







Transformer是2017谷歌提出的一篇论文,最早应用于NLP领域的机器翻译工作,Transformer解读,但随着2020年DETR和ViT的出现(DETR解读,ViT解读),其在视觉领域的应用也如雨后春笋般渐渐出现,其特有的全局注意力机制给图像识别领域带来了重要参考。但是transformer参数量大,训练/推理耗时也是它的一大特点,NLP领域中,一个模型的参数量基本都是十亿量级。如何将transformer应用在图像领域并且轻量化是本篇博客的重点。我收集了近期4篇论文,DeiT(2020),ConViT(2021),Mobile-Former(2021)和MobileViT(2021)。它们的参数量及在ImageNet数据集上top1性能对比情况如下:

1、DeiT
DeiT是Fackbook在2020年底发表的一篇利用Transformer来进行图像识别的网络模型,是基于ViT的一种改进,之前训练Transformer需要数亿张图像进行预训练,但是作者通过改进,利用ImageNet数据就可以进行训练,而且只需要利用一台电脑在训练不到3天的时间,可以达到ImageNet top1为83.1%的精度。而且作者还提出了一种模型蒸馏策略。
论文地址:https://arxiv.org/abs/2012.12877
总之,该论文的主要贡献有如下三点:
1 、仅使用 Transformer,不引入 Conv 的情况下也能达到 SOTA 效果。
2、 提出了基于 token 蒸馏的策略,针对 Transformer 蒸馏方法超越传统蒸馏方法。
3、 DeiT 发现使用 Convnet 作为教师网络能够比使用 Transformer 架构效果更好。
对ViT的改进
