









介绍
搜狗语料库(http://www.sogou.com/labs/resource/list_yuliao.php)是可以免费获取的比较大的中文新闻语料库。可是最新的也就是更新到2012年的语料,后续并无放出更新的语料。除了搜狗语料,要获取其余领域相关的中文语料,可能就须要本身动手写个爬虫去相关网站上爬取。后面经过检索,发现可以使用免费的中文维基百科来进行词向量的训练,因而我也下载处理了最新的维基语料,使用word2vec工具进行了中文词向量的训练。
1使用维基百科训练简体中文词向量
1.1下载中文维基百科
wiki语料库下载网址:https://dumps.wikimedia.org/
最近的中文wiki语料:https://dumps.wikimedia.org/zhwiki/latest/spa
其中zhwiki-latest-pages-articles.xml.bz2文件包含了标题、正文部分。压缩包大概是1.3G,解压后大概是5.7G。相比英文wiki中文的仍是小了很多。
2021年的:https://dumps.wikimedia.org/zhwikisource/20211120/
 注意:文件名在网站中的结尾为xml.bz2
注意:文件名在网站中的结尾为xml.bz2
1.2 抽取wiki正文内容
1.2.1开源工具wikipedia extractor完成正文的提取
下载下来的wiki是XML格式,须要提取其正文内容。不过维基百科的文档解析有很多的成熟工具(例如gensim,wikipedia extractor等),我直接使用开源工具wikipedia extractor完成正文的提取。
Wikipedia extractor的网址为: http://medialab.di.unipi.it/wiki/Wikipedia_Extractor
Wikipedia Extractor 是一个简单方便的Python脚本,下载好WikiExtractor.py后直接使用下面的命令运行便可。
WikiExtractor.py -cb 1200M -o extracted zhwiki-latest-pages-articles.xml.bz2
-cb 1200M表示以 1200M 为单位切分文件,-o 后面接出入文件,最后是输入文件。
1.2.2 gensim提取
1.3 简繁转换
1.3.1厦门大学NLP实验室开发的简繁转换工具
中文wiki内容中大多数是繁体,这须要进行简繁转换。我使用了厦门大学NLP实验室开发的简繁转换工具,该工具使用简单方便效果也很不错。下载网址为:http://jf.cloudtranslation.cc/
下载单机版便可,在windos命令行窗口下使用下面命令行运行:
jf -fj file1.txt file2.txt -lm lm_s2t.txt
其中file1.txt为繁体原文文件,file2.txt为输出转换结果的目标文件名,lm_s2t.txt为语言模型文件。
1.3.2使用opencc将繁体txt转换为简体txt
下载地址:
https://bintray.com/package/files/byvoid/opencc/OpenCC
无需安装,解压便可使用
将咱们前面生成的wiki.zh.text拖动至opencc-1.0.1-win64文件夹中,打开cmd并在当前文件夹中输入以下指令:
opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json
这一步骤很是快,我只用了1分钟不到
而后能够看到目录中生成了wiki.zh.jian.text文件
打开后能够查看其中内容
能够看到已经成功所有转化为了简体字
可是作词向量训练以前仍缺乏最后一步,就是分词
1.4 处理空括号
因为 Wikipedia Extractor 抽取正文时,会将有特殊标记的外文直接剔除,最后造成一些空括号,本身去掉了这些空括号。
1.5 训练词向量
将前面获得的中文语料使用jieba分词工具(https://github.com/fxsjy/jieba)进行了分词,而后使用word2vec工具进行了训练,使用参数以下:
-cbow 0 -size 50 -window 10 -negative 5 -hs 1 -sample 1e-3 -threads 24 -binary 0 -iter 10
2基于gensim的word2vec实战
第一节获得了zhwiki_2017_03.clean这个文件
2.1读取数据
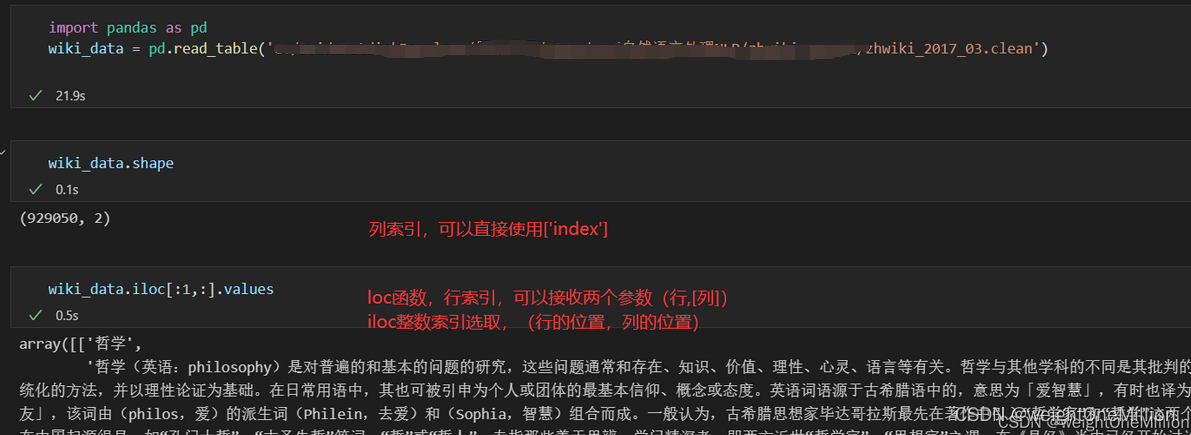
可以看出,数据样本为,关键字-详细解释,两个维度。共有92W条数据。
2.2数据预处理
先用正则去除文本中的标点符号,在结合结巴分词工具进行分词。
这里默认采用结巴的精准分词。也可以根据不同情况,采用全分词策略。
#先用正则去除文本中的标点符号
r = re.compile("[\s+\.\!\/_,$%^*(+\"\']+|[+——!;「」》::“”·‘’《,。?、~@#¥%……&*()()]+")
import pandas as pd
# 加载停用词
stopwords = pd.read_table('stopwords.txt',header = None).iloc[:,:].values
# 去除停用词
def stopword_filter(stopwords,seq_words):
filter_words_list = []
#停用词过滤
for word in seq_words:
if word not in stopwords:
filter_words_list.append(word)
return filter_words_list
head = ["分词结果"]
to_csv_content = []
# 遍历wiki_data的92万多条数据
for i in range(wiki_data.shape[0]):
#以下两行过滤出中文及字符串以外的其他符号
sentence = r.sub('',str(wiki_data.iloc[i,0])) #i行0列,关键字,注意iloc使用的是方括号
seg_list = jieba.cut(sentence)
# to_csv_content.append(" ".join(seg_list))
seq_words = " ".join(seg_list).split(' ')
#去除停用词
to_csv_content.append(stopword_filter(stopwords,seq_words))
参考博主的这里,是将to_csv_content保存到csv文件中,我做这一步的时候,遇到了点错误,还不太理解,为了后续的操作,先暂时不保存了
2.3模型训练
word2vec总共有两种训练方法,cbow 和 skip-gram,以及两种方式的损失函数构造
有个值得注意的地方就是:
Make sure you have a C compiler before installing gensim, to use optimized (compiled) word2vec training
否则采用gensim框架训练模型的时候会事件会很长。
from gensim.models import word2vec
model=word2vec.Word2Vec(content)
2.4 模型的加载与保存
#模型保存以及模型加载
model.save('word2vec_out/word2vec.model')
model = word2vec.Word2Vec.load('word2vec_out/word2vec.model')
2.5 预测
例如
 例如
例如

关键词不存在,会报keyError错误
参考
使用维基百科训练简体中文词向量:http://www.noobyard.com/article/p-cogkoxjj-kq.html
【Python3】基于Gensim的维基百科语料库中文词向量训练:http://www.noobyard.com/article/p-xwtyiaci-ey.html
基于gensim的word2vec实战:https://www.jianshu.com/p/5f04e97d1b27















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











