






 斯坦福大学和丰田研究所的研究者提出PrismaticVLMs,通过单阶段训练和改进的组件,提升模型性能。实验结果显示PRISM在多项任务中超越现有模型,强调了设计决策对VLM的关键作用。
斯坦福大学和丰田研究所的研究者提出PrismaticVLMs,通过单阶段训练和改进的组件,提升模型性能。实验结果显示PRISM在多项任务中超越现有模型,强调了设计决策对VLM的关键作用。
📌 元数据概览:
- 标题:“Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models”
- 作者:Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh;来自斯坦福大学和丰田研究所。
- 链接:arXiv:2402.07865v1
- 标签:#VisuallyConditionedLanguageModels #VLMs #DesignSpace #ImagePreprocessing #LanguageModels
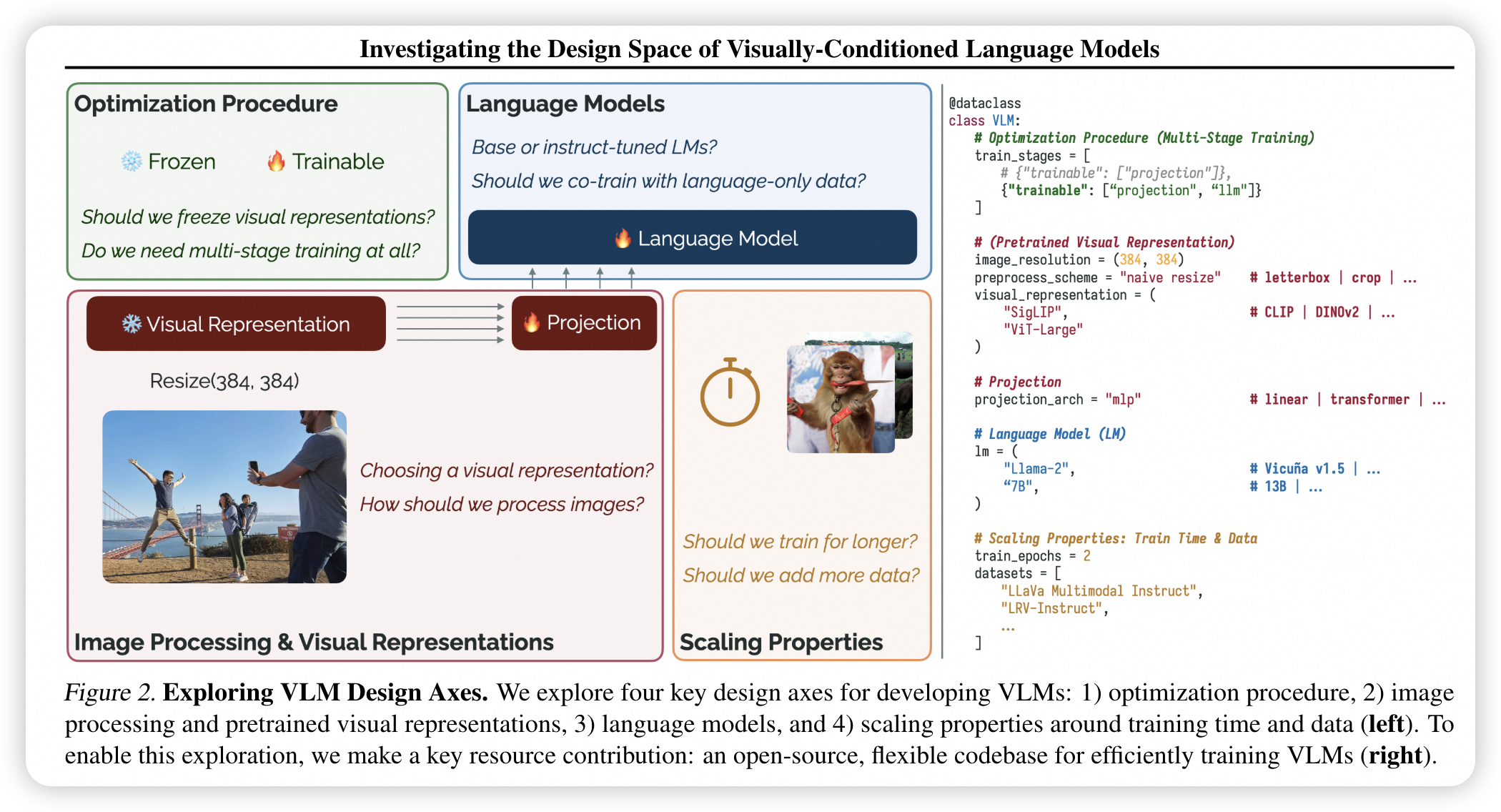

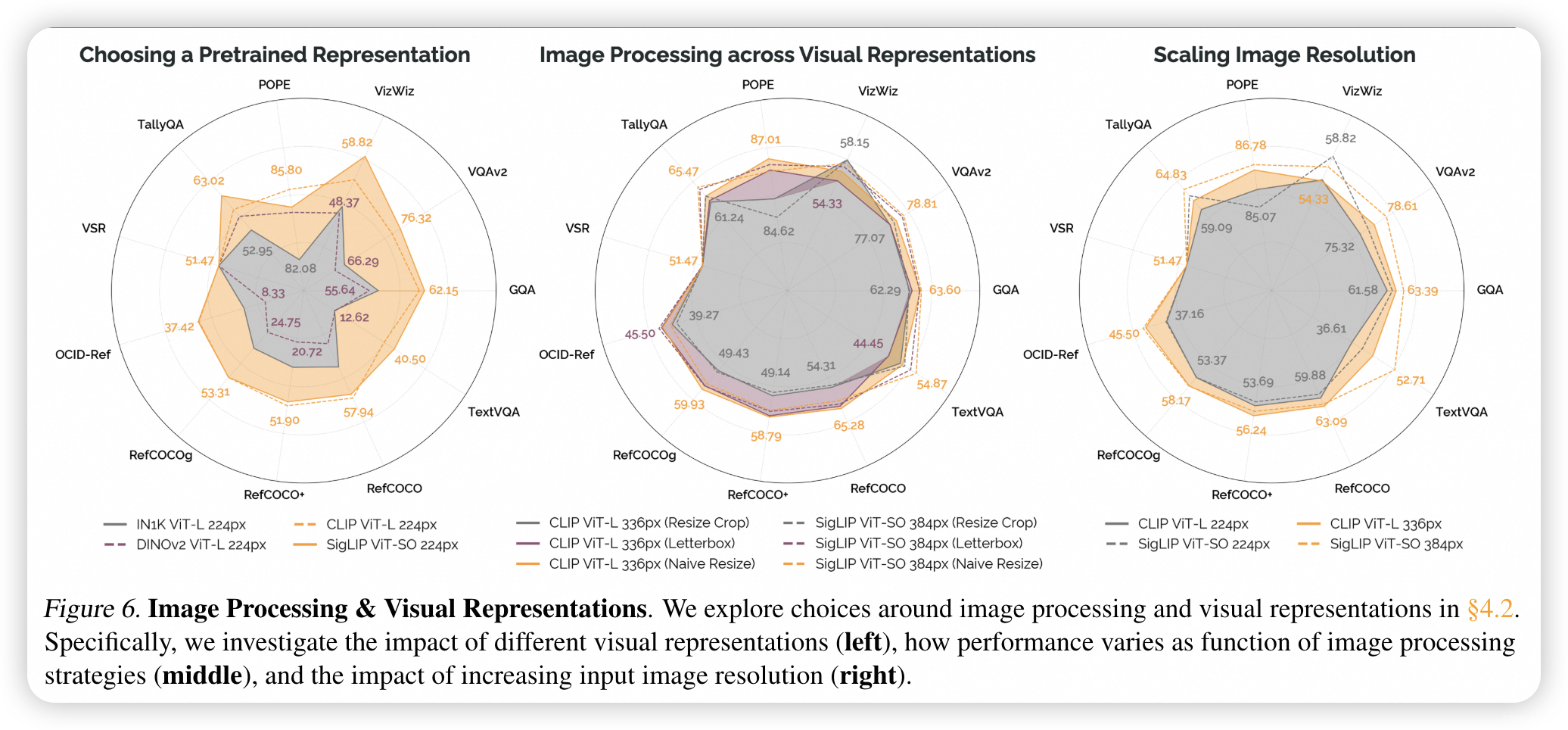

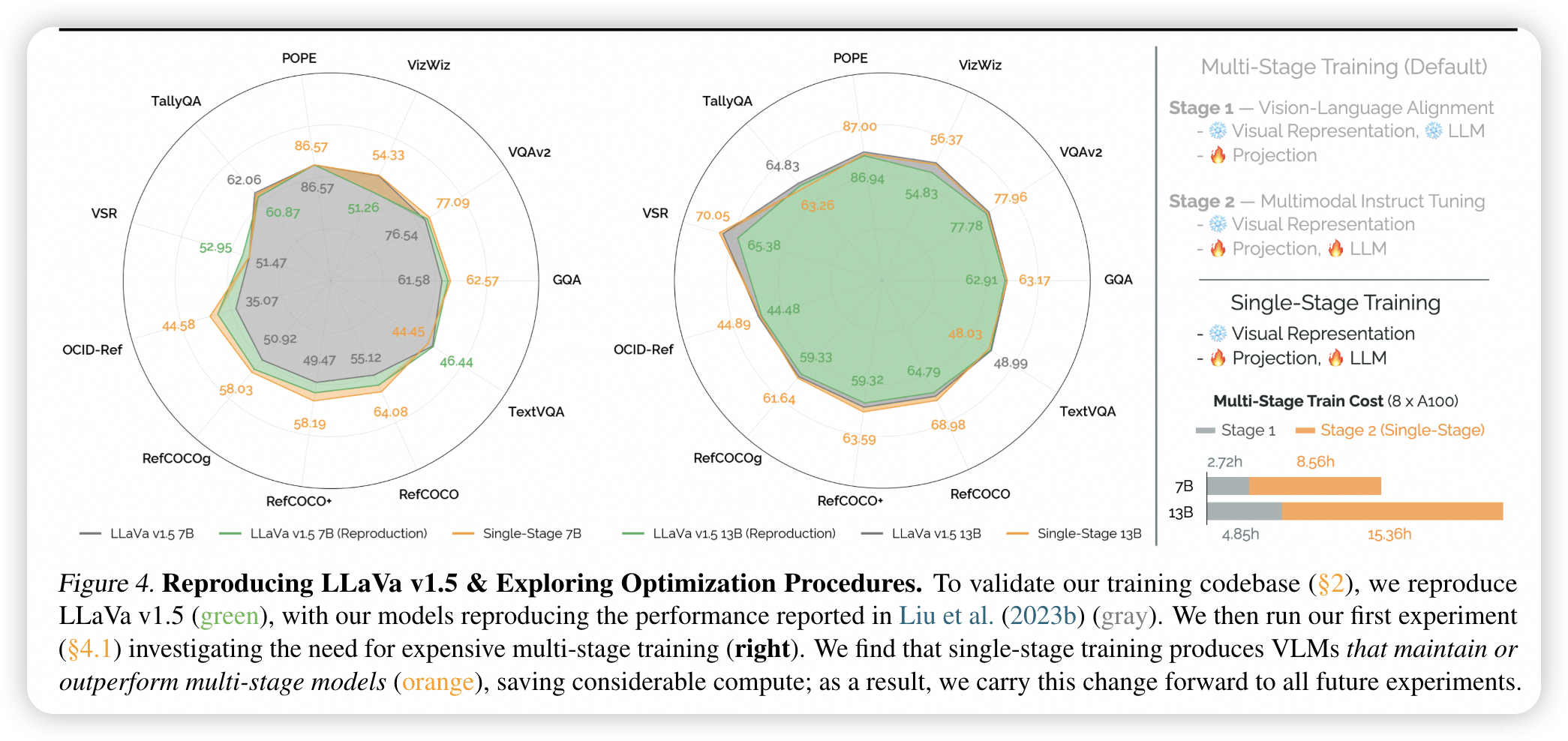
- ✨ 核心观点与亮点:
- 主张:本文通过一系列实验探索了视觉条件语言模型(VLMs)的设计空间,提出了改进训练的关键见解,并发布了PRISM系列模型,这些模型在多个基准测试中超越了现有的开源VLMs。
- 亮点:研究团队开发了标准化的评估套件和灵活的VLM训练代码库,并通过实验探索了优化过程、图像处理、预训练视觉表示、语言模型以及训练时间和数据规模等关键设计轴。
- 核心贡献:提出了PRISM系列VLMs,这些模型结合了研究中发现的关键见解,以单阶段训练流程、融合的DINOv2和SigLIP表示、基础语言模型以及多数据源训练,显著提升了性能。
- Motivation:鉴于VLMs在视觉对话、场景理解和机器人任务规划等应用中的日益普及,研究者们旨在深入理解影响VLM性能和下游使用的关键设计决策。
