







2016年全球瞩目的围棋大战中,人类以失败告终,更是激起了各种“机器超越、控制人类”的讨论,然而机器真的懂人类吗?机器能感受到人类的情绪吗?机器能理解人类的语言吗?如果能,那它又是如何做到呢?带着这样好奇心,本文将带领大家熟悉和回顾一个完整的自然语言处理过程,后续所有章节所有示例开发都将遵从这个处理过程。
首先我们通过一张图来了解 NLP 所包含的技术知识点,这张图从分析对象和分析内容两个不同的维度来进行表达,个人觉得内容只能作为参考,对于整个 AI 背景下的自然语言处理来说还不够完整。
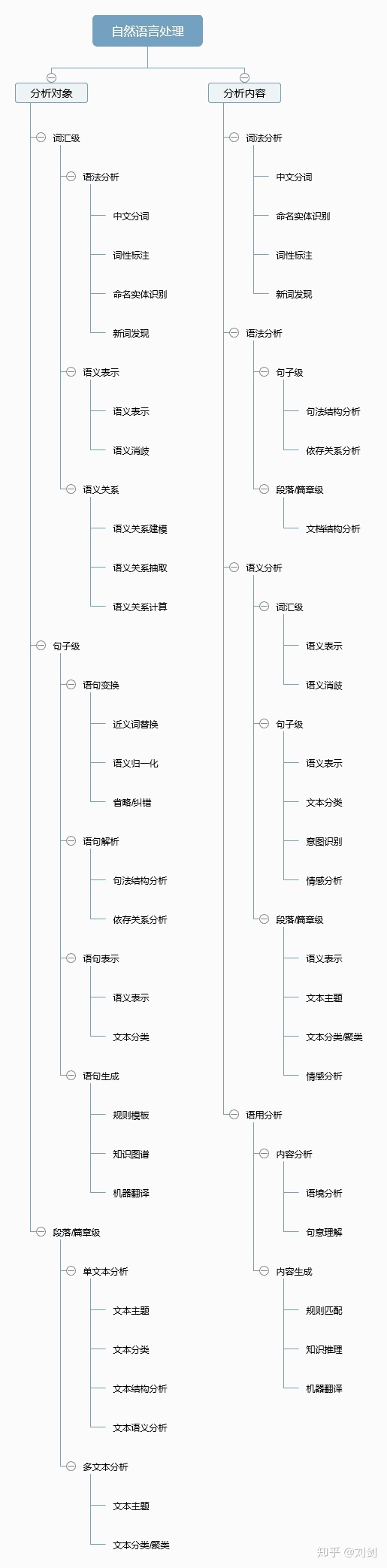
有机器学习相关经验的人都知道,中文自然语言处理的过程和机器学习过程大体一致,但又存在很多细节上的不同点,下面我们就来看看中文自然语言处理的基本过程有哪些呢?
获取语料
语料,即语言材料。语料是语言学研究的内容。语料是构成语料库的基本单元。所以,人们简单地用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的替代品。我们把一个文本集合称为语料库(Corpus),当有几个这样的文本集合的时候,我们称之为语料库集合(Corpora)。(定义来源:百度百科)按语料来源,我们将语料分为以下两种:
1.已有语料
很多业务部门、公司等组织随着业务发展都会积累有大量的纸质或者电子文本资料。那么,对于这些资料,在允许的条件下我们稍加整合,把纸质的文本全部电子化就可以作为我们的语料库。
2.网上下载、抓取语料
如果现在个人手里没有数据怎么办呢?这个时候,我们可以选择获取国内外标准开放数据集,比如国内的中文汉语有搜狗语料、人民日报语料。国外的因为大都是英文或者外文,这里暂时用不到。也可以选择通过爬虫自己去抓取一些数据,然后来进行后续内容。
语料预处理
这里重点介绍一下语料的预处理,在一个完整的中文自然语言处理工程应用中,语料预处理大概会占到整个50%-70%的工作量,所以开发人员大部分时间就在进行语料预处理。下面通过数据洗清、分词、词性标注、去停用词四个大的方面来完成语料的预处理工作。
1.语料清洗
数据清洗,顾名思义就是在语料中找到我们感兴趣的东西,把不感兴趣的、视为噪音的内容清洗删除,包括对于原始文本提取标题、摘要、正文等信息,对于爬取的网页内容,去除广告、标签、HTML、JS 等代码和注释等。常见的数据清洗方式有:人工去重、对齐、删除和标注等,或者规则提取内容、正则表达式匹配、根据词性和命名实体提取、编写脚本或者代码批处理等。
2.分词
中文语料数据为一批短文本或者长文本,比如:句子,文章摘要,段落或者整篇文章组成的一个集合。一般句子、段落之间的字、词语是连续的,有一定含义。而进行文本挖掘分析时,我们希望文本处理的最小单位粒度是词或者词语,所以这个时候就需要分词来将文本全部进行分词。
常见的分词算法有:基于字符串匹配的分词方法、基于理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









