







① Semantic Images Segmentation with Deep Convolutional Nets and Fully Connected CRFs (DeepLab-v1) (CRF:概率图)
② DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLab-v2)
③ Rethinking Atrous Convolution for Semantic Image Segmentation (DeepLab-v3)
④ Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (DeepLab-v3+)
- ① Semantic Images Segmentation with Deep Convolutional Nets and Fully Connected CRFs (DeepLab-v1) (CRF:概率图)
- ② DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLab-v2)
- ③ Rethinking Atrous Convolution for Semantic Image Segmentation (DeepLab-v3)
- ④ Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (DeepLab-v3+)
语义分割主要面临的挑战:
-
分辨率
连续的池化、卷积或者下采样操作,会导致图像的分辨率大幅度下降,从而损失了原始信息,且在上采样(扩大尺寸)过程中难以恢复。因此,越来越多的网络都在试图减少分辨率的损失,比如使用空洞卷积,或者用步长为2的卷积操作代替池化。 -
感受域
感受野太大,对于小目标分割不准确,因为周围噪声太多了。感受野太小看不全,分割不出来。感受野适中不太好把握。
那就每一种大小都来一个——多尺度特征的提取。多尺度特征:每条路径提取不同的特征
通过设置不同参数的卷积层或池化层,提取到不同尺度的特征图。将这些特征图送入网络做融合,对于整个网络性能的提升很大。
但是由于图像金字塔的多尺度输入,造成计算时保存了大量的梯度,参数量大,从而导致对硬件的要求很高。
多数论文是将网络进行多尺度训练,在测试阶段进行多尺度融合。如果网络遇到了瓶颈,可以考虑引入多尺度信息,有助于提高网络性能。
研究成果及意义
优势总结:
- 参数同比减少,所以占比内存减小、速度快
- ResNet的引入(残差结构),越深层的网络准确率越高
- 连续卷积和池化不可避免的会带来分辨率降低,然而空洞卷积却可以在尽可能保证分辨率的情况下扩大视野。
- ASPP的创举
一、论文结构(这四篇都是经典的五段式论文写作逻辑)
摘要: 介绍论文背景、核心观点、方法途径、最终成果
1. Introduction: 相关背景概述、本文内容简述
2. Related Work: 简述相关论文发展历程,引出本文思想来源
3. Methods: 详细说明模型结构
4. Experimental Results: 实验结果分析
5. Conclusion
6. References
二、摘要核心
v3、v4不需要CRF
① DeepLab v1
背景概述: DCNNs使用的领域方向和结果
主要贡献: 提出将深度卷积神经网络和CRF相结合,克服了深度网络的局部化特性
网络效果: DCNN本身存在的问题:最后一层不足以进行精确分割目标,由什么导致的,引出本文算法的解决方式。该网络超过了以往方法的精度水平,可以更好地定位分割边界
实验结果: 在PASCAL VOC 2012数据集中取得了71.6%的IOU;在正常GPU上可达到每秒8帧的处理速度
② DeepLab v2
主要贡献: 概述本文的主要工作。分三点介绍本文的研究工作。
(1)空洞卷积在密集预测任务中是一个非常强大的工具,可以实现在不增加参数量的情况下有效扩大感受域,合并更多的上下文信息;
(2)DCNNs与CRF相结合,进一步优化网络效果;
(3)提出了ASPP(基于空洞卷积的空间金字塔结构)多尺度分割方法。
网络效果: ASPP增强了网络在多尺度下多类别分割时的鲁棒性,使用不同的采样比例与感受野提取输入特征,能在多个尺度上捕获目标与上下文信息。
实验结果: 在PASCAL VOC 2012数据集中取得了79.7%的MIOU;在其他数据集中也进行了充分的实验
③ DeepLab v3
主要贡献: 为了解决多尺度下的分割问题,本文设计了级联或并行的空洞卷积模块;扩充了ASPP模块
网络效果: 网络没有经过DenseCRF后处理,也可得到不错的结果。整个深度学习本身的算法模型获得了很大的提高。
实验结构: 在PASCAL VOC2012数据集中获得了与其他最新模型相当的性能
④ DeepLab v3+
背景概述: 深度神经网络通常采用ASPP模块或编码解码结构进行语义分割。
主要贡献: 通过添加一个简单而有效的解码器模块来扩展DeepLab v3,以优化分割结果
网络效果: 该网络超过了以往的精度水平,可以更好地定位分割边界。
实验结果: 在PASCAL VOC 2012数据集和 Cityscapes数据集中分别取得了89%和82.1%的MIOU
⑤ 摘要逻辑总结:总体概述->本文方法->实验结果
总体概述:
(1)大背景概述:CNN、DCNN、FCN等常用网络作为大背景
(2)文章中心概述:开门见山,文章主要做了什么工作
本文方法:
(1)算法由…构成:
1. 多路径:本文架构由…和…路径组成
2. 框架:本文提出了一种…框架
(2)罗列1、2、3点
多模块:提出了…模块,解决了…问题
实验结果:
(1)数据集 & 结果
(2)挑战赛 & 结果
(3)与…(经典的前人方法)相比 & 结果
三、DeepLab v1
1. Introduction
DeepLab v1 结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)
DCNNs:
(1)采用FCN思想,修改VGG16网络,得到coarse score map 并插值到原图像大小。
(2)使用空洞卷积得到更密集且感受野不变的特征图
DenseCRFs:
借用fully connected CRF对从DCNNs得到的分割结果进行细节上的refine
逻辑:先说发展历程,提出有两个问题,针对这两个问题引出解决方法。我们的方法+前人的方法,但比前人有效,分三点总结本文优点
2. 相关工作
传统算法概述
早起的分割算法
简述FCN
关于CRF
3. 算法结构介绍
① 改编VGG16:
- 把VGG16的全连接层全替换成卷积层;
- 原始的vgg16下降的1/32,因为太稀疏了,替换成了1/8;
- 最大池化添加了空洞卷积
改编细节:
- 把最后1000分类改成21分类;
- 损失函数用的交叉熵
- 优化器用的SGD
与FCN相比,本文优势:
- 可以使用简单双线性插值的方式,忽略计算成本,将分辨率提高8倍。用下采样将原图缩小了1/8,最后直接用线性插值还原8倍。上采样使用反卷积恢复特征图尺寸,会大大增加复杂性和训练时间,对网络实时性有影响。
② 用卷积神经网络控制感受野大小来进行加速计算
原始vgg16感受野的瓶颈:7×7太大了;
替换成4×4或者3×3
③ 条件随机场CRF Conditional Random Fields
DCNN网络的内部矛盾:可以通过分数图的结果预测分析图像中存在对象的粗略位置,不适合精确的定位和轮廓分析。
使用CRF+DCNN结合来解决
④ 多尺度预测
提高边界定位
⑤ 总结

