







我们来搭建一个基于langchain的本地LLM,并且实现一个rag的检索增强器。原谅我就是这么单刀直入,没有废话。
至于那些工具我就不多介绍了,网上说了很多了,我们直接进入操作。
一、搭建ollama以及本地模型初试
我搭建本地模型使用的是ollama框架。我们可以去他的ollama官网去下载。
注意下载你对应的系统的版本,比如我的环境就是mac,所以我下载mac的就好了,然后就是安装,这个没啥说的,就是双击,然后按照提示来就行了,他会在最后安装完让你去你的终端去执行ollama run的命令。比如我这个就要执行。
ollama run llama3.2
然后我们就看到:

那么我们看到success之后我们就安装完了,我们接下来来安装模型。
你可以把ollama理解为一个架子,在这个架子上你可以轻松的运行很多模型在你本地。我们来看一下他有哪些模型可以跑。
我们点击ollama主页的models选项来看他支持的模型列表。

你能看到他支持各种模型,包括我们熟悉的deepseek只不过是r1的。然后他还有各种对模型的分类,Embedding(向量化的)Vision(视觉的)
Tools(工具类的),方便你选择,好了,我们来选一个模型试试,我们先选一个小一点的,别上来就搞大的。
我看了一圈看到一个qwen好像不错。而且他的1.8b参数的值需要1.1gb的占用,不算大,就他了。
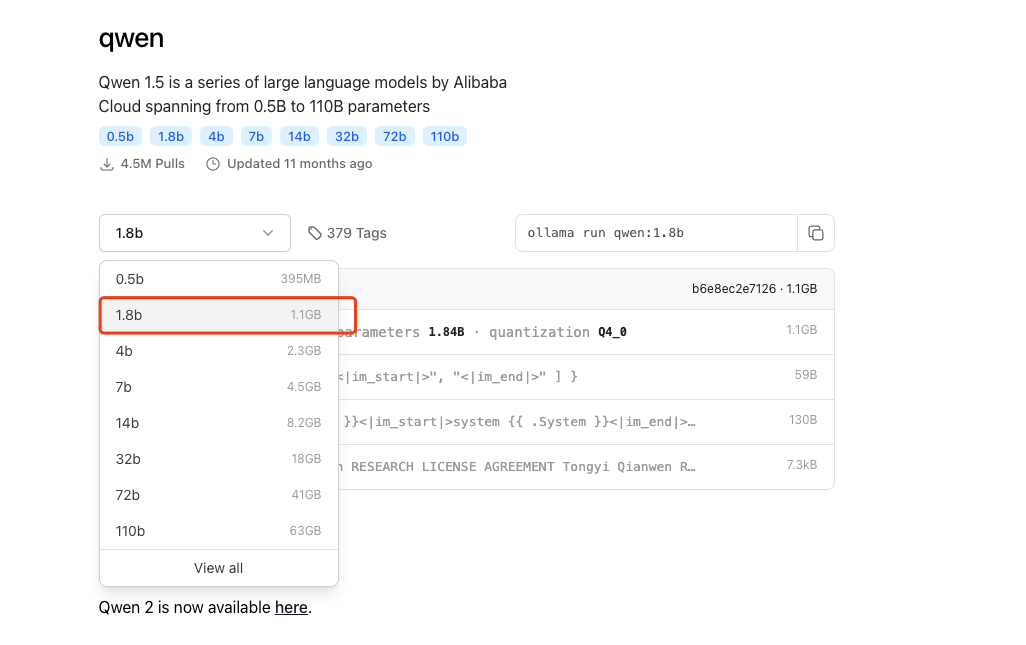
我们看到他后面跟了一句命令ollama run qwen:1.8b就是启动运行这个模型的。我们就来试试。
你会看到他去拉取对应的镜像了,当然你也可以直接取dockerhub拉取,这都有的。

