







langChain是一个AI开发细节封装框架,可以让你非常方便的在Python和java环境下进行AI应用开发。传统的文本检索设计方案一般都是使用数据库进行模糊匹配或者使用更先进的ES等中间件进行更高效的文本模糊检索功能。这种检索方式还是依赖传统的用户输入文本,对其进行合理分词,然后再去系统中进行部分字词的模糊匹配目标文档。然而这种检索方式对文本相似性检索却无能为力,比如包含近义词或含义相似的文档就检索不到了。实际上用户可能非常需要将其一并查询出来工用户参考。随着人工智能领域突飞猛进的发展,这一技术性问题也变得可以成为现实了。主要得益于文本相似度识别技术的发展。
通过训练一个文本相似度识别的大模型,配合向量数据库相似度匹配检索能力,我们就能轻而易举的对用户输入文本和目标相似文本之间的查询匹配了。这可以大大将传统文本数据检索应用提升到一个新的高度,具备一定的智能属性。也极大的提高了用户的使用体验。以下我们将在Python和java两种开发环境下实现一个入门级案例。
文本嵌入模型本地部署
文本嵌入模型也是像大语言模型LLM那样需要经过训练得到的。只不过文本嵌入模型的作用仅限于识别目标文本在高维向量空间的分布状态。输入一段文本,模型返回其向量数值。
下载Ollama工具
去Ollama官网:Ollama 下载最新版本的Windows安装包,安装到本地就行。如果下载很慢,可以去其他国内网站下一个。安装后默认就启动了,会在桌面右下角有个服务图标,下载或导入的模型自动就处于可用状态了。

模型选取
去Ollama官网的“Models”菜单里找个文本嵌入模型,这里有很多模型,主流开源的都在里面,还有各种网友自己经过微调训练的模型。输入“embed”关键字搜索模型,你可以看到非常多的文本嵌入模型可以安装使用
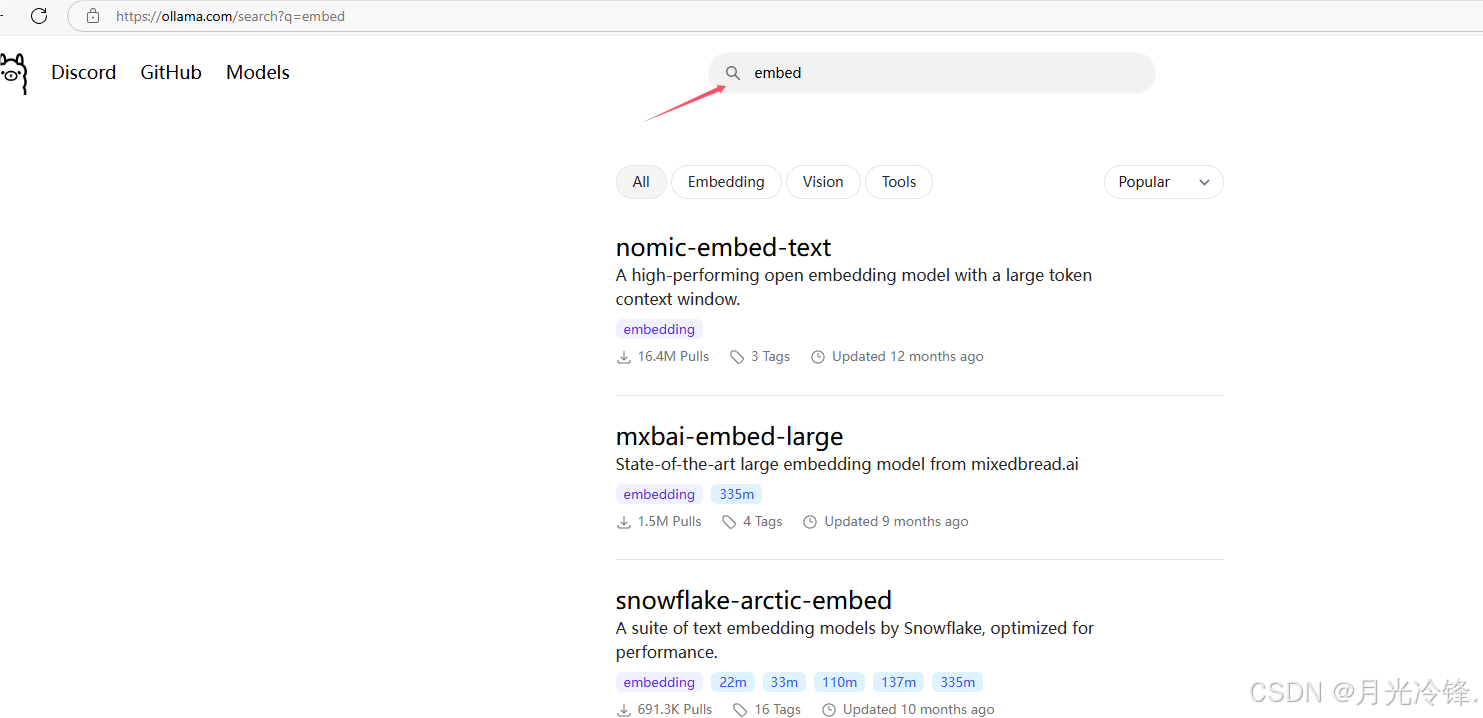
这里我们选择“lrs33/bce-embedding-base_v1”模型进行在线下载并导入到ollama模型管理服务中即可。该模型文件大小500+MB还算比较适合,在线下载也不会太慢。
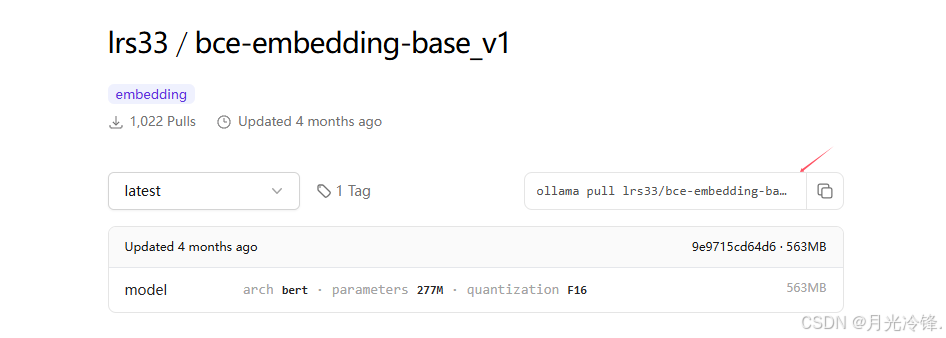
上图复制模型的CMD安装命令到本地命令窗口安装即可。安装过程有下载进度显示。
C:\Users\xxx>ollama pull lrs33/bce-embedding-base_v1
下载完成后,使用命令:ollama list 可以查看本地ollama服务管理的所有可用模型

安装向量数据库
向量数据库是用来存储文本的向量表示的数据库,搜所目标文本时先获取其向量值,然后传递给向量数据库进行相似度/关联性查询库里的文本或文本的向量。向量数据库也有很多种,这里我们使用Chroma,它是使用Python语言编写的,你需要本地有Python开发环境才行。使用如下CMD命令将其安装到本地即可。
C:\Users\xxx>pip install chromadb
安装成功的话,你的Python库文件目录下会出现chroma的相关文件如下图所示。并且在CMD命令窗口输入:chroma run 可以手动以服务方式启动向量数据库。
