







目录
一、多层感知机的从零开始实现
1. 导入实验所需要用到的库
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt2. 获取数据集
这里我们使用d2l库中的Fashion-MNIST数据集,使用load_data_fashion_mnist()函数来获取数据集,传入参数为批次大小,返回可迭代的训练集和测试集,每次迭代中数据集的大小为批次大小,这与之前线性回归简易实现的操作类似。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)3. 初始化模型参数
在softmax回归实验时我们就使用过fashion_mnist数据集,这个数据集中的每个样本都是28×28的图像,其本质是一个二维矩阵,矩阵中的值为图像在该像素点的灰度值,它的标签为10种分类。
我们像之前实验一样将数据集的灰度矩阵中的值全部取出作为特征值,则每个样本一共有784个特征值,数据集一共有10个种类,而网络的输出为该样本属于各个种类的概率,则网络的输出结果为10,因此权重值的横向维度(第1轴)则需要为10,对应10个种类各自的权重,纵向维度(第0轴)则与特征值数量相同,对应各个样本的权重。
本次实验是多层感知机,需要突出“多层”,因此需要在上次实验的基础上加上隐藏层来增加层数,要增加一层隐藏层则需要同时增加一个权重和偏置值。
由上次实验我们可以知道每层的权重形状为输入个数X输出个数,偏置形状即为输出个数,所以我们需要更改一下权重和偏置的形状,第一层输入为特征值,隐藏层输入为第一层的输出,隐藏层的输出即为最终结果,如此可以得到两个权重和偏置的形状太小。如下代码所示初始化了两个权重和偏置。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]上述代码使用的是randn函数,这个函数输出的是标准差为1均值为0的正态分布的随机数,一般我们选择的标准差是0.01,所以将结果乘上了0.01,或者我们也可以直接使用torch.normal函数来初始化,它可以选择标准正态分布的标准差。
最后不要忘了设置requires_grad=True来自动计算梯度。
4. 激活函数
我们的输出是输入乘上权重再加上偏置,只是个线性组合,不管添加多少层也还是线性的,若只是线性组合的话,那模型就很难解决较复杂的问题,因为很多复杂的问题通常都不是线性的。
激活函数就是用于解决这个问题,激活函数是将输入映射到一个非线性的值上,这样就会往模型中加入非线性的因素,使得模型可以处理更复杂的问题。
既然是从零开始,则激活函数我们也自己实现,这样才能更好地掌握整个模型的细节。这里我们实现一个较为简单且效果也很好的激活函数ReLU函数。
ReLU函数的原理就是将小于0的值全部设为0,大于0的值则不变,这样随机初始化的网络就只有一半激活状态,可以引导适度稀疏。
根据ReLU函数的实现原理,我们可以使用python代码来实现它。
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)torch.zeros_like()函数是得到一个与X(输入)形状相同的全零的张量,再使用torch.max()函数取“0”和“X中值”二者的最大值。
5. 网络模型
接着我们开始实现我们的神经网络模型。
我们的网络模型有三层,一层输入,一层隐藏层,一层输出,首先计算第一层的输出,将第一层的输出经过激活函数激活后,再将第一层的输出输入到隐藏层中,由隐藏层输出结果。
def net(X):
X = X.reshape(-1, num_inputs)
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)注意X是图像的灰度矩阵,是个二维矩阵,我们只需要它的全部灰度值,不需要它的空间结构,因此将X转换为一维张量,reshape(-1, num_inputs)是将张量的第1轴(列)的大小改为num_inputs,第0轴的大小根据X的元素个数自动计算:num / num_inputs ,num是X中元素个数,如X中有num_inputs个元素,则该轴大小为1。