4. 实验
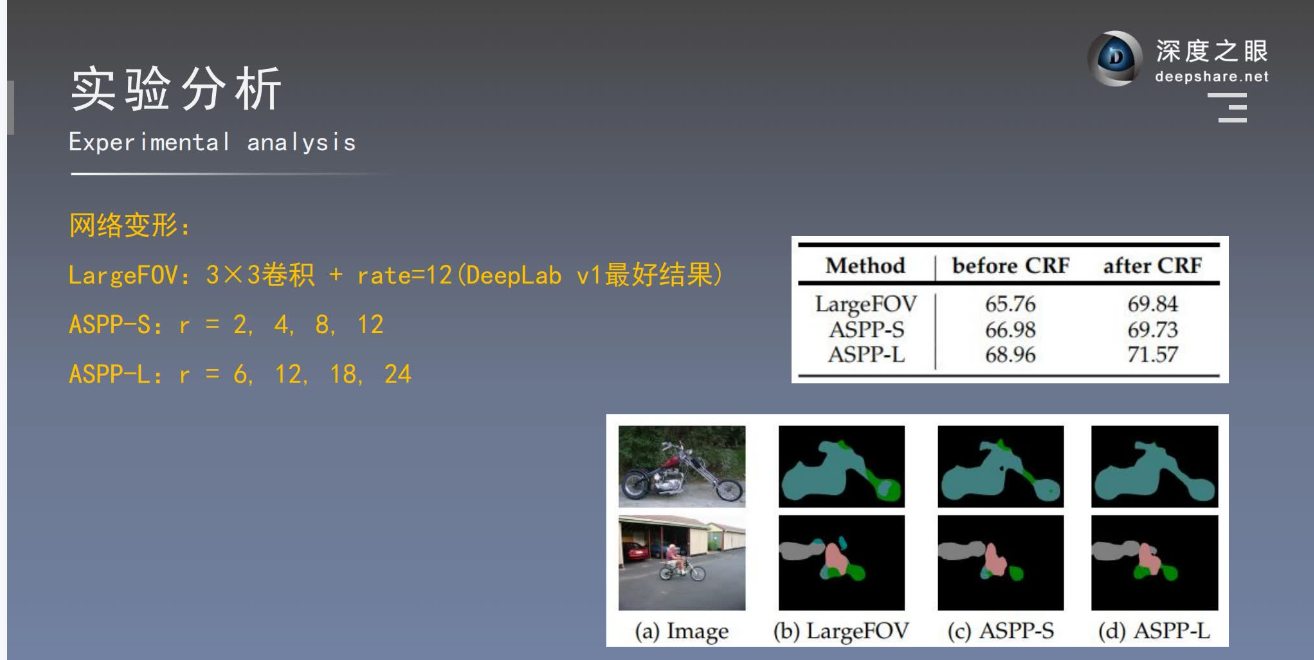
① 实验设置:网络变形
DeepLab-MSc:类似FCN,加入特征融合
DeepLab-7×7:替换全连接的卷积核大小为7×7
DeepLab-4×4:替换全连接的卷积核大小为4×4
DeepLab-LargeFOV:替换全连接的卷积核大小为3×3,空洞率为12
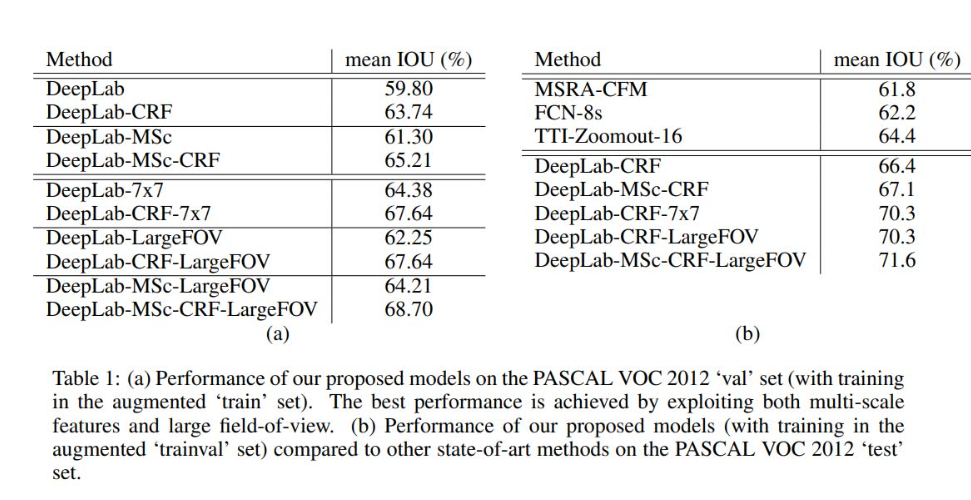

② 实验设置
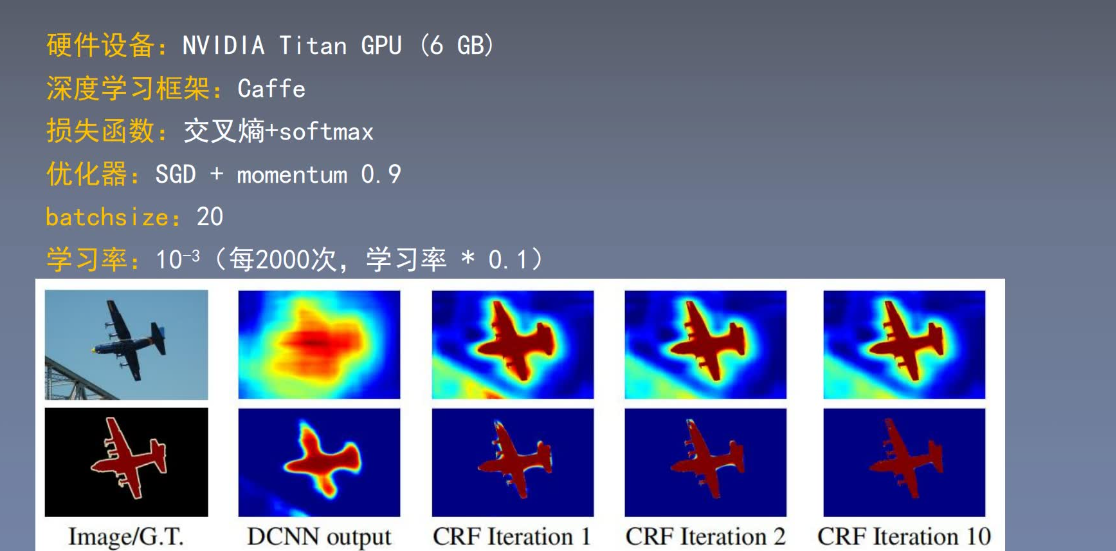
四、 DeepLab v2
1. 引言和相关工作
- 针对分辨率过低的特征图,文章通过修改最后的几个池化操作,避免特征图分辨率损失过大,通过引入空洞卷积,在没有增加参数与计算量的情况下增大了感受野。(基本同理于v1)
- 需要分割的目标具有多样的尺度大小。文章参考了空间金字塔池化的思想,这里使用不同比例的膨胀卷积(空洞卷积)构造“空间金字塔结构” (ASPP/ Atrous Spatial Pyramid Pooling)
- DCNN网络对目标边界的分割准确度不高。文章引入全连接条件随机场(fully-connected Conditional Random Field, CRF)使得分割边界的定位更加准确。
introduction: DCNN发展+挑战+分点去说明介绍具体内容+简述算法结构+本文优势+与v1比的改进之处
Related work: 分成三类分割算法,分别介绍这三大类有什么特点+DeepLab贡献+DCNN和VRF+介绍空洞卷积。
(基于区域分割、、FCN(全卷积代替全连接)+CRF)
(其他思路:编码器-解码器框架对称为一类(代表 U-Net、SegNet)、不对称为一类、空洞卷积作为主要思想为一类)
2. 方法
① 空洞卷积
空洞卷积与下采样上采样进行对比:空洞卷积效果更好
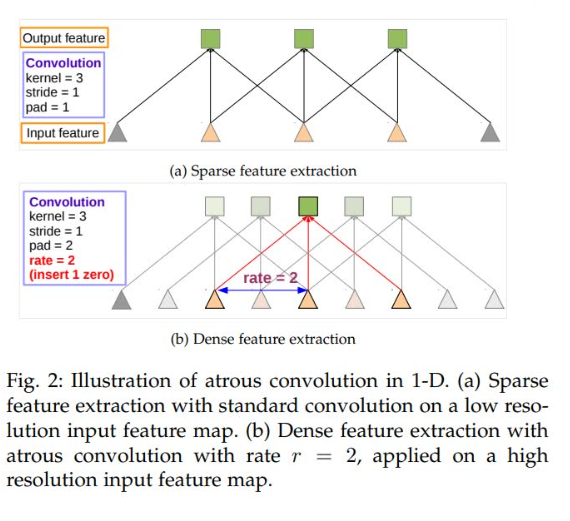
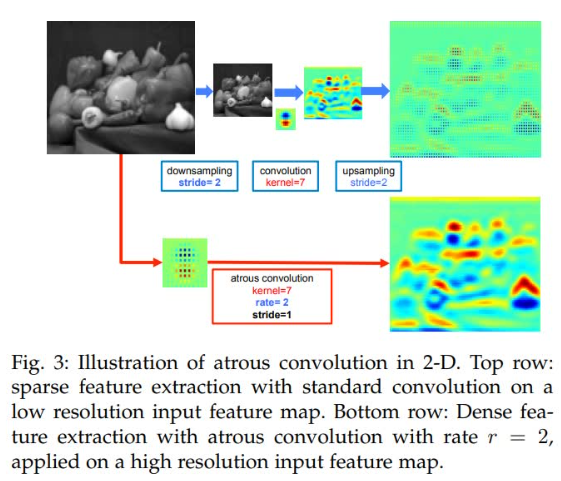
稠密映射:
标准3×3卷积:3×3大小的区域对应一个输出值
空洞卷积(rate=2):5×5大小的区域对应一个输出值
感受野计算:
空洞率对应卷积核尺寸:

② SPPNet
为了解决CNN对输入图片尺寸的限制。
由于全连接层存在,与之相连的最后一个卷积层的输出特征需要固定尺寸,从而要求输入图片尺寸也要固定。
之前的做法:是将图片裁剪crop或者变形warp。
但会导致图片的信息缺失或变形,影响识别精度。
SPPNet的方法:
使用空间金字塔结构
image—conv layers — spatial pyramid pooling — fc layers — output
在最后一层卷积特征图的基础上又进一步进行处理,提出了spatial pyramid pooling。
简而言之,SPPNet就是将任意尺寸的特征图用三个尺度的金字塔层分别池化,将池化后的结果拼接得到固定长度的特征向量,送入全连接层进行后续操作。
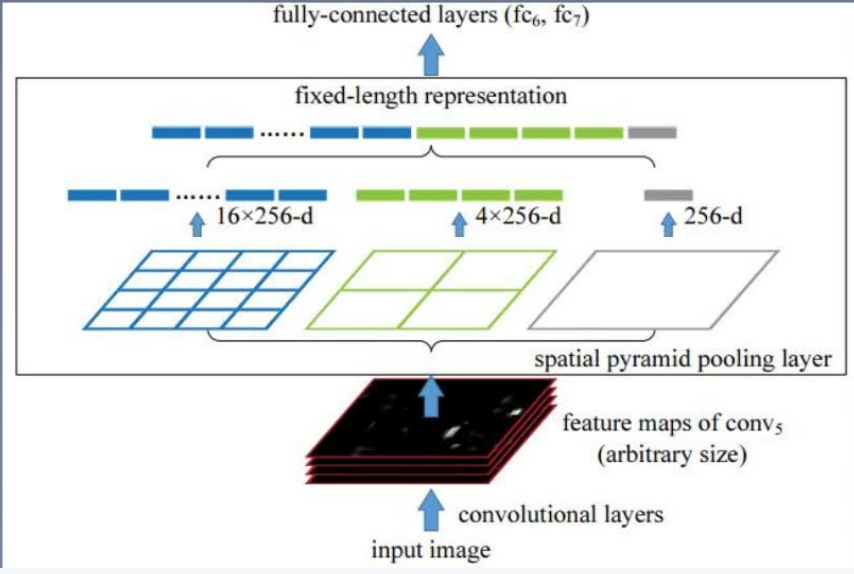
③ bottom-up & top-down
top-down: 在模式识别的过程中使用了上下文信息
bottom-up: 以数据为主要驱动。关于图片的所有信息经过分析后判断出信息,这些信息都是单方向传递的。
④ ResNet的残差结构
变化率:残差的引入去掉了主体部分,从而突出了微小的变化 F(x)
H(x)=F(x)+ x
如果主体部分要是太多了,会很难学习,参数比较多,导致网络加深之后产生退化现象。
主要思想:用一个神经网络去拟合 y=x 这样的恒等映射,比用一个神经网络去拟合 y=0 的映射要难。因为拟合y的时候,只需要把权重和偏置逼近成0就好了。
3. 算法和实验
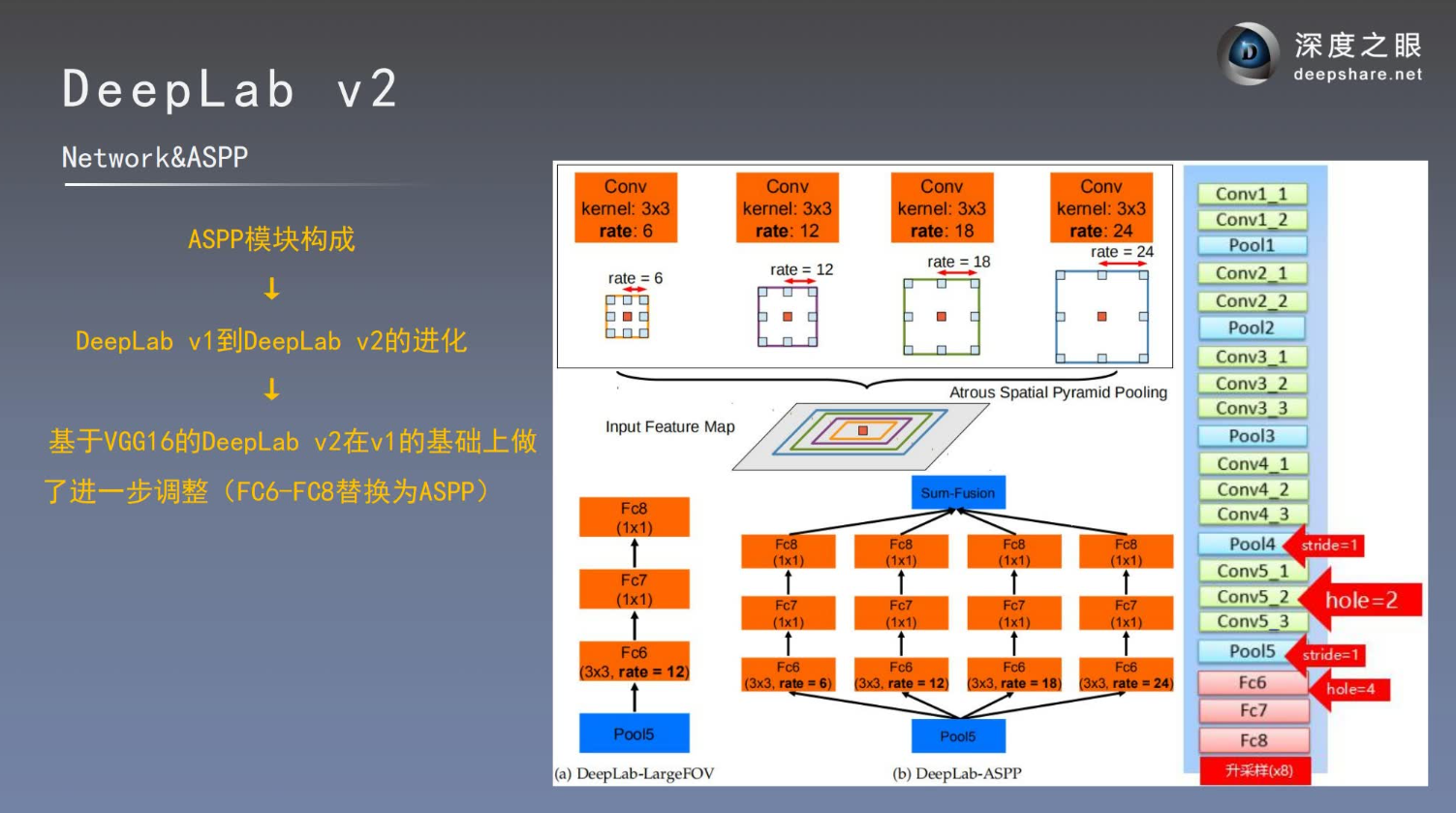
把V1的FC6、FC7、FC8替换成ASPP结尾模块,最后做上采样还原。
参数设置