作者在基于ViT的基础上,在多头自注意力层(MSA layer)后添加了FFN,FFN由两个带GeLu激活层的全连接层组成,全连接层节点数由D变成4D,然后由4D变回D;MSA和FFN都带有残差结构和layer normal。和ViT一样,图片也被分成196个16x16的图像块,然后图像块被拉成3x16x16=768的序列进入网络。
Distillation through attention
模型蒸馏,需要一个教师模型指导学生模型学习,作者将强图像分类器作为教师模型,它可以是纯卷积模型,也可以是同时包含卷积和transformer的混合模型。作者列出了两种可选的蒸馏对比方式,soft distillation和hard distillation,经典方式蒸馏和token蒸馏。
Soft distillation示意图如下所示:
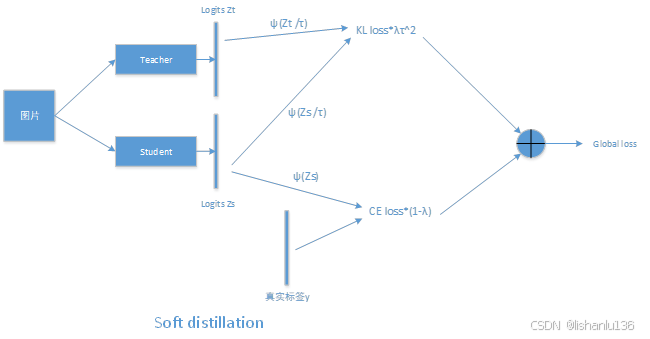
可用公式表示为:
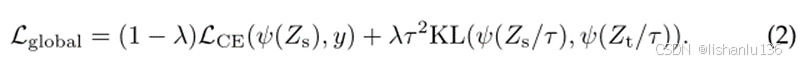
Hard distillation示意图如下所示:
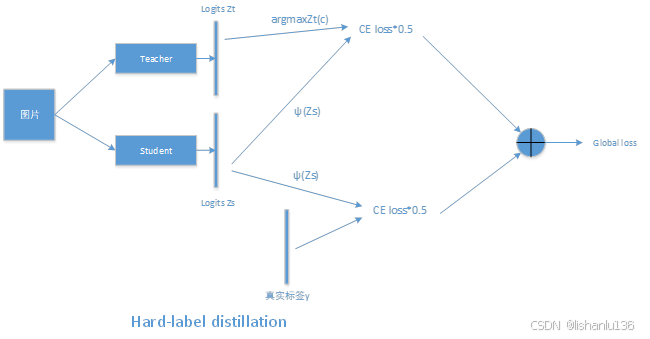
可用公式表示为:
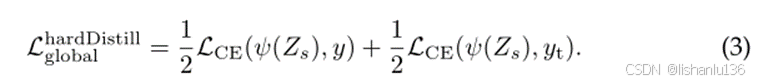
作者采用的方式是以hard distillation方式蒸馏token的方式,通过在输入端新增一个distillation token(类似于class token),通过transformer结构的更新学习,强迫该token去近似teacher的hard label。具体框图如下所示:
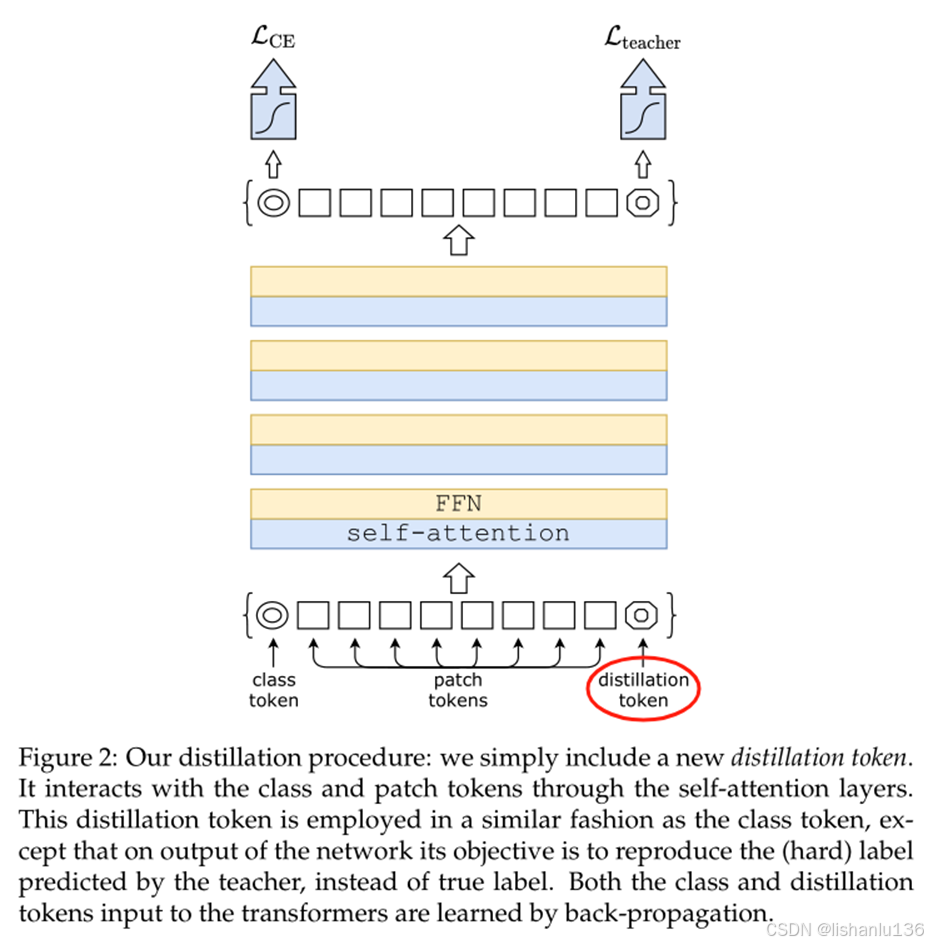
实验
DeiT模型自身训练与使用不同方式蒸馏在ImageNet数据集上top准确率对比情况如下表:
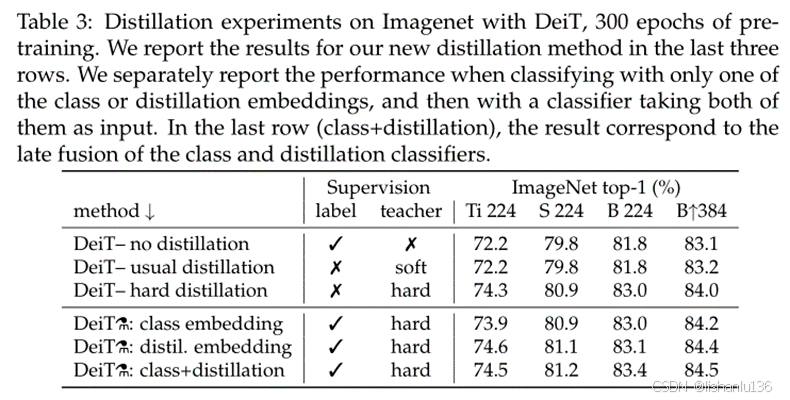
可以看到,模型规模在准确率上差距较大,通过蒸馏方式能进一步提升模型准确率。
DeiT与其他模型在ImageNet数据集上准确率对比情况如下表:
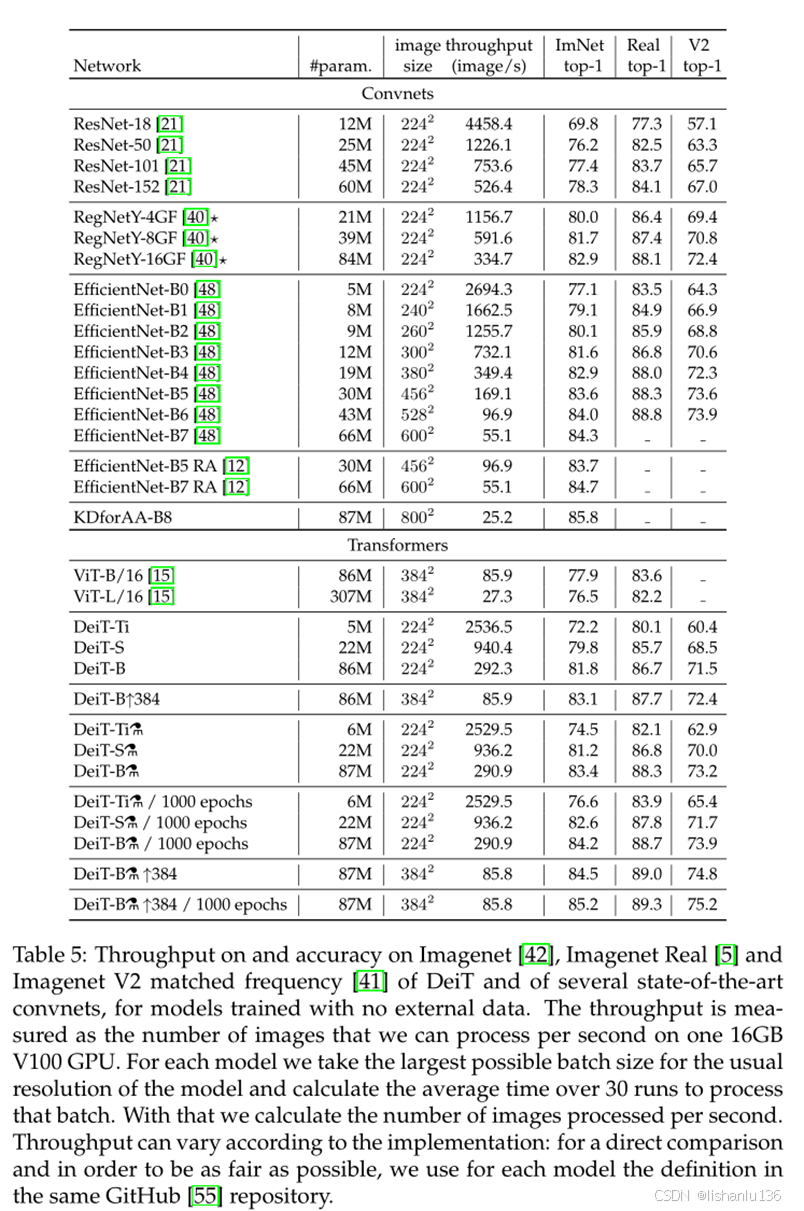
2、ConViT
论文地址:https://arxiv.org/abs/2103.10697
代码地址:https://github.com/facebookresearch/convit
这篇论文是fackbook在2021年提出的,作者总结到过去的卷积神经网络之所以成功是因为卷积操作拥有归纳偏置的能力,但卷积神经网络的表达能力有限,且近几年随着transformer在图像领域的应用,因其全局自注意力结构,它表现出来的能力趋势逐渐赶超卷积神经网络,但是它需要用大量数据进行预训练,transformer没有归纳偏置能力,如何将两者结合其他,是这篇论文的关注点。
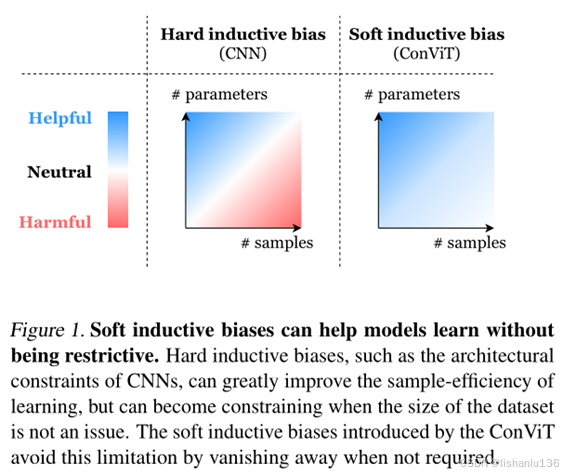
软归纳偏置
虽然卷积约束可以在小数据情况下实现强大的样本训练效率,但由于数据集大小不是问题,它们也会受到限制。在数据集丰富的情况下,硬归纳偏差可能过于严格,学习最合适的归纳偏差可能更有效。所以卷积神经网络模型具有较高的性能下限,但由于硬归纳偏差,它的性能上限可能较低,而基于transformer结构的模型,由于需要大量的数据量,且在数据量少的情况下,性能较差,所以它具有较低的下限,但天花板较高。
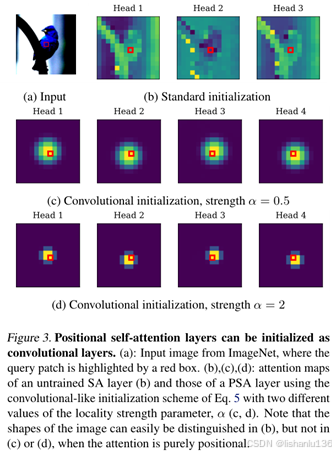
本篇论文主要贡献就是提出了一种新的SA层(self-attention),门控自注意力层(gated positional self-attention, GPSA),它可以初始化为卷积层。然后,每个注意头都可以通过调整一个测量参数来自由地恢复表达能力。如下图(b)是SA层按原本初始化方式出来的特征图,(c)和(d)是按不同局部强度参数得到的卷积方式初始化得到的特征图,可以看出,在(b)图中,可以很容易区分出目标形状,而且©和(d)这种关注局部位置的特征图中不能区分目标形状。所以作者在ViT的基础上,将某些SA层替换成带有卷积操作这种能重点关注局部位置信息又不丢失原本SA层自带的全局注意力优势的操作,也就是GPSA。
