







MASS这种批量操作通常风险比较大,加上SAP有时在界面上可能并不太符合国人的思维习惯。所以,在研究处理时需要更多的尝试,需要从试错中找到正确的方法。
之前写过一篇关于MASS的操作应用文,这是一种比较简单的应用情形。之所以说简单,可以理解为我们统一的把一批数据做一个开关型的定义。像本例中,统一的去冻结一批供应商。
在此基础上,把思路扩展一下。对应的另一种复杂一点的情形就是,如果我要把这批供应商的付款条件批量更改一下,有的立即付款,是1个月,有的2个月......。对应这种,在操作上就会有相应的变化了。
上面应该把情况描述清楚了。笔者刚好也被用户问到,可否帮忙做一下关于物料主数据MRP视图中的几个字段的批量变更?
接下来,我让用户把需求定义到一个EXCEL表格中给我尝试一下。如前面的博文中提到的操作一样,此时通过物流提供的表,以物料主数据为条件在MASS中批量输入后,导出清单如下图界面。
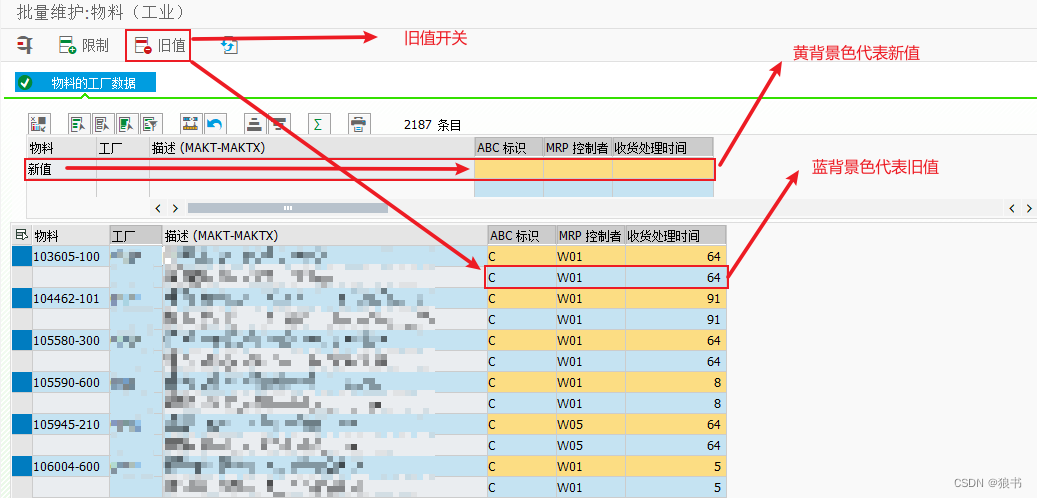
这个界面需要说明的地方很多:
旧值默认不显示,如果需要可以打开;
黄背景色代表新值(可编辑),蓝背景色代表旧值(不可编辑);
由于选择时只从EXCEL清单中输入了物料号,并未输入新值,所以输出的清单中并没有新值,而图中之所以显示有新值,仅仅是从旧值代出的一致数据;
这时重点问题就来了,如果新值是固定的,我们可以和之前一样操作,在上方输入新值。但这次新值并不是固定值。所以,这次的方法有点区别。操作上先把旧值开关关掉,然后选中需要批量修改的新值,再从EXCEL中将内容拷过来。

最后,这种方法好像也只能处理一屏数据,我不确定,但暂时没研究出来,在SAP中用Ctrl+Y无法选中整个表,只能选中当前屏幕中的内容。当选中后试图翻页时,选择就取消了。如果你需要处理的数据只有20-30条,这个方法处理起来还是很方便的。
那数据再多了怎么办?这个就要用到MASS中的从文件导入数据功能了,点赞,且听下回分解。

















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