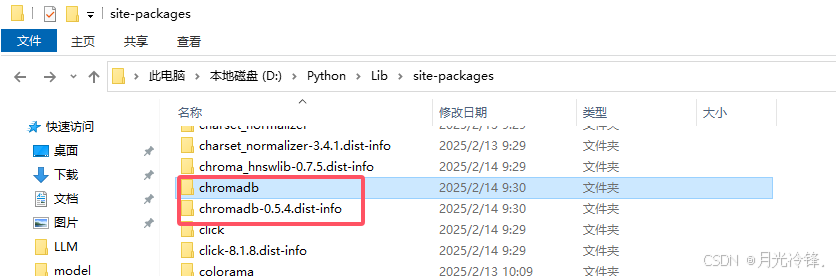
启动后chroma会显示启动信息,其中还给出了数据库的http服务访问地址:http://localhost:8000 以及数据库的数据文件存放地址:./chroma_data (在当前用户目录下)
使用langChain框架开发检索增强功能
安装Python环境的langChain开发库
首先确保本地已经安装好了Python开发环境,然后安装langChain库即可。打开CMD命令窗口输入:pip install langchain 执行后pip工具就会自动将组件下载到你本地Python库里。如果需要指定版本则输入:pip install langchain==0.3.0 当前我的测试机安装的是这一个版本,因为在使用过程中遇到最新版本API不熟悉问题,导致运行demo时各种报错。

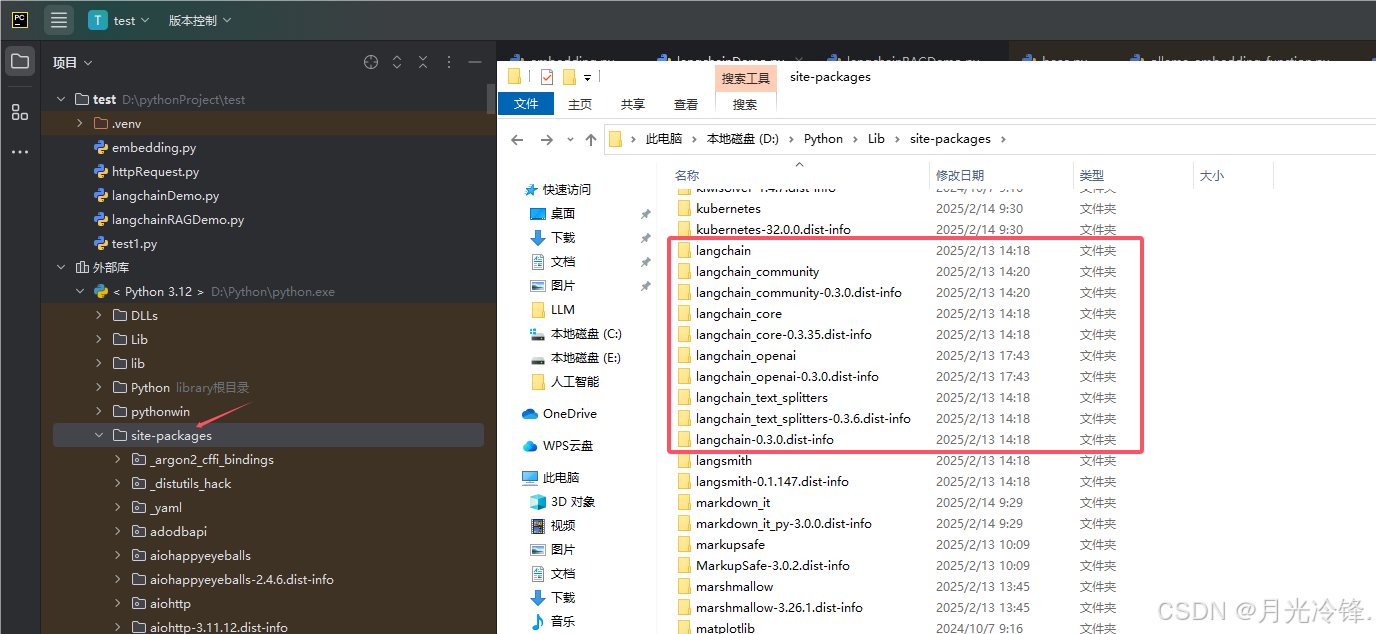
安装完后,可以在你开发工具PyCharm中的外部库“site-packages”中查看是否安装好,也可以在Python安装目录下查看,如下图所示。
安装java环境的langChain开发库
langChain在java开发环境下对应的组件是langChain4j,为方便java环境开发专门做的移植。可以在Maven仓库:https://mvnrepository.com/artifact/dev.langchain4j 中查看所有版本及其他子模块的依赖配置。需要注意的是最新版本可能需要你本地JDK版本在8以上,但是如果公司只能依赖低版本的JDK的话,只能选用0.35.0版本了,不然启动就会报版本错误。
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>0.35.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-chroma -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId>
<version>0.35.0</version>
</dependency>开发一个文本相似性/关联性查询的功能
Python开发示例
Python环境下这里不需要单独启动chroma了在命令窗口。因为chroma本身就是Python写的,且在Python的开发库里,直接运行代码会自动启动了。
from chromadb.utils.embedding_functions.ollama_embedding_function import OllamaEmbeddingFunction
import chromadb
# 使用chroma集成了Ollama模型服务管理的接口,调用文本嵌入模型
embed_model= OllamaEmbeddingFunction(url="http://localhost:11434/api/embeddings", model_name="lrs33/bce-embedding-base_v1")