ok,等到安装完成和之前一样是这样的。你可以问他一些问题,他会基于他当前的知识库来进行回答,你看到我问的哪吒2的票房的时候明显跟不上时代了。
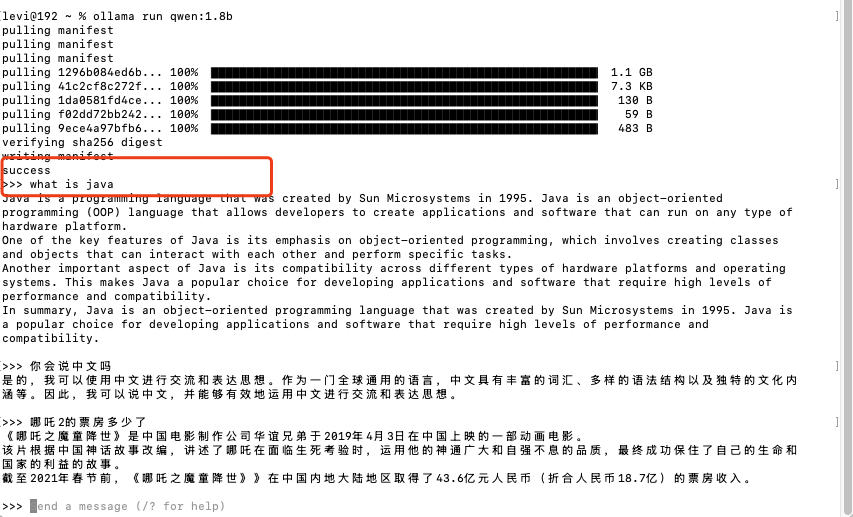
ok,我们这就算安装完了,就这么简单,你可以ctrl+d或者是输入/bye来退出这个chat交互界面,我们最好是整个页面啥的毕竟是给人用的,不是谁都会用shell的。好了我们退出即可,你还可以用ollama list来列出你当前安装的模型。
ollama list

你能看到我除了本地自带的那个,还展示了刚才我们安装的那个。只不过我现在就退出了,你要是想运行起来,再执行对应的run命令即可。只不过这时候就不用再下载了,是不是很像docker。
ok,至此我们就初步完成了模型的搭建,当然了,你选的模型越牛逼,参数越大效果就会越好,我们目前只用一个比较小的做个演示。或者我们可以来试试deepseek这个模型,作为国产之光,我们有必要看一下他的表现。我们就选择8b参数的即可,
ollama run deepseek-r1:8b
好吧,资料都不太新。不过写出来的代码不错。可以试试。

反正目前我们用模型没有喂数据,也没有rag都一般。后面看看怎么增强一下。
二、搭建客户端GUI
我们上面都是在shell上问的,假如我们想模拟gpt那种有个客户端页面咋做,在我们还没有用langchain对接那一堆api之前,我们可以使用一些三方的东西。比如gpt4all,还有msty。我们就用msty吧。点进去下载对应的平台即可。
下载安装之后会在底部检查你本地的所有模型。
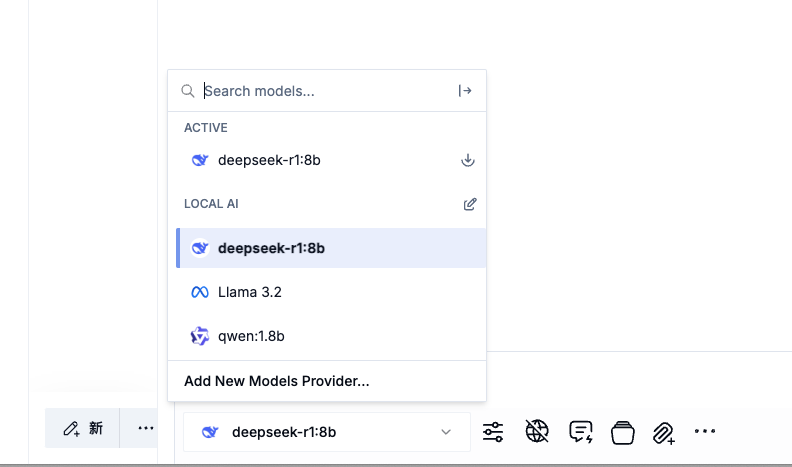
如果你检查不出来,就来到这里把它加载的都删了。然后重新加载你的ollama的部分。

ok,我们就选择我们ds r1 8b即可。然后你就可以直接问问题了。

当然msty的功能很多,还可以上传知识库文件等等,我们只是简单用来做个界面,后面我们用langchain来做后续的。
三、ollama的命令
其实你也看出来了估计,这玩意和docker很像,我们不妨用help看看他的命令。
levi@192 ~ % ollama help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
看起来flags也没几个参数,主要还是commands,好了基本和docker很像,我们就不多说了。
后面我们就来使用langchian来一步一步的往下走。

















 2599
2599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