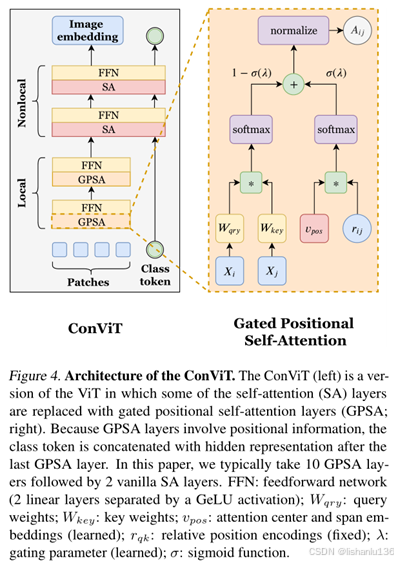
下图是ConViT结构(左图)及作者提出的GPSA结构(右图)
在官方代码中,作者直接替换了ViT中的前10个Block中的MHSA结构为GPSA,如下:

Block具体代码实现如下,为注意力模块加一个FFN,其中它们的输入都是经过layer normal的,注意力模块和FFN都是接了一个shortcut结构。

实验
作者将ConViT和DeiT进行对比,分别比较了性能和样本利用率,模型性能是从参数数量、flops和吞吐量以及ImageNet上top1及top5这些方面评估,如下表所示:
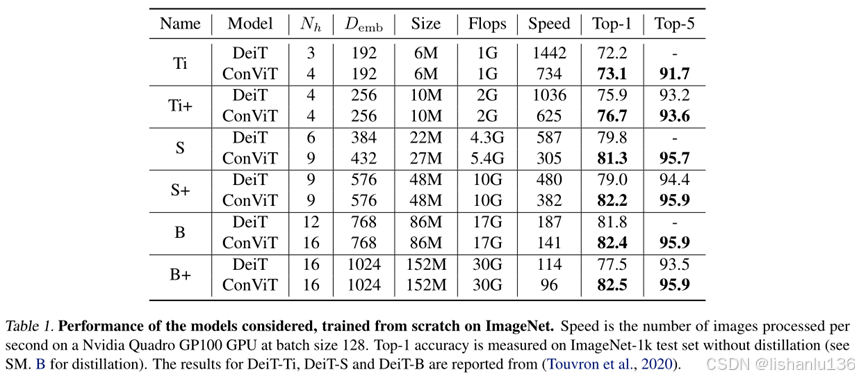
可以看到,每个ConViT的性能都比相同大小和相同flops次数的DeiT要好得多。重要的是,尽管位置自注意力层(GPSA layer)确实降低了ConViT的吞吐量,但在相同吞吐量下,它们的性能也优于DeiT。
样本利用率通过对ImageNet-1k数据集的每一类按如下比例f={0.05, 0.1, 0.3, 0.5, 1}进行子采样,同时将epoch数乘以1/f,使呈现给模型的图像总数保持不变。
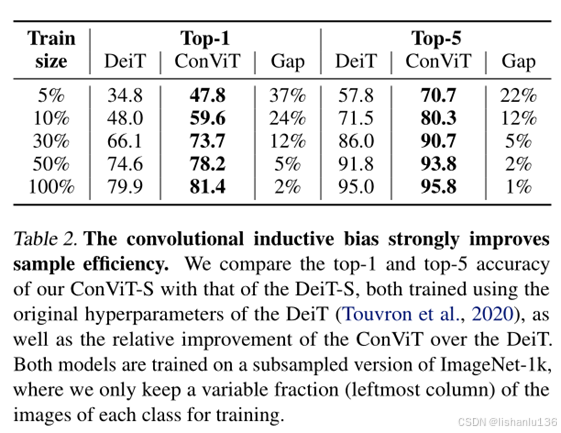
可以看到,相同比例的训练数据下,ConViT比DeiT都高很多,而且数据量越小的情况下,高得越多,所以可以看出,ConViT比DeiT对训练图片的利用率更好。
3、Mobile-Former
论文地址:https://arxiv.org/abs/2108.05895
