







 本文深入探讨深度学习的应用,强调监督学习的成熟度,并指出迁移学习作为未来可能商用的重要AI技术。文章解释了迁移学习如何解决场景转换中的数据不足问题,列举了不同迁移学习策略。接着,文章引入强化学习(DRL),阐述其在游戏AI和机器人领域的应用,以及其探索式学习的特点。强化学习通过Agent、Environment、Actions和Rewards等要素形成智能决策过程。
本文深入探讨深度学习的应用,强调监督学习的成熟度,并指出迁移学习作为未来可能商用的重要AI技术。文章解释了迁移学习如何解决场景转换中的数据不足问题,列举了不同迁移学习策略。接着,文章引入强化学习(DRL),阐述其在游戏AI和机器人领域的应用,以及其探索式学习的特点。强化学习通过Agent、Environment、Actions和Rewards等要素形成智能决策过程。
一. 深度学习及其适用范围
大数据造就了深度学习,通过大量的数据训练,我们能够轻易的发现数据的规律,从而实现基于监督学习的数据预测。
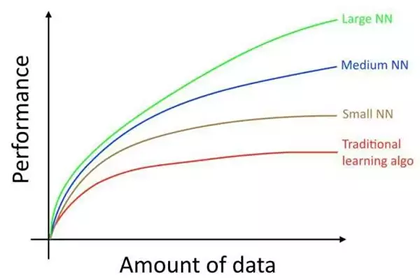
没错,这里要强调的是基于监督学习的,也是迄今为止我在讲完深度学习基础所给出的知识范围。
基于卷积神经网络的深度学习(包括CNN、RNN),主要解决的领域是 图像、文本、语音,问题聚焦在 分类、回归。然而这里并没有提到推理,显然我们用之前的这些知识无法造一个 AlphaGo 出来,通过一张图来了解深度学习的问题域:
2016年的 NIPS 会议上,吴恩达 给出了一个未来 AI方向的技术发展图,还是很客观的:
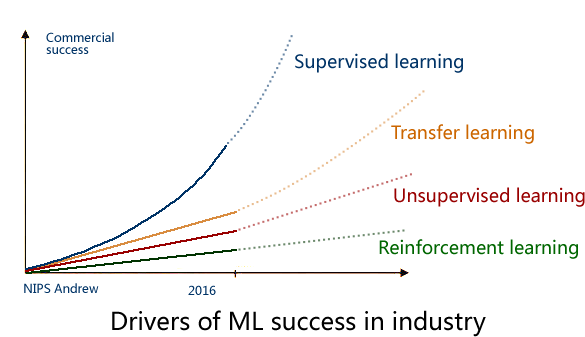
毋庸置疑,监督学习是目前成熟度最高的,可以说已经成功商用,而下一个商用的技术 将会是 迁移学习(Transfer Learning),这也是 Andrew 预测未来五年最有可能走向商用的 AI技术。
二. 迁移学习(举一反三的智能)
迁移学习解决的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