# 定义几段模拟文本作为测试用,文本之间有一定的相似性或关联性
documents = [
"你好吗",
"你的名字是什么",
"我的肚子好痛啊",
"肠胃不舒服",
"我在吃东西"
]
# 批量获取每个文本段的向量值
embeddings = embed_model(documents)
# 定义每个文本段的元数据,附属信息。可以随意点
metadata = [{"source": "A"}, {"source": "B"}, {"source": "C"},{"source": "D"},{"source": "E"}]
# 创建 ChromaDB 客户端
client = chromadb.Client()
# 创建一个集合,用于存储向量数据。相当于数据库的命名空间或表名
collection = client.create_collection(name="my_collection")
# 将上面文本的向量值、元数据及文本本身还有设置其对应的主键ID一起保存到向量库里
collection.add(
ids=["1","2","3","4","5"],
documents=documents, # 文本
embeddings=embeddings, # 对应的嵌入向量
metadatas=metadata # 附加的元数据
)
# 获取目标查询文本的向量值
query_embedding = embed_model("肠胃不舒服")
# 去向量数据库里搜索目标文本最相似/关联度高的文本
results = collection.query(
query_embeddings=query_embedding,
n_results=2 # 返回最相似的 2 个文档
)
# 输出结果
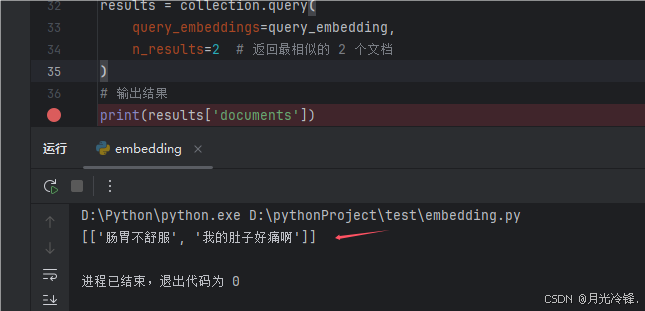
print(results['documents'])程序运行后结果如下所示,匹配到了两条最相似关联度高的目标文本。
Java开始示例
java环境下,需要启动chroma在命令窗口,否则就报访问失败。
// 使用Ollama文本嵌入模型专用接口
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder().baseUrl("http://localhost:11434").modelName("lrs33/bce-embedding-base_v1").build();
// 定义一些模拟文本段用于目标查询库查询用
List<TextSegment> textSegments = new ArrayList<>();
textSegments.add(new TextSegment("你好吗", new Metadata()));
textSegments.add(new TextSegment("你的名字是什么", new Metadata()));
textSegments.add(new TextSegment("我的肚子好痛啊", new Metadata()));