网络变形
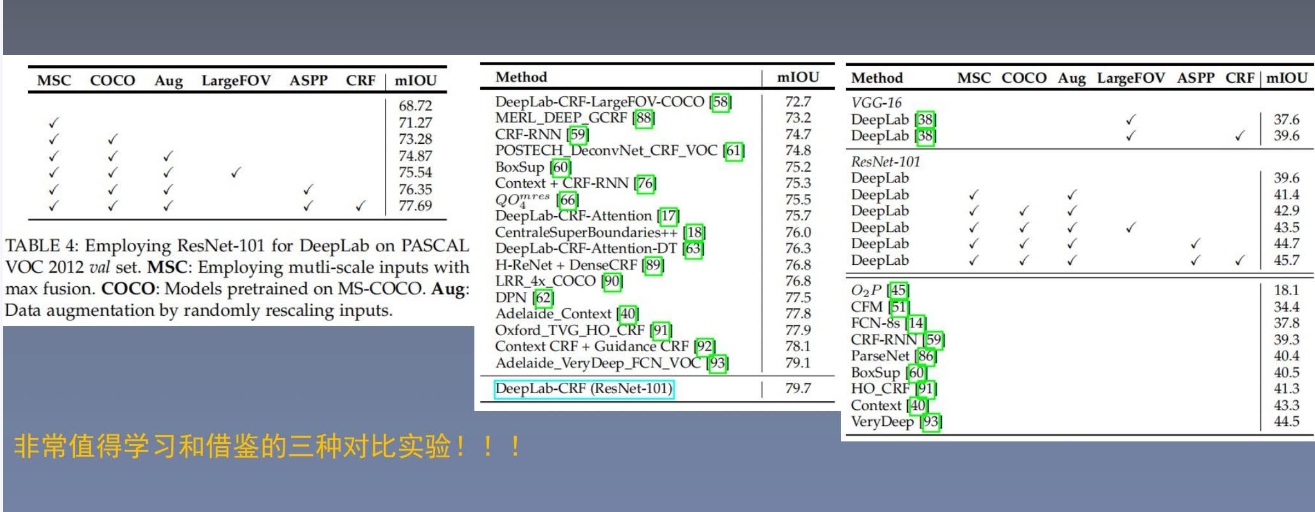
MSC:多尺度融合
COCO:预训练
Aug:数据增强,随机缩放输入图片
LargeFOV:大感受野
ASPP
CRF
对实验部分的描述很重要:多个数据集、每个数据集多几个实验
五、DeepLab v3
1. 本文贡献

