







 交叉熵作为代价函数能加速神经网络学习。当模型预测错误时,其输出与标签相差越大,梯度也越大,从而更快调整参数。相较于二次平方误差,交叉熵在初期使cost下降更迅速,提高训练效率。
交叉熵作为代价函数能加速神经网络学习。当模型预测错误时,其输出与标签相差越大,梯度也越大,从而更快调整参数。相较于二次平方误差,交叉熵在初期使cost下降更迅速,提高训练效率。
对于大多数人来说,犯错是一件让人很不开心的事情。但反过来想,犯错可以让我们意识到自己的不足,然后我们很快就学会下次不能再犯错了。犯的错越多,我们学习进步就越快。
同样的,在神经网络训练当中,当神经网络的输出与标签不一样时,也就是神经网络预测错了,这时我们希望神经网络可以很快地从错误当中学习,然后避免再预测错了。那么现实中,神经网络真的会很快地纠正错误吗?
我们来看一个简单的例子:

上图是一个只有一个神经元的模型。我们希望输入1的时候,模型会输出0(也就是说,我们只有一个样本(x=1, y=0))。假设我们随机初始化权重参数w=2.0,偏置参数b=2.0。激活函数为sigmoid函数。所以模型的第一次输出为:
output=σ(w⋅x+b)=σ(2.0×1+2.0)=0.98 o u t p u t = σ ( w ⋅ x + b ) = σ ( 2.0 × 1 + 2.0 ) = 0.98
可见,模型的第一次输出跟标签相差很大,很错误的一个输出。然后我们不断地使用梯度下降算法更新参数,重复训练。于是我们得到了下面这个图:
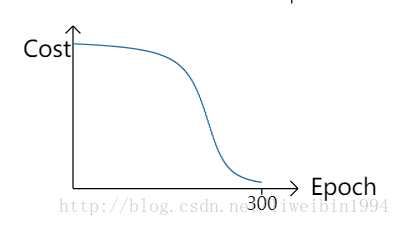
从图中可以看出,随着训练的次数增加,模型的输出越来越接近0。但是有没有发现一个问题?在训练的前部分,cost并没有显著的减少,也就是权重参数w和偏置参数b的变化不明显。我们前面说了,当我们知道错了,而且错误很大时,我们通常会很快地将错误降下来。但是图中的曲线一开始却是很缓慢地变化。这跟我们想要的不一样呀。虽然最终的结果是会收敛,但是我们希望的是在一开始训练的时候,模型可以收敛得更快。究竟是什么原因使得模型的cost在一开始的时候下降很慢呢?
我们知道在用梯度下降更新参数的时候,我们是计算了下面这两个偏导数:
∂C∂w ∂C∂b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