这是一篇微软和中国科学技术大学联合发布的论文,他们提出了一种叫Mobile-Former的网络结构,它是一种MobileNet和transformer的并联设计,中间有一个双向桥。这种结构融合了MobileNet在局部区域提取特征和transformer在全局交互方面的优势。与最近的vision-transformer不同,Mobile-Former中的transformer包含很少的token数量(例如6或更少的token),这些token被随机初始化以学习全局先验,从而降低了计算成本。并且Mobile-Former具有很高的计算效率和更强的特征表达能力。相比于低Flops同规模的MobileNetV3,Mobile-Former以294M Flops实现ImageNet top1 77.9%,超过MobileNetV3 1.3%,且节省了17%的计算量。
本论文的关注点是如何设计一个高效的网络结构,使得有效的结合局部特征提取能力和全局注意力交互。Mobile-Former的网络结构如下图所示:
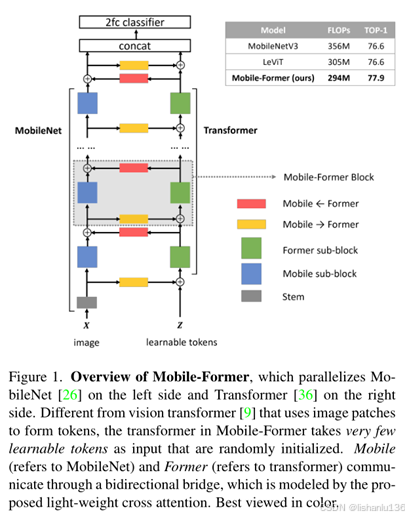
Mobile和transformer通过双向桥进行通信,融合局部特征和全局注意力特征。这个双向特征融合是至关重要的,因为它为transformer的tocken提供了局部特征细节,并为Mobile中的每个特征图像素引入了全局注意力。作者通过(a)在通道数量较少的移动瓶颈处执行交叉注意,(b)去除projection层的查询、键和值(query, key, value)权重,提出轻权重交叉注意来建模该双向桥。
Mobile-Former Block的具体结构细节如下:
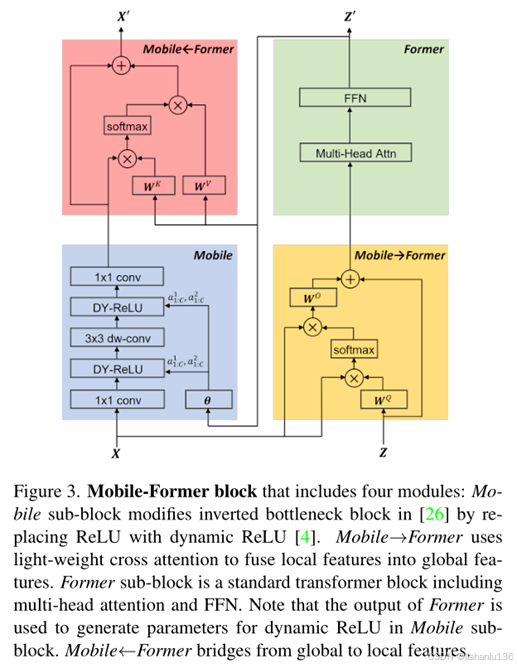
Mobile子结构取自MobileNetV2的倒置瓶颈block,将ReLU激活层调整为动态ReLU;Former子结构取自标准transformer的block,它包含多头注意力block和FFN,相对于vision transformer结构,这里的Former子结构减小了token数量,论文中取小于6的值,这个改变大大减小了计算量。