这个系列
两个挑战:分辨率;多重信息
解决方法:空洞卷积
2. 相关工作
目前主流的分割架构

Image pyramid: 从输入图像入手,同样的模型使用多个尺寸(不同尺度的图像)分别送入网络进行特征提取,后期再融合所有尺寸得到特征。
远距离的信息是针对小目标的(越远越小),大尺寸的图像还保留着小尺寸的细节。
缺点:每张图片都会保存所有的参数,不适合更深层的网络,因为GPU内存有限
encoder-decoder: 编码器部分使用下采样进行特征提取,解码器部分利用上采样进行还原特征图尺寸。
深层网络&空洞卷积: 经典分类算法利用连续下采样提取特征,而空洞卷积是利用不同的采样率。
ASPP: 多尺度捕获信息。用不同的采样率捕获信息,在多个尺度上进行空洞卷积/池化。起到了提取多尺度特征的作用,而不是只对结果进行处理和优化。BN层也很重要。
除了ASPP,仍有其他网络使用这个思想。SPPNet、PSPNet等
3. 算法&实验部分
output_stride:输入图像与输出图像的比例。
网络结构
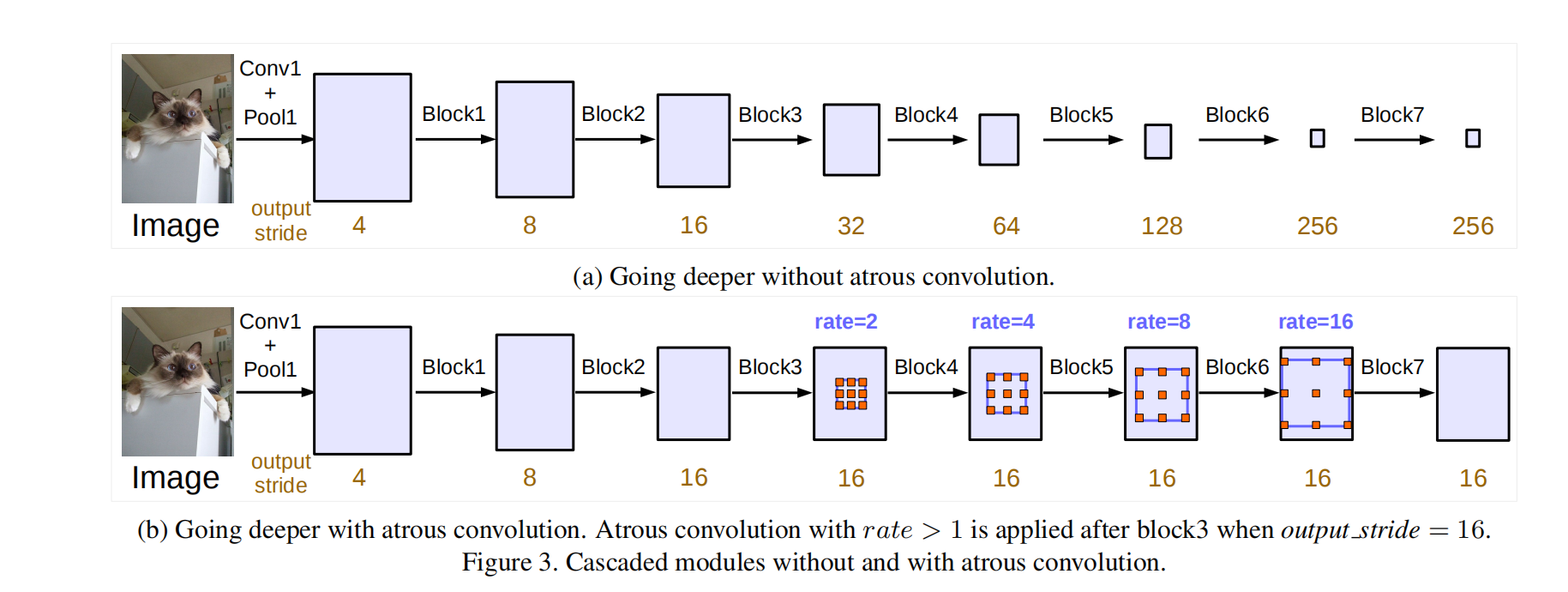
经典分类算法网络架构,如ResNet
|
DeepLab v3 空洞卷积串行网络结构
|
DeepLab v3 空洞卷积并行网络结构(调整了ASPP模块)
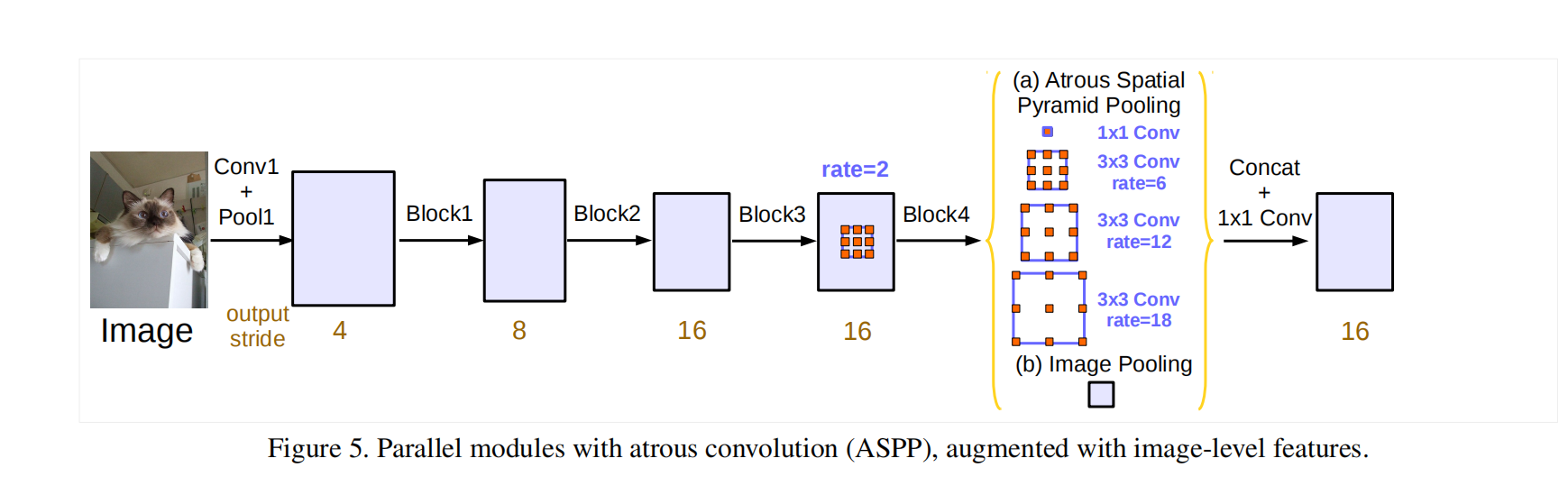
ASPP是在不同尺度上重复的进行特征采样来提高精确度,对任意尺度的分割是有效的。
随着采样率增加,越往后,无效信息越多,效果越差。3×3的卷积退化成了1×1卷积
改进:image-level features
image pooling直接对原图来的输入来进行补偿,避免退化。
并行操作时还调整了ASPP模块。这里的ASPP引入了BN层。
实验设置:

上采样:8倍还原
数据增强:随机缩放比例在0.5-2.0之间
采用在ImageNet预训练的ResNet模型作为主网络,使用空洞卷积来获得更密集的特征提取。
主网络之间:ResNet-50、ResNet-101

网格结构 用不同的比例:

对特征图片进行不同的缩放

修改前和修改后的ASPP进行对比
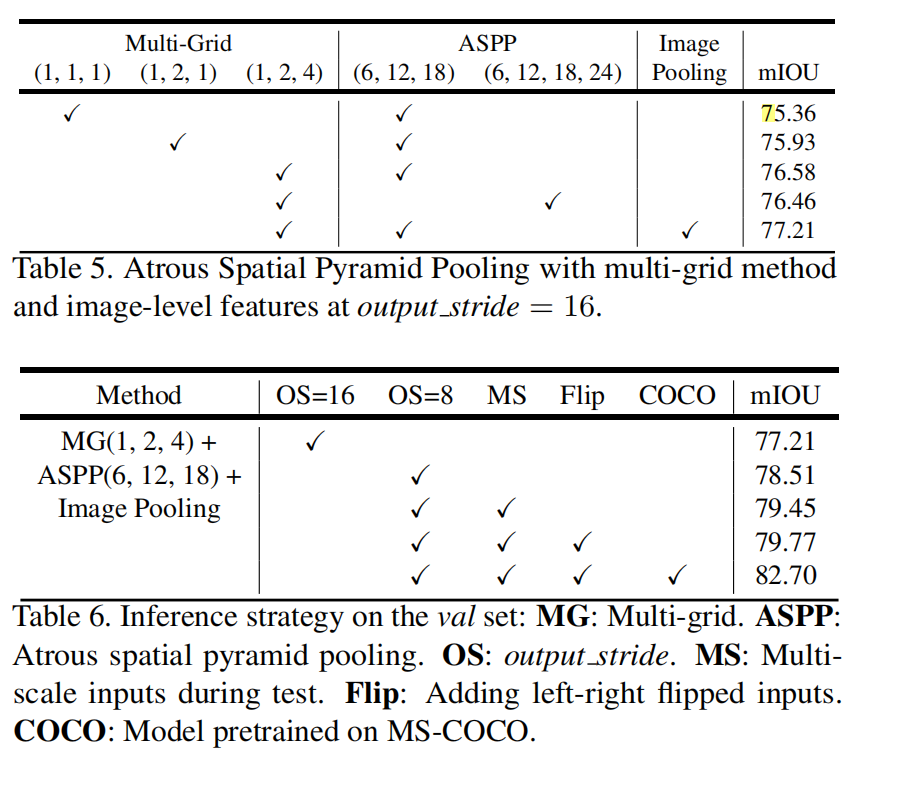
多个网络的比较:
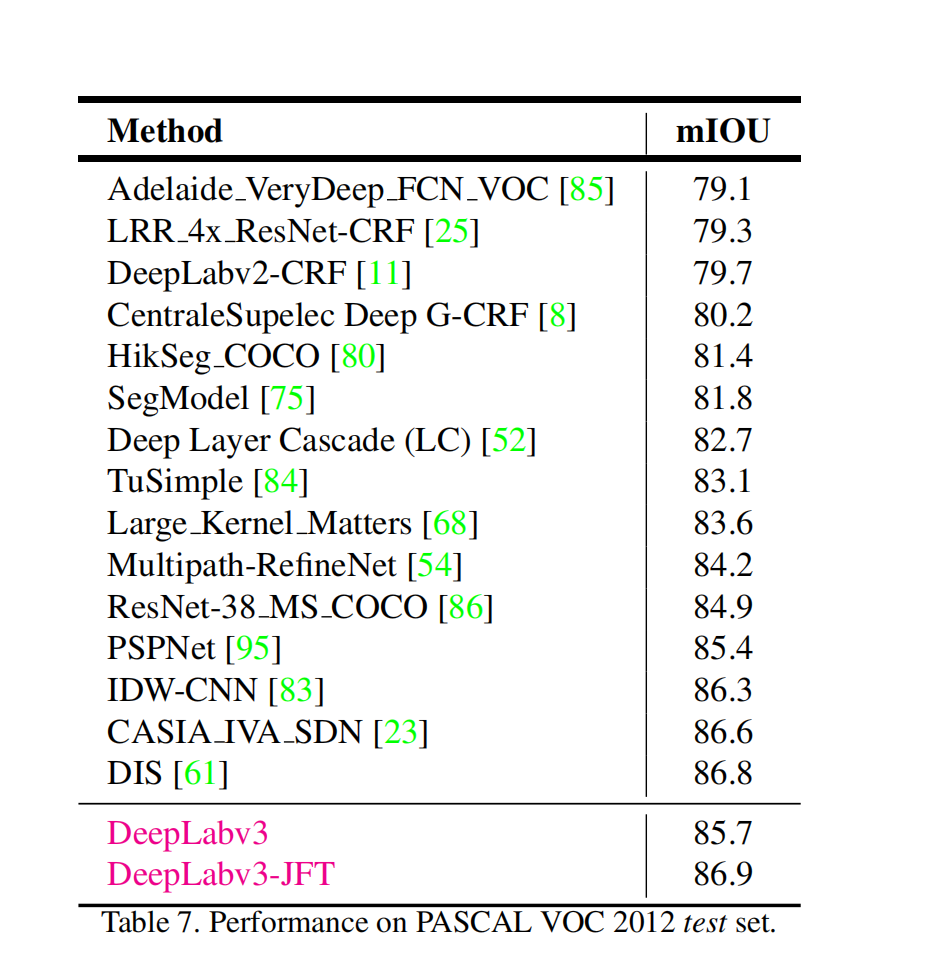
总结:
DeepLab v3使用了空洞卷积,使得特征映射更加精确,能捕获长跨度的上下文信息,对多尺度目标的提取效果不错。特别是为了编码多尺度信息,提出了级联模块的思想,使采样率加倍,ASPP增大了图像级别的特征(image-level features),对卷积核的多个采样率和感受野进行了相关的实验。比之前的DeepLab模型有了极大的提高。
附加的实验
对超参数的调节
改改图片尺寸、Batchsize、参数设置……
在Cityscapes数据集上的实验