6. 损失函数
在上次实验中我们已经实现过损失函数了,这次实验我们直接使用库函数即可。
这里使用交叉熵损失函数。
loss = nn.CrossEntropyLoss()7. 训练
一切准备完成后,现在我们就可以开始对模型进行训练了。
多层感知机的实验与softmax回归的训练过程完全相同,我们直接调用d2l包的train_ch3函数来对模型进行训练,参数优化器也选择与softmax回归一样的SGD函数。
num_epochs, lr = 12, 0.15
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)多次测试后,我的超参数设置为:隐藏层大小512,轮数12,学习率0.15,能得到一个较好的结果
二、多层感知机的简洁实现
1. 网络模型
同softmax简易实现一样,我们通过实例化Sequential类来作为我们的神经网络。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))传入的参数为对每一层的操作,我们一共有3层网络,第一层需要进行的操作是将二维矩阵展平成一维张量,使用Flatten()函数实现,第二层为隐藏层,需要进行的操作是将输入数据进行线性映射使用nn.Linear()函数实现,传入的参数为输入大小和输出大小,接着对隐藏层的输出进行激活,使用nn.ReLU()激活函数,这里不算是第三层,只是第二层的操作,但在net网络中算是第三层,最后一层即为输出,对第二层的输出进行线性映射得到,同样使用nn.Linear()函数实现。
2. 初始化模型参数
nn.Linear进行线性映射时,会自动对权重和偏置进行初始化,偏置的初始化为0,无需更改,我们只需对权重进行自定义初始化。
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);如上述代码将权重初始化为标准差为0.01的标准正态分布随机数,再将其应用到net的每一层线性映射中。
3. 训练
损失函数与之前一样使用交叉熵损失函数,其他操作基本与之前相同
batch_size, lr, num_epochs = 256, 0.3, 20
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化函数
trainer = torch.optim.SGD(net.parameters(), lr=lr)
# 从数据集中每次去取一小批量的数据,每批数据拆分为训练集和测试集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 训练模型
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)开始训练
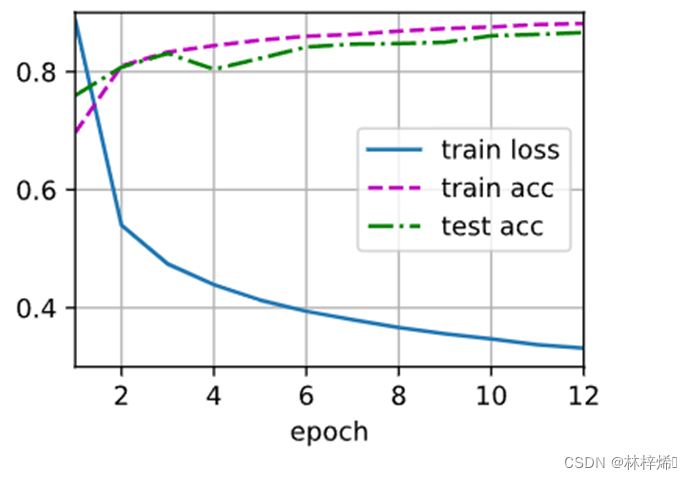
训练得到的结果与从零开始实现训练的结果是很接近的。
三、实战Kaggle比赛:房价预测
通过前面的学习,我们已经对多层感知机有了很深入的认识,同时也掌握了多层感知机的基本操作步骤,现在我们将对本次实验的内容学以致用,通过参加Kaggle的比赛:房价预测来检验我们的学习成果。
1. 获取和读取数据集
房价预测比赛的数据集分为训练集和测试集,训练集和测试集中都包括了每栋房子的特征:街道类型、建造年份、房顶类型、地下室状况80个特征以及一个标签值,即房子的价格,我们通过训练集进行训练后再对测试集进行测试,测试集没有标签值,我们只能通过将预测出来的结果提交到Kaggle网站来查看模型的性能。
我们先从Kaggle网站中下载数据集,再使用pandas库读入并处理数据。