Mobile-Former的整体结构,对于输入为224x224的图片,整个模型包含11个Mobile-Former block,其Flops是294M左右。
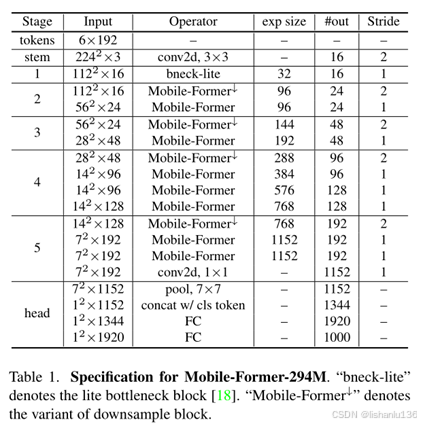
另外,作者也通过变换不同的宽度和深度,得到Mobile-Former不同规模的变体网络结构,总共包含7个,Flops数量从26M到508M不等。
实验
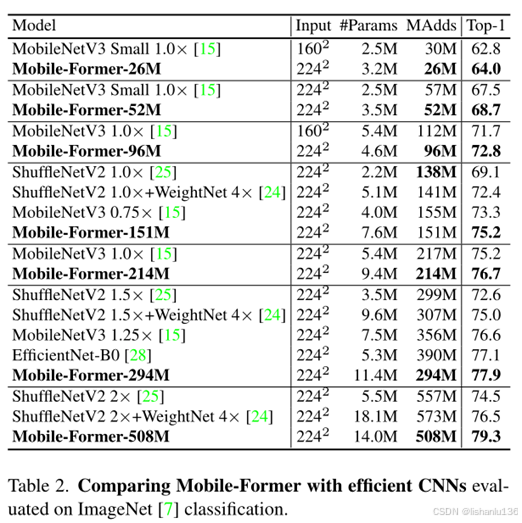
Mobile-Former与其他高效CNN分类模型在ImageNet数据集上性能比较:
Mobile-Former与其他Vision Transformer分类模型在ImageNet数据集上性能比较:
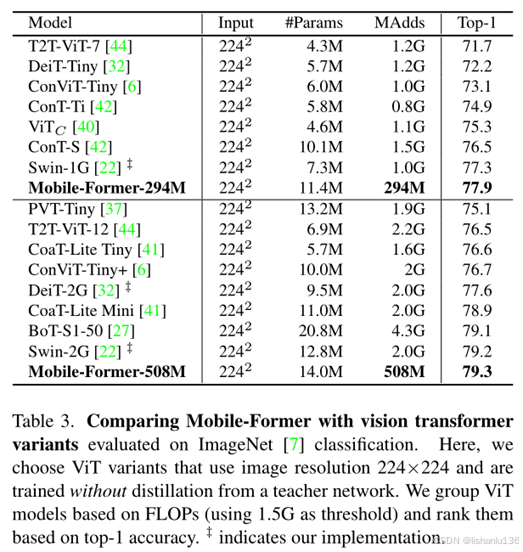
Mobile-Former与其他CNN模型以及Vision Transformer的变体模型在Accuracy-Flops对比曲线图如下所示:

可以看出,同等flops数量下,Mobile-Former相对于其他模型的accuracy都高,同等accuracy下,Mobile-Former模型的flops数量最小。
限制
虽然Mobile-Former在大图像推理时,比MobileNetv3快,但随着输入图像尺寸减小,它的推理速度也会变慢,如下图所示,随着图像分辨率的降低,Mobile-Former在MobileNetV3面前失去了领先地位。
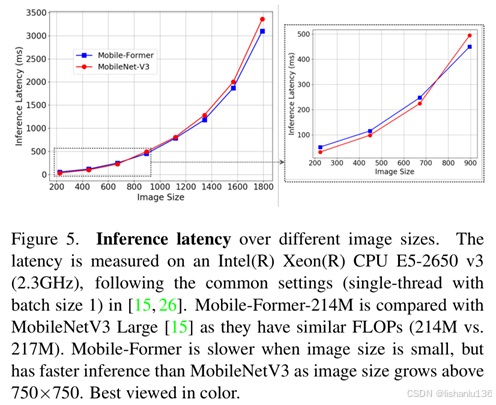
这个现象作者把它归因于Mobile->Former,Mobile<-Former的pytorch实现相对于conv的实现不高效,随着输入图像分辨率增加,这里的差距逐渐忽略掉了,但若图像分辨率减小,这个差距就凸显出来了。
