






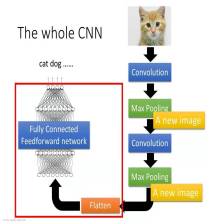
用自己的数据集训练Tensorflow模型
上篇博文我们用tensorflow实现了一些简单的图像处理
TensorFlow中的图像处理
今天我们进一步来学习tensorflow
本文具体数据集与源代码可从我的GitHub地址获取
https://github.com/liuzuoping/Deep_Learning_note
- 数据预处理
- 数据的读取
数据读取
根据tensorflow的官方教程来看,tensorflow主要支持4中数据读取的方式。
- Preloaded data: 预加载数据
- Feeding: 先产生一个个batch数据,然后在运行的时候依次喂给计算图。
- Reading from file: 从文件中读取,tensorflow主要支持两种方法从文件中读取数据喂给计算图:一个是CSV,还有一个是TFRecords
- 多管线输入
预加载数据
import tensorflow as tf
# 构建一个Graph
x1 = tf.constant([1, 2, 3])
x2 = tf.constant([4, 5, 6])
y = tf.add(x1, x2)
# 喂数据 -> 启动session,计算图
with tf.Session() as sess:
print(sess.run(y))
[5 7 9]
Feeding
import tensorflow as tf
# 构建Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# X_1,X_2是变量,可以赋予不同的值
X_1 = [1, 2, 3]
X_2 = [4, 5, 6]
# 喂数据 -> 启动session,计算图
with tf.Session() as sess:
print(sess.run(y, feed_dict={x1: X_1, x2: X_2}))
[5 7 9]
从文件中读取
- 直接读取文件
- 写入TFRecord并读取
直接读取文件
# 导入tensorflow
import tensorflow as tf
# 新建一个Session
with tf.Session() as sess:
# 我们要读三幅图片plate1.jpg, plate2.jpg, plate3.jpg
filename = ['images/plate1.jpg', 'images/plate2.jpg', 'images/plate3.jpg']
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=True, num_epochs=5)
# reader从文件名队列中读数据。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之后,才会开始填充队列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 获取图片数据并保存
image_data = sess.run(value)
with open('tfIO/test_%d.jpg' % i, 'wb') as f:
f.write(image_data)
写入TFRecord并读取
import tensorflow as tf
# 为显示图片
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
%pylab inline
# 为数据操作
import pandas as pd
import numpy as np
import os
img=mpimg.imread('images/plate1.jpg')
tensors = np.array([img,img,img])
# show image
print('\n张量')
display(tensors)
plt.imshow(img)

import os
import tensorflow as tf
from PIL import Image
def create_record():
writer = tf.python_io.TFRecordWriter("tfIO/tfrecord/test.tfrecord")
for i in range(3):
# 创建字典
features={}
# 写入张量,类型float,本身是三维张量,另一种方法是转变成字符类型存储,随后再转回原类型
features['tensor'] = tf.train.Feature(bytes_list=tf.train.BytesList(value=[tensors[i].tostring()]))
# 存储形状信息(806,806,3)
features['tensor_shape'] = tf.train.Feature(int64_list = tf.train.Int64List(value=tensors[i].shape))
# 将存有所有feature的字典送入tf.train.Features中
tf_features = tf.train.Features(feature= features)
# 再将其变成一个样本example
tf_example = tf.train.Example(features = tf_features)
# 序列化该样本
tf_serialized = tf_example.SerializeToString()
# 写入一个序列化的样本
writer.write(tf_serialized)
# 由于上面有循环3次,所以到此我们已经写了3个样本
# 关闭文件
writer.close()
def read_and_decode(filename):
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'tensor': tf.FixedLenFeature([], tf.string),
'tensor_shape' : tf.FixedLenFeature([], tf.int64),
})
tensor = tf.decode_raw(features['tensor'], tf.uint8)
tensor = tf.reshape(tensor, [224, 224, 3])
tensor = tf.cast(tensor, tf.float32) * (1. / 255) - 0.5
tensor_shape = tf.cast(features['tensor_shape'], tf.int32)
return tensor,tensor_shape
if __name__ == '__main__':
img, label = read_and_decode("tfIO/tfrecord/test.tfrecord")
img_batch, label_batch = tf.train.shuffle_batch([img, label],
batch_size=5, capacity=2000,
min_after_dequeue=1000)
#初始化所有的op
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
#启动队列
threads = tf.train.start_queue_runners(sess=sess)
for i in range(3):
val, l= sess.run([img_batch, label_batch])
#l = to_categorical(l, 12)
print(val.shape, l)















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