import pandas as pd
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))我们可以通过打印train_data和test_data的shape来查看测试集和训练集的大小
print(train_data.shape)
print(test_data.shape)训练集大小为1460 x 81,包含1460个样本,每个样本包含80个特征以及一个标签值

测试集大小为1459 x 80,包含1459个样本,每个样本包含80个特征。

接着我们抽取几个样本查看一下样本的部分特征和标签
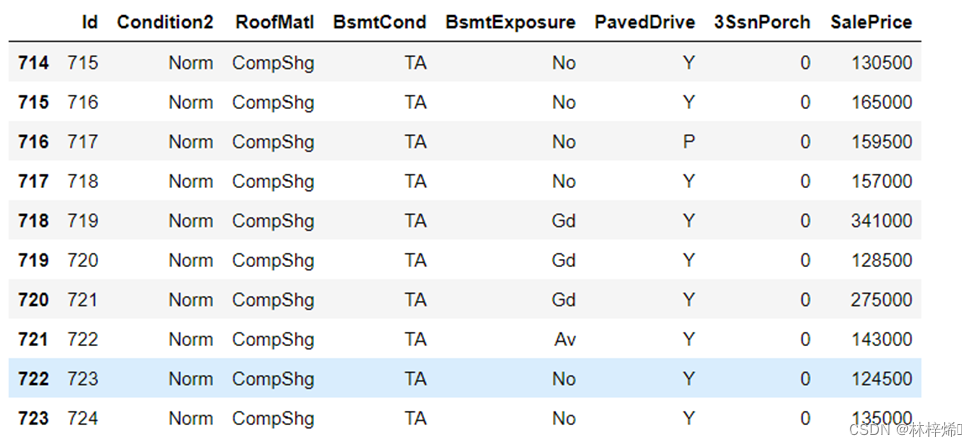
可以看到第一个特征是id,它的值表示的是样本的顺序位置,它能帮助模型记住每个训练样本,但对测试集无用,训练时不需要使用这个特征,因此需要对训练集和测试集进行切片,将每个样本的第一个特征去除,然后再将训练集和测试集的特征连接到一起,使得测试集和训练集可以进行相同的预处理操作。
all_features = pd.concat((train_data.iloc[:, 1: -1], test_data.iloc[:, 1:]))train_data.iloc[:, 1 : -1] 切片是取所有行,每行取第二列到倒数第二列(第一列id和倒数第一列标签被去除),“,:”和“:,”分别表示取所有行和所有列,“1: -1”则表示对另一个维度的切片,如果是取所有行,则是对列进行切片,取所有列则是对行切片。
同理test_data.iloc[:, 1:]) 则是取所有行,每行取第二列到最后一列。
这样就去除了训练集和测试集的id特征和训练集的标签,并将二者连接到一起了。
2. 预处理数据
得到数据后,我们还需要对样本的特征值进行标准化,防止过大的特征对结果影响远超其他特征,导致其他特征对结果的影响被忽略。
设该特征在整个数据集上的均值为𝜇,标准差为𝜎。那么,我们可以将该特征的每个值先减去𝜇再除以𝜎得到标准化后的每个特征值。数据集中也会有一些样本的特征值为缺失值,对于缺失的特征值,我们将其替换成该特征的均值。
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 标准化后,每个数值特征的均值变为0,所以可以直接用0来替换缺失值
all_features[numeric_features] = all_features[numeric_features].fillna(0)如上述代码x.mean()就是计算x的均值,x.std()计算x的标准差,将x减去均值再除以标准差就能得到标准化后的x值。
对于缺失值,我们使用x的均值来替换,这里x的均值为0,可以直接用0替换,使用all_features.dtypes[all_features.dtypes != 'object'].index 切片来获取所有类型不属于object(不是个类型)的特征值的索引,这个特征值即为缺失的特征值,再通过这个索引访问该特征值,将其值改为均值0。
因为我们的算法只能处理数值型的数据,不能处理离散型的数据,例如BsmtCond的值离散的值(TA,Gd等),不是数值型的数据(0,1),我们需要将特征的离散取值转换为指示特征,比如:假设一个特征feature有两个离散的取值a和b,我们将feature特征拆分成feature_a和feature_b两个特征,这两个特征取值为0和1,为1则表示特征feature取这个值。
使用panda的get_dummies()函数来进行拆分。
# dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征
all_features = pd.get_dummies(all_features, dummy_na=True)输出拆分结果:
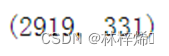
可以看到,原本79的特征数扩大到了331。
预处理完后,就可以将训练集和测试集以及训练集的标签拆分出来并转化为张量
n_train = train_data.shape[0]
# 训练集特征(训练集分为特征和标签)
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float)
# 测试集特征
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float)
# 训练集标签
train_labels = torch.tensor(train_data.SalePrice.values, dtype=torch.float).view(-1, 1)如上述代码,先获取训练集的样本个数,再根据其将训练集和测试集切片拆分出来,使用它们的value属性可以得到NumPy格式的数据,再使用torch.tensor将NumPy数据转换为张量,方便后面的计算,标签则直接访问train_data的SalePrice属性,同样转换为张量,为了方便后续的计算,需要将标签的形状从行向量改为列向量。
3. 训练模型
步骤同上节一样,选择损失函数,定义网络模型。
这里使用平方损失函数,因为比赛评价模型的指标是对数均方根误差,使用平方根误差转换成对数均方根误差较为方便,模型先只选择一层简单线性回归。
#定义损失函数
loss = nn.MSELoss()
# 特征的数量即为训练集的列数(shape[1])
in_features = train_features.shape[1]
# print(in_features)
def get_net():
# 隐藏层大小
hidden_size = 256
# 定义神经网络(线性回归模型)
net = nn.Sequential(nn.Linear(in_features,1))
return net比赛中用于评价模型的指标是对数均方根误差,给定预测值 𝑦̂ 1,…,𝑦̂ 𝑛
和对应的真实标签 𝑦1,…,𝑦𝑛,它的定义为:

注意这里对数的底是自然常数e,一般来说如果没有说明,对数的底都是e,求幂的幂也是e。
我们上面已经定义了平方损失函数,我们只需将 yi 和 𝑦̂i 改为 log yi 和 log 𝑦̂i 传入平方损失函数再开平方即可。
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()接着定义训练函数,这里训练的步骤与线性回归实验中的步骤是一样的,只不过将优化算法改为了Adam,此算法对学习率的敏感度较低。
4. K折交叉验证
定义完训练函数,接下来定义测试函数。
注意我们的测试集是从训练集中抽取的,而不是用从Kaggle网站下载来的测试集,Kaggle网站下载的测试集是网站用于评价我们的模型的,因此没有样本标签,我们不能用它来作为测试集。
普通的验证方法是简单的将训练集按比例拆分成训练集和测试集,这里拆分出来的测试集单一,如果是有一定规律未被打乱顺序的数据集,则这样拆分出来的结果非常片面,因为测试集中会有大量属于同一类别的样本,这样仅能测试出模型对某几种样本的预测性能,并不能全面衡量模型对所有种类样本的预测性能,泛化性很低,而且可能会导致训练的结果过拟合,对特定的数据集预测性能非常好,但遇到未见过的数据集预测性能就很差了。
为解决这个问题,这里我们使用K折交叉验证法,其原理是将训练集拆分成K个子集,每个子集称为折,然后进行k次循环,每次将第i(i取值为0到k-1)折作为测试集,其他折作为训练集,这样训练集中每个样本都会被测试到,模型的泛化性能能得到很好的评估。
如下代码定义了一个将训练集拆分成K折的函数。
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid其传入四个参数:k(折数)、i(第几折作为测试集)、X(训练集)、y(标签)