另一个限制是作者认为Mobile-Former的分类结构参数不高效,Mobile-Former分类模型拥有”太重”的分类头,比如Mobile-Former-294M的分类模型,其分类头在总共1140万个参数中占了460万个(40%)。当切换到目标检测时,由于去除了图像分类头,这个问题才得到了缓解。
4、MobileViT
论文地址:https://arxiv.org/abs/2110.02178
论文标题已经表明了,MobileViT是轻量的,通用的,移动端友好的vision transformer。和前面的ConVit、Mobile-Former一样,MobileViT也是将轻量型CNN网络结构的局部特征提取能力与transformer的全局注意力优势相结合。CNN网络由于其空间归纳偏置的优势,可以使用较少的参数得到较好的特征表达,但是CNN在空间层面只能提取局部特征;相反,transformer可以提取全局信息,但是它参数量很大,所以作者想结合两者优势,设计出既轻量又低延时且适合移动端的网络结构。最终,MobileViT在相同级别Flops数的模型对比中,在ImageNet-1k数据集上表现超过了MobileNetv3和DeiT。
下图是MobileViT和标准的ViT网络结构的对比:
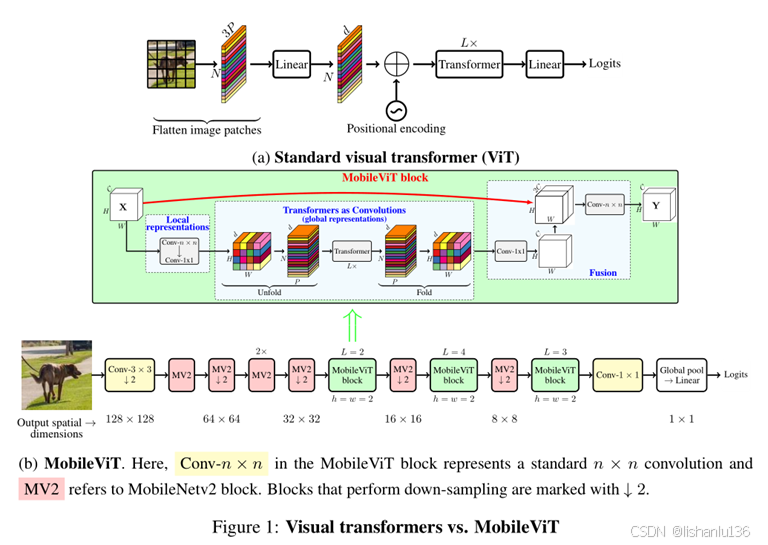
MobileViT同时包含CNN和transformer结构,主要由卷积,MV2,MobileViT block,全局池化以及全连接层组成,其中MV2就是MobileNetv2的倒置瓶颈模块,标有↓2的模块代表着步长stride设置为2。
MobileViT block就是本论文的核心创新点。其详细结构如上图中绿色框部分,主要由卷积、Transformer,残差连接组成。