六、DeepLab v3+
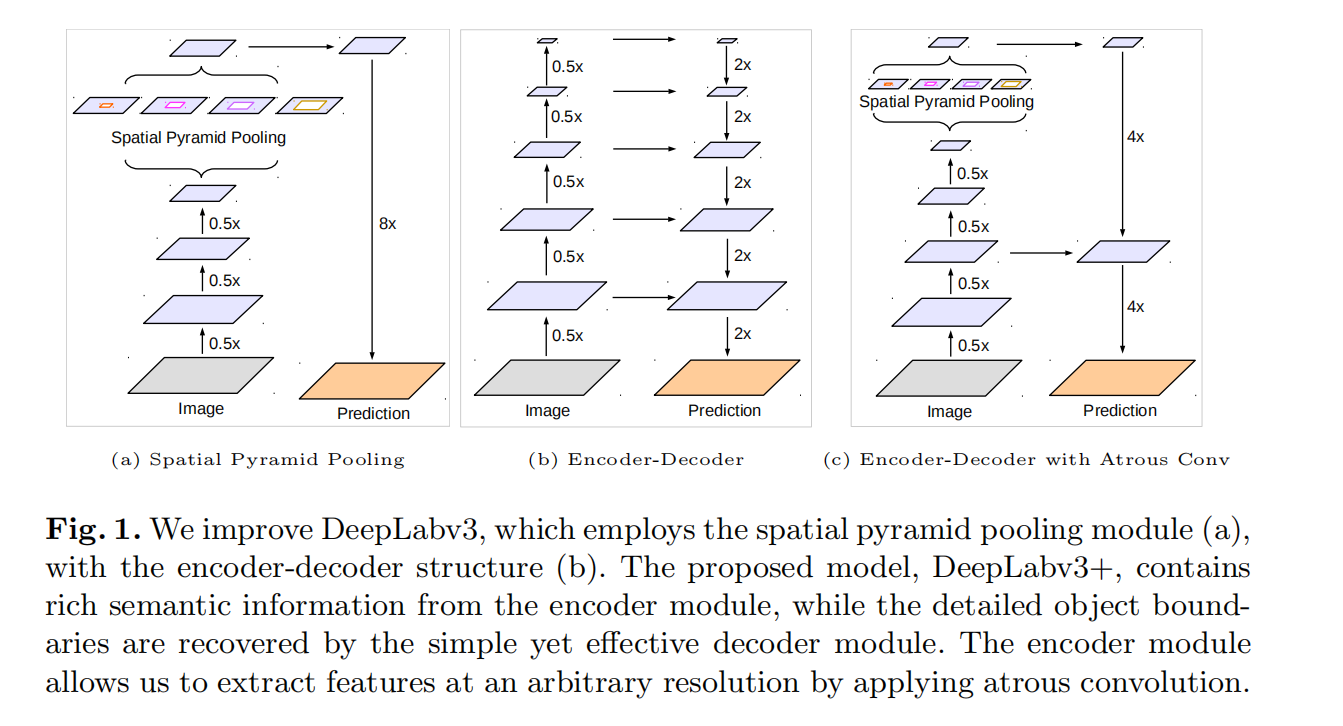
1. 本文贡献
提出了一种编码器-解码器结构【不对称的】:编码器采用的DeepLab v3更好的提取特征,添加解码器恢复尺寸,得到新的模型;
通过空洞卷积来控制特征图的分辨率,目的是为了折中精度和运行时间;
将Xception模型应用于分割任务,模型中广泛使用深度可分离卷积,与ASPP结合使用
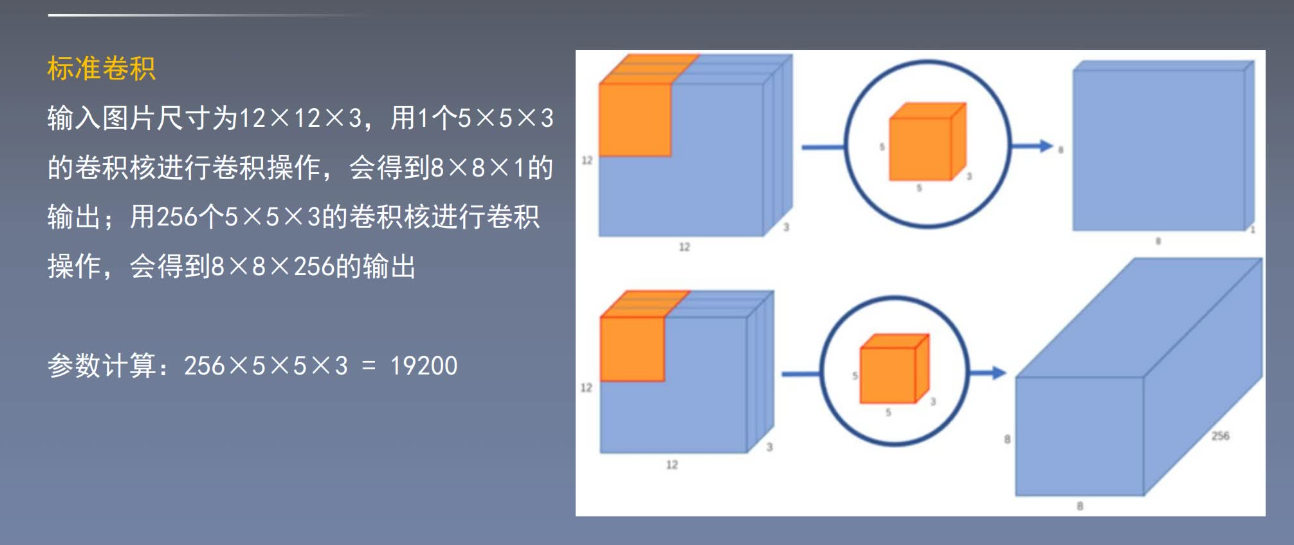
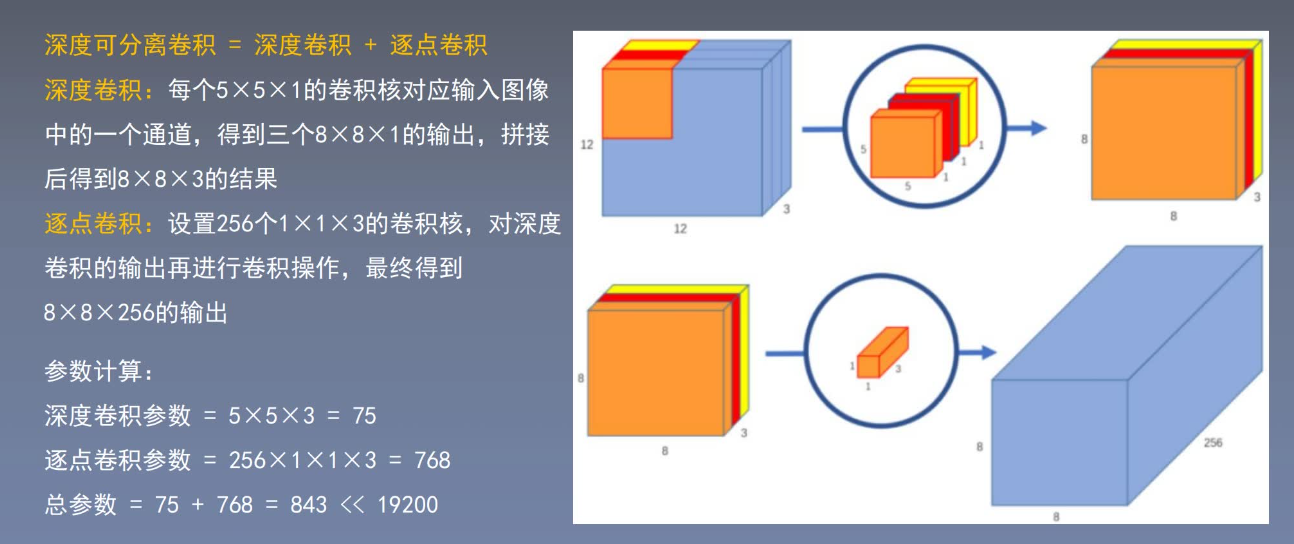
2. 深度可分离卷积——可以减少卷积网络参数
标准卷积 VS 深度可分离卷积
3. 算法 &实验
① 编码器-解码器