- 📚 论文的核心内容,模型结构,关键术语/概念:
- 核心内容:论文提出了PRISM模型,这是一个视觉条件语言模型,它通过单阶段训练、图像处理和视觉表示的改进、语言模型的选择以及训练时间和数据规模的调整来提高性能。
- 模型结构详述:PRISM模型采用了视觉表示背骨、视觉-语言投影器和语言模型的通用架构。研究者们探索了不同的图像处理方法、视觉表示(如CLIP、SigLIP、DINOv2)、语言模型(如Llama-2和Vicuna v1.5),以及训练策略(如单阶段训练与多阶段训练)。
- 🌟 实验结果:
- 核心实验结果:PRISM模型在多个基准测试中取得了优异的性能,例如在VQAv2、GQA、TextVQA等数据集上超越了现有的InstructBLIP和LLaVa v1.5模型。特别是在7B和13B规模的模型中,PRISM展示了在少于30%的训练计算资源下相比于LLaVa v1.5的显著性能提升。
- 消融实验:通过一系列消融实验,研究者们发现单阶段训练相比于多阶段训练在不增加计算成本的情况下能够提升性能,且基础语言模型与指令调优语言模型相比,在性能上具有可比性,同时在安全性方面表现更好。
- 🔄 总结归纳:
- 本文通过深入分析VLMs的设计空间,提出了PRISM系列模型,这些模型在多个基准测试中取得了SOTA性能,展示了在VLM设计中考虑关键设计轴的重要性。研究者们还提供了标准化的评估套件和高效的训练代码库,为未来的VLM研究奠定了基础。
- 相关工作:与本文相关的其他核心论文包括但不限于LLaVa、BLIP、Vicuna等,这些研究同样探索了视觉条件语言模型的不同方面。
- ❓ 引发思考的问题:
- 在VLM设计中,哪些因素对于模型性能的影响最为显著?
- 如何在保持模型性能的同时减少训练和推理阶段的计算需求?
- 单阶段训练和多阶段训练在VLM中各自的优势和劣势是什么?
- 不同的视觉表示和语言模型对VLM性能有何影响?
- 在未来,VLMs在处理更复杂的视觉和语言任务时,可能需要哪些新的架构创新或优化策略?


















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