MobileViT减少参数量和计算复杂度的设计思路在于MobileViT block中的transformer结构使用了“unfold-transformer-fold”。标准的vision transformer结构,如上图(a)中,对于一个输入X∈RHxWxC,会被拉伸成一个序列Xf∈RNxPC,这里P=w*h代表图片块的大小,N代表图像块的数量;接着被映射成d维的Xp∈RNxd,然后使用L个transformer block堆叠学习patch块之间的表示。而“unfold-transformer-fold”操作,它对token进行self-attention时,只与对应的token进行计算,不对其他块进行计算。因为作者认为相邻像素的区域具有相似性,且在进行“unfold-transformer-fold”操作之前,作者对图像进行了nxn以及1x1的卷积操作,使得在做self-attention之时对应图像块已经包含了相邻像素区域的局部信息,不对相邻区域进行计算,可以减少计算量又能保证提取到全局区域特征。
如下图所示,在MobileViT block中对红色中间像素进行self-attention,可以关注到其他相邻蓝色像素点的信息。

这也算是在做self-attention操作时,为了减小计算量,但是又保证了全局感受野大小的方式吧,看图有点像空洞卷积的意思,空洞卷积也是保证参数量不增加的情况下,增大了卷积操作的感受野。
实验
MobileViT和其他CNN轻量型模型在ImageNet数据集上对比情况如下:

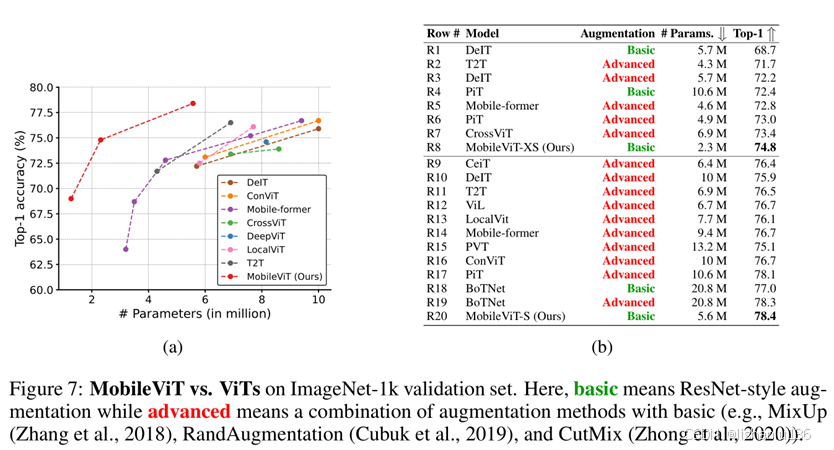
MobileViT和其他ViT变体模型在ImageNet数据集上对比情况如下:


















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