首先计算每折的大小,其等于训练集的行数除以折数,必须要用整除“//”(注意这个不是c语言的注释,而是python里的整除符号)来使结果为整数,因为切片索引必须是整数。
随后进行k次循环,每次循环拆分出一折,通过j * fold_size, (j + 1) * fold_size这个索引来切片出第j折,当j=i时,则说明这一折是测试集,将其值传入X_valid, y_valid中,其他折则传入X_train,y_train中。
接着再定义K折交叉验证的函数:
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k如上述代码,循环k次,每次取第k折作为测试集,其他折作为训练集,然后使用上面定义的训练函数进行计算,得到训练损失和测试损失,将其累加,再在最后将累加值除以k(K折交叉验证循环验证了K次)得到平均损失。
为了方便观察每个迭代周期的训练和测试损失,我们使用d2l的plot函数进行绘制训练和测试损失随迭代周期增长的变化。
5. 模型选择
所有要用到的函数都已经定义好了,接着我们就可以选择超参数来计算K折交叉验证误差了,超参数需要多次测试来得到一个最佳值。
k, num_epochs, lr, weight_decay, batch_size = 10, 15, 0.1, 0.006, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')这里我经过多次测试后选择了如上的超参数,同时神经网络定义如下:
def get_net():
hidden_size = 256
net = nn.Sequential(nn.Linear(in_features, hidden_size), nn.ReLU(), nn.Linear(hidden_size, 1))
return net训练结果如下: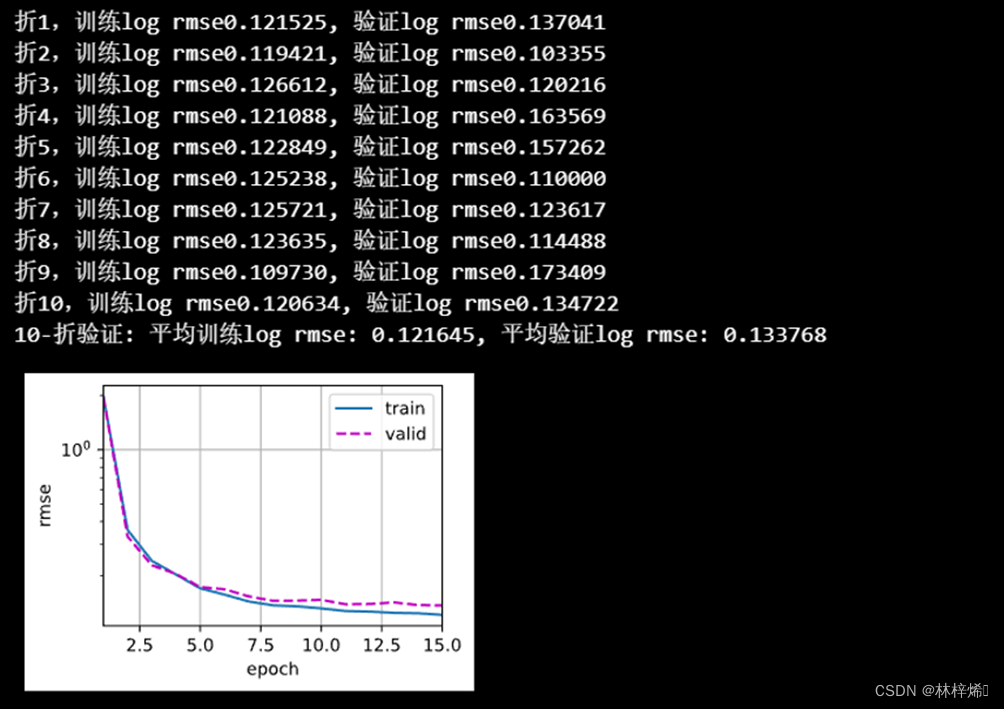
6. 训练并在Kaggle提交结果
将模型调至最优后,我们就可以开始进行预测了
使用训练函数对测试集进行预测,将预测结果的标签添加进测试集中再保存在submission.csv中,为了在提交前查看我们的模型预测性能如何,我们可以打印出训练损失,并绘制出图形方便观察
训练结果:
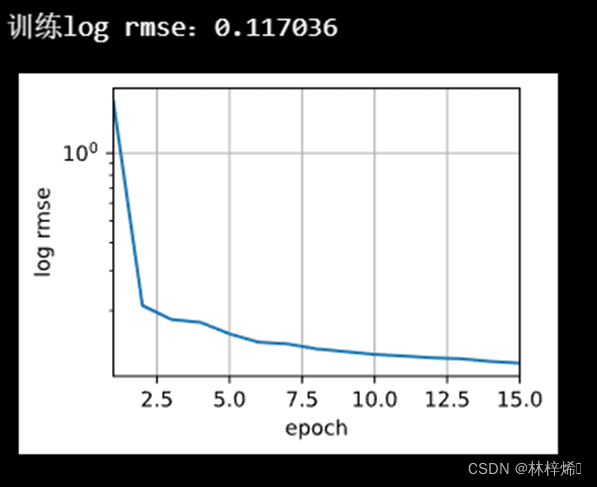
提交到Kaggle得分:

四、总结
多层感知机实现的大致步骤为获取数据集、初始化模型参数(通常将权重初始化为标准差为0.01均值为0的正态分布,偏置初始化为0)、定义激活函数(一般使用ReLU函数)和损失函数、定义网络模型(本次实验为线性回归模型),基本与线性回归和softmax回归模型一样,只是多层感知机的网络层数更多(本次实验添加了隐藏层),不过之前的学习中在实现时为了让我们了解多层神经网络的流水线操作,也使用了多层感知机的网络模型。
多层感知机比之之前添加了隐藏层,隐藏层提取输入层中的部分特征,再通过激活函数对输入进行非线性变化,使得模型能够处理更加复杂的问题,隐藏层的大小设置需要多次测试,较大的隐藏层可以提取到更多的参数,能学习到更多的特征,能更好的拟合训练数据,但如果隐藏层太大也可能导致过拟合,因此隐藏层的大小要适度,通过多次测试来选择最佳值,隐藏层的数量同样需要多次测试来选择。
对模型调优是一个非常枯燥的过程,我们需要多个参数进行联合条件,在大量的测试后得到最佳的结果,在第3节中预测房价就需要对模型根据K折交叉验证的结果进行不断的调优来得到一个最佳的模型,以期得到更高的分数,目前学习的比较浅,对模型的调优理解并不深刻,因此最终调出来的结果还是不太尽人意,希望在后续的学习中能不断深入理解,得到更好的结果。















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