编码器:
使用DeepLab v3作为编码器结构,输出与输入尺寸比例为16(output——stride = 16)
ASPP:一个1×1卷积 +三个3×3卷积(rate={6,12,18})+ 全局平均池化
解码器:
先把编码器上的结果上采样4倍,然后与编码器中相对应尺寸的特征图进行拼接融合,再进行3×3卷积,最后上采样4倍得到最终结果。
融合低层次信息前,先进行1×1卷积,目的是降低通道数
② v3+对Xception的微调
(1)更深的Xception结构,原始middle flow迭代8次,微调后迭代16次
(2)所有max pooling 结构被stride=2 的深度可分离卷积替代
(3)每个3×3的depthwose convolution后都跟BN和ReLU

③ 实验设置

七、DeepLab大总结


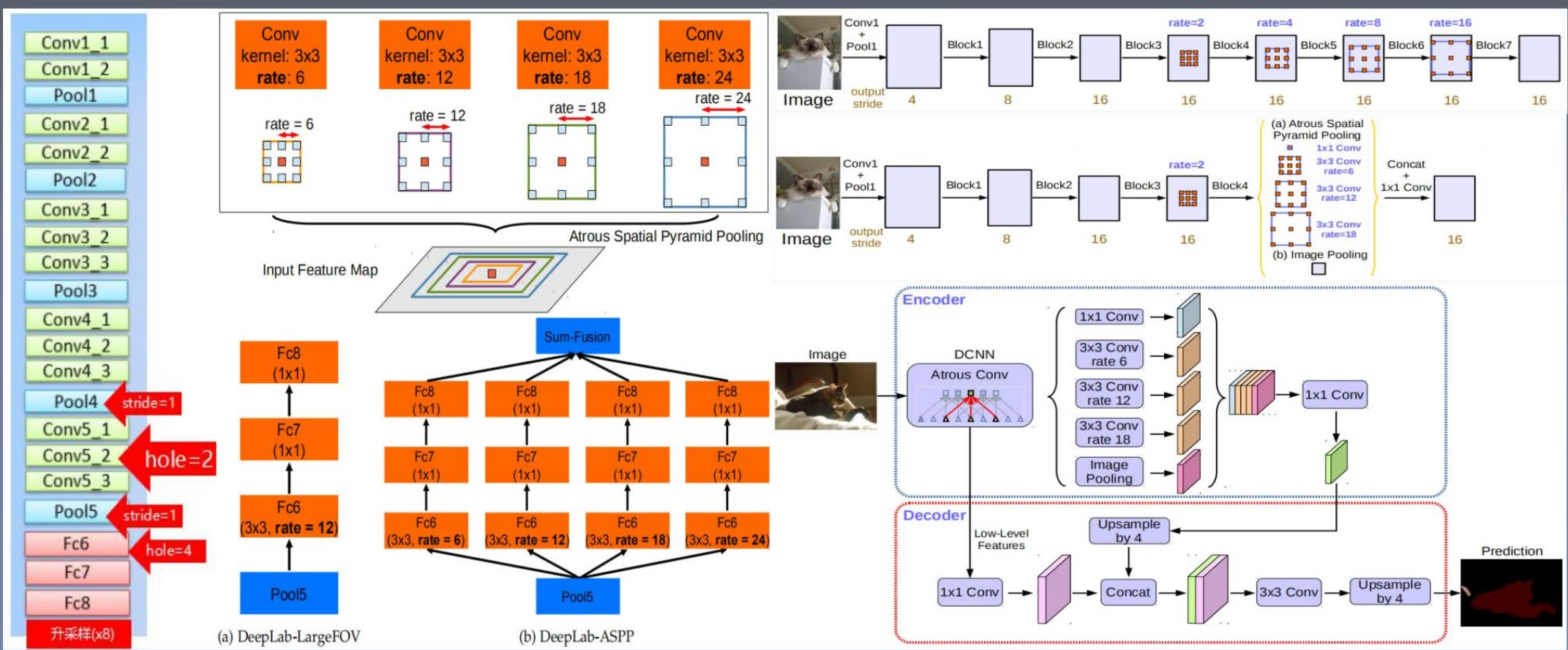
1. v1 & v2:DCNN+CRF
使用DCNN生成一个粗糙的特征图
使用CRF条件随机场做后处理,使边界信息更加精准平滑
① DCNN
DCNN必不可少的元素
striding:输出更小的图片
pooling:让输入图片具有一定的平移普遍性
DeepLab解决方案:空洞卷积和CRF
DCNN-Atrous
① 移除最后两个池化层
② 原始卷积核用rate=2的参数扩大
好处:
标准卷积只响应了原图1/4位置的特征和信息
卷积核中加入空洞,可以让整个图像都响应
小感受域:更准确的定位
大感受域:更全面的上下文信息
可以保证卷积核大小可以得到有效的扩增
没有引入多余的参数和计算量。
既可以保证感受域得到有效的扩大,又可以保证网络模型效率没有得到影响。
能让特征图产生更密集的映射,然后用双线性插值还原8倍上采样。
② CRF
③ v1
由改编后的vgg16构成的;
卷积替代了全连接;
在最后两个最大池化层(pooling 4、5)之后,不需要进行上采样;
在pooling4、polling5卷积核后面加入了空洞卷积;
整个网络以VGG16为基础,加了预训练权重
④ v2-ASPP
跟v1相比的提高:
使用了ASPP多尺度提取模块;
扩展了主网络,除了VGG16,还使用了ResNet作为主路径来提取特征;
采用了pollcy学习率,来替代标准学习率
ASPP
更好地提取多尺度特征;
在卷积前,使用多个空洞率,并行的处理特征,有高效的计算效率;
多采样率并行的方式设计ASPP模块
⑤ v1 &v2 优点
- 速度:空洞卷积的算法,使得速度提高很多,DCNN操作8 fps,CRF处理一张0.5s
- 准确度很高
- 简单性:DCNN和CRF都是成熟的模块了,只是做个衔接
2. v3
1. 对比v1、v2的改变
① 提出了一个常用的框架,可应用于任何网络;

② 复制的最后一个ResNet的多个副本。
后面的block 5、6、7都是通过复制ResNet block4形成的。没有用到本身的模块,不再下采样,不再引用通道数造成网络负担。第一个版本按照串联排列的,加了ASPP之后也有并联排列的
③ 优化了ASPP模块,在每一个卷积后面都加了BN层。
BN对整个网络效果都有影响
④ CRF取消了
2. ResNet
- block5、6、7都是复制的block 4;
- 每一个block里都是三层的卷积;
- 最后的卷积层 除了最后一个block,其他都包含步长为2的下采样操作;
- 为了保留原始的图片尺寸,卷积被替换为不同采样率的空洞卷积,来保证不用那么多下采样,拿到分辨率比较高的特征图。
3. 并联的ASPP改进
- BN加入到ASPP里面
- 随着空洞率的增加,在学习的权重越变越小
- 加入了图像的全局平均池化,在ASPP中进行补偿 (思想很像ResNet的残差结构)
4. 改进的ASPP组成
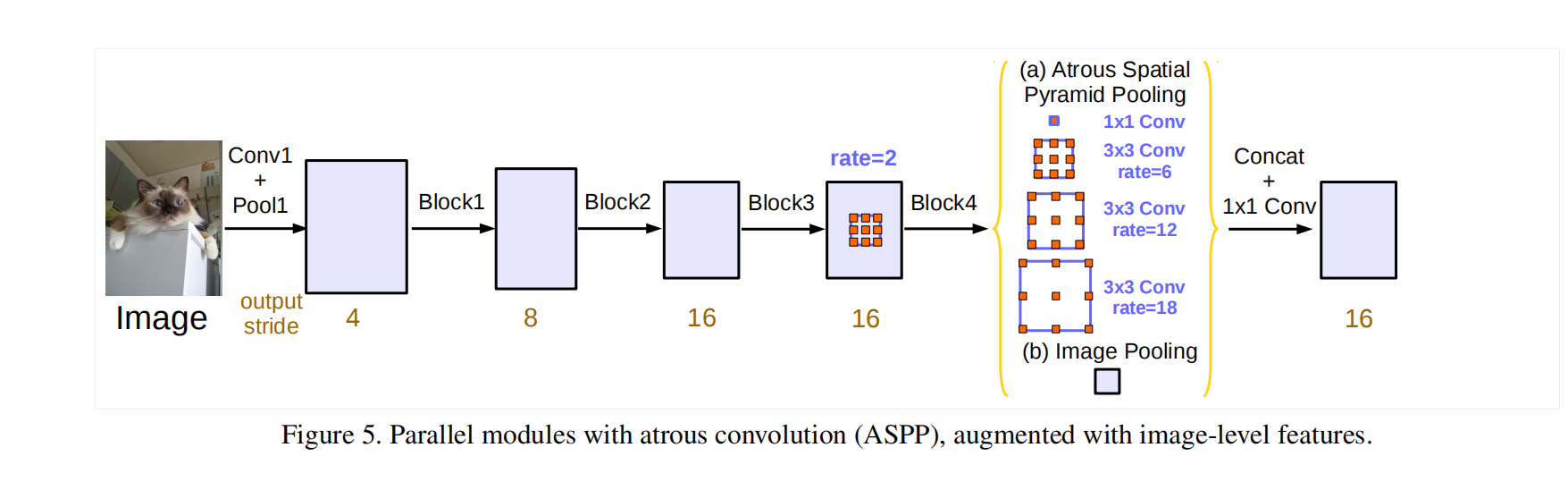
一个1×1卷积----三个3×3的卷积(对应的空洞率分别是6,12,18)
都是256个和BN层
在最后加入image-level features,使用全局平均池化
通过ASPP得到的结果,使用concat进行拼接,再进行一个1×1的卷积,作为输出。
5. 最好的结果配置:
ASPP
output stride = 8
数据增强使用的翻转和缩放














 5243
5243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









