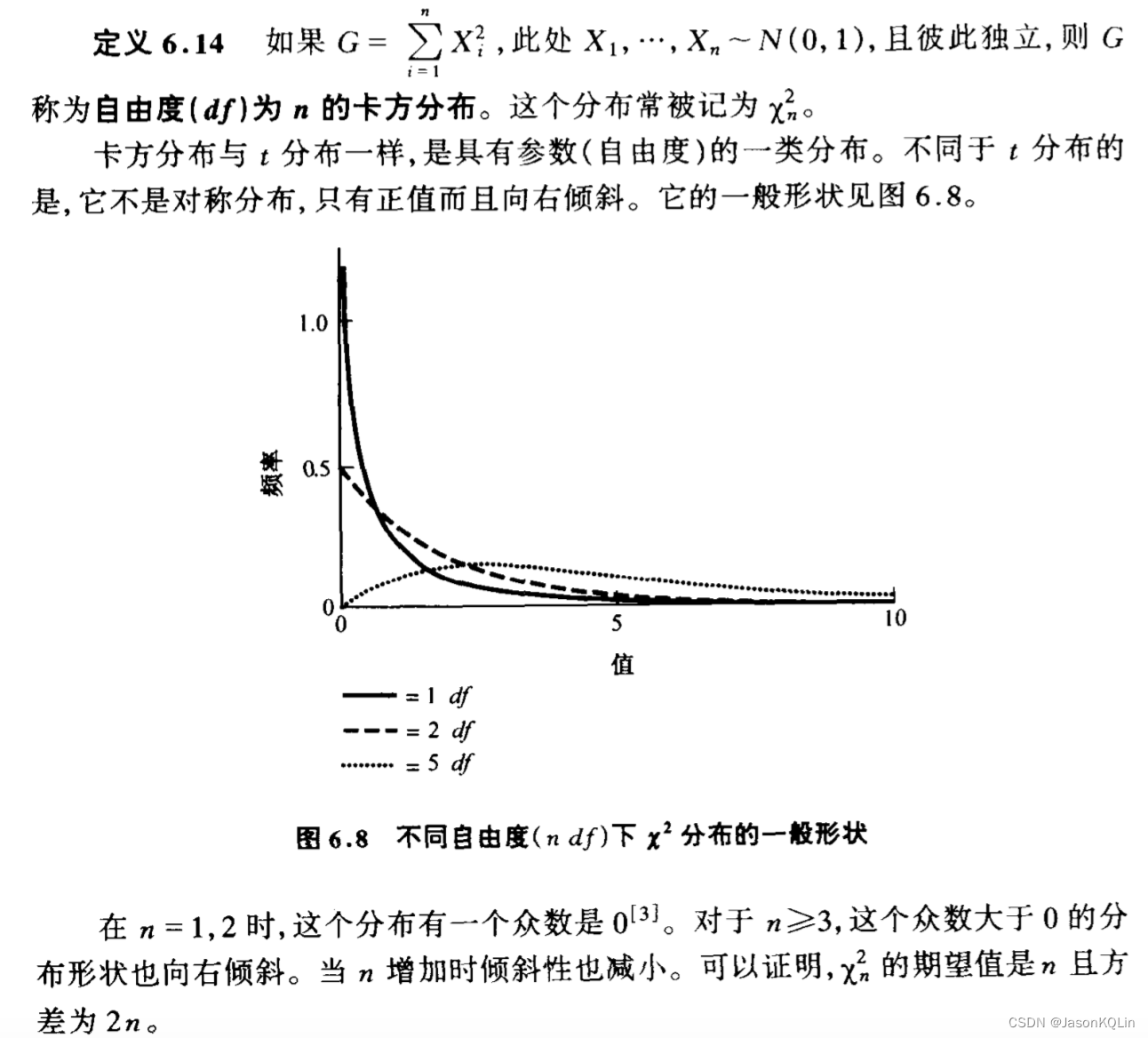
0.3,卡方分布
1,总体均值的无偏估计量

2.1,当总体方差已知时对样本均值的描述(Z统计量)

2.2,当总体方差未知时对样本均值的描述(t统计量)

3.1,当总体方差已知,或者大样本量(n>200,总体方差未知)时,总体均值的区间估计。(在实际操作过程中会对样本进行抽样,每次取n个数出来,算平均值,这些平均值的期望就是对总体方差的无偏估计)

3.2,当总体方差未知,总体均值的区间估计。

4.1,总体方差的点估计(对任何分布都成立)

4.2,总体方差的区间估计(仅对总体为正态分布成立)
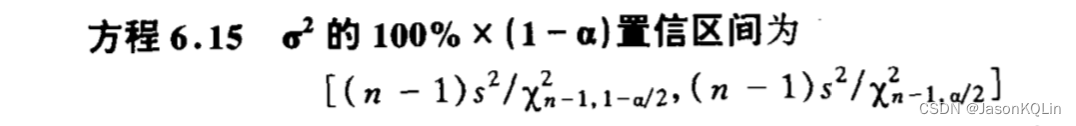
5, Moderated T statistic
这种方法在R软件包limma里面实现得最好。limma最初主要用于双色(双通道)芯片的处理,现在不仅支持单色芯片处理,新版还添加了对RNAseq数据的支持,很值得学习使用。安装方法同前面其他Bioconductor软件包的安装。载入limm软件包后可以用limmaUsersGuide()函数获取pdf格式的帮助文档。
limma的功能很多,这里只看看差异表达基因的分析流程,具体算法原理请参考limma在线帮助和这篇文献:Smyth G K. Linear models and empirical bayes methods for assessing differential expression in microarray experiments[J]. Statistical applications in genetics and molecular biology, 2004, 3(1): 3.

















 2233
2233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