textSegments.add(new TextSegment("肠胃不舒服", new Metadata()));
textSegments.add(new TextSegment("我在吃东西", new Metadata()));
// 使用langChain的Chroma向量数据库调用接口
ChromaEmbeddingStore store = ChromaEmbeddingStore.builder().baseUrl("http://localhost:8000").collectionName("my_collection").build();
// 将文本段转换为其向量值表示,并存入Chroma库里面
textSegments.forEach(textSegment -> {
store.add(embeddingModel.embed(textSegment).content(), textSegment);
});
// 定义目标待查询的文本输入,并转换为其向量值表示
Response<Embedding> query = embeddingModel.embed("肠胃不舒服");
// 将目标文本向量传入Chroma搜索与最相似或关联度高的两条匹配结果
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder().queryEmbedding(query.content()).maxResults(2).build();
EmbeddingSearchResult<TextSegment> searchResult = store.search(request);
// 将查询结果打印出来
searchResult.matches().forEach(x -> {
System.out.println(x.embedded().text());
});
// 删除chroma当前集合里的向量数据。方便重复演示
store.removeAll();程序运行后结果如下所示,匹配到了两条最相似关联度高的目标文本。

大数据量搜索方案思考
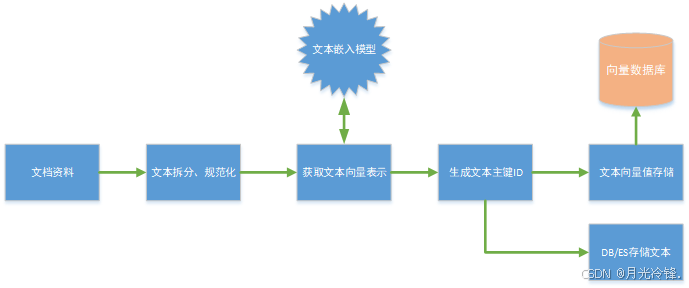
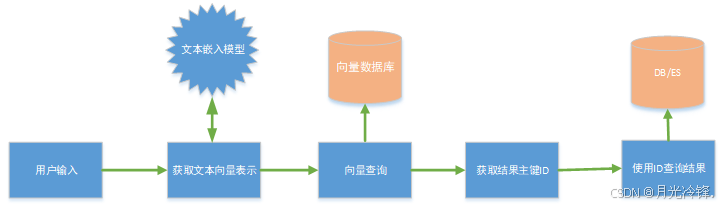
上面的示例中是将目标搜索文本直接存储到了向量数据库中,显然在海量信息场景中是不现实的。目前向量数据库都是单机模式下运行,不宜存储大量搜索文本信息。一个可行的办法是将文本原始数据仍然存储到传统的关系型数据库或ES中,将文本的向量值存储到向量数据库中即可。向量值是由一组浮点数表示的数组,占用空间不大。然后向量数据库里的向量存储和外部文本存储通过预先生成好的文本主键ID进行关联即可。这样进行搜索用户输入文本时,先去向量数据库里搜索相似的文本向量的主键ID,然后再用主键ID去传统的数据库或ES中进行再次查找即可。
企业数据文档资料录入系统处理流程:
用户输入查询处理流程:

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









