









-
简介
-
强化学习
-
评测结果
-
思维链
-
编程能力
-
人类偏好
-
安全
-
隐含思维链
-
总结
简介
小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖海参的小女孩。OpenAI 官方在技术博客《Learning to Reason with LLMs》中对 o1 系列模型做了进一步的技术介绍。虽然不是很详细,但是聊胜于无。
小窗幽记机器学习
记录机器学习过程中的点点滴滴和坑坑洼洼
公众号
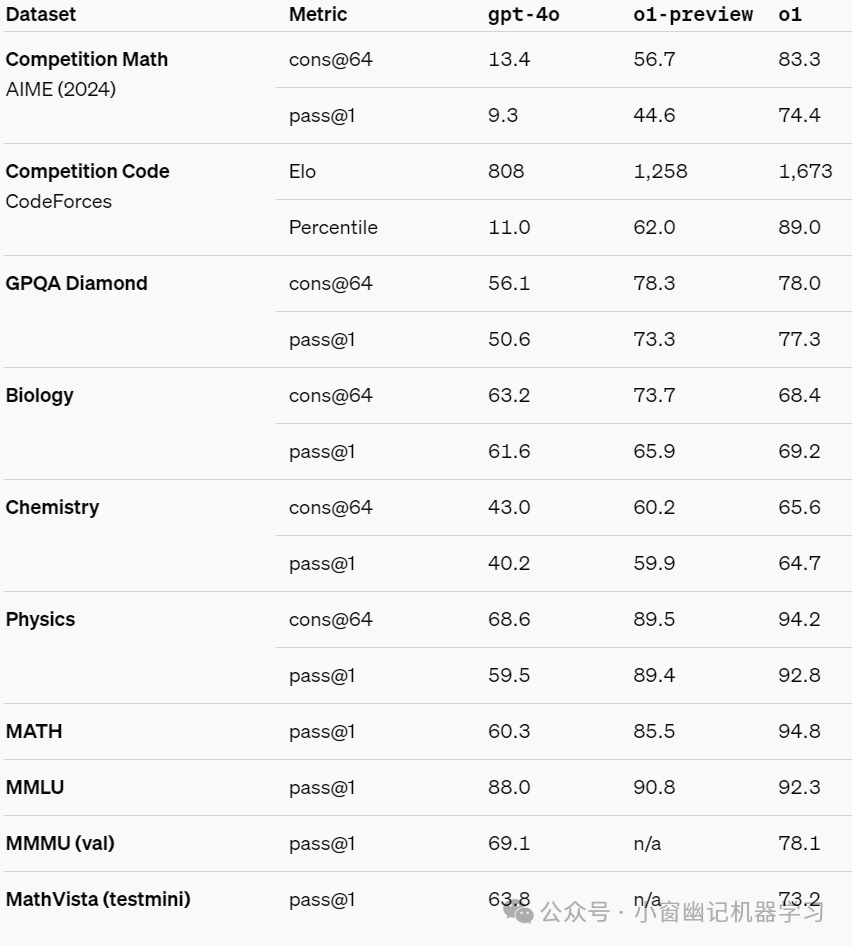
在 OpenAI 的测试中,该系列后续更新的模型在物理、化学和生物学这些具有挑战性的基准任务上的表现接近博士生水准。OpenAI 还发现它在数学和编码方面表现出色。在国际数学奥林匹克(IMO)资格考试中,GPT-4o 仅正确解答了 13% 的问题,而 o1 模型正确解答了 83% 的问题。模型的编码能力也在比赛中得到了评估,在 Codeforces 比赛中排名 89%。
强化学习
训练OpenAI o1 的时候采用了强化学习,训练来执行复杂推理任务。OpenAI 的大规模强化学习算法,教会模型如何在数据高度有效的训练过程中利用其思想链进行高效思考。其特点是,o1 在回答之前会深入思考,这使得其在响应用户之前在内部产生一个很长的内部思维链。换句话说,模型在作出正式回答之前,会像人类一样,花更多时间思考问题。通过训练,模型学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。官方还发现,o1的性能随着更多的强化学习(训练时计算)和更多的思考时间(inference时计算)而不断提高。换言之,数据的Scaling Law,正在升级为强化学习的 Scaling Law,而这个升级后的Scaling Law同时包括了训练阶段和模型推理阶段。
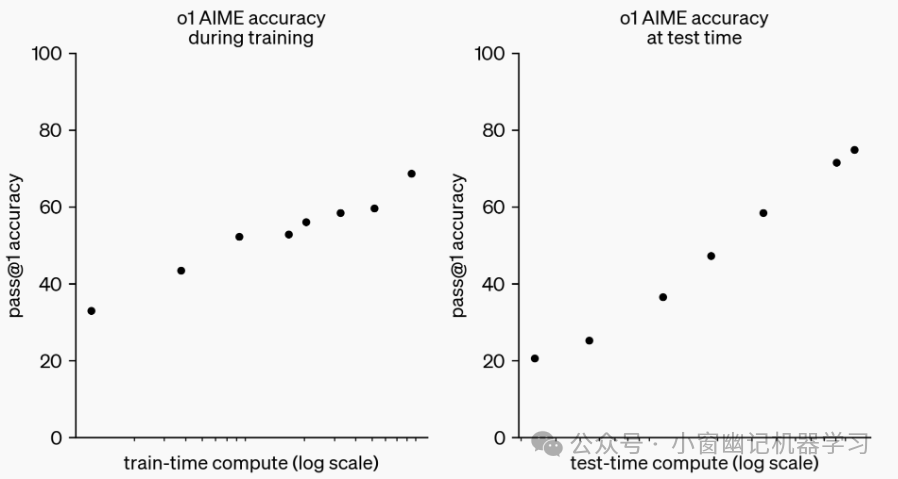
o1模型的指标,随着训练时和测试时的计算量增加都能提高。
来源:https://openai.com/index/learning-to-reason-with-llms/
评测结果
为了突出相对于 GPT-4o 的推理性能改进,OpenAI 在一系列人类考试和机器学习基准测试中测试 o1 模型。实验结果表明,在绝大多数推理任务中,o1 的表现明显优于 GPT-4o。
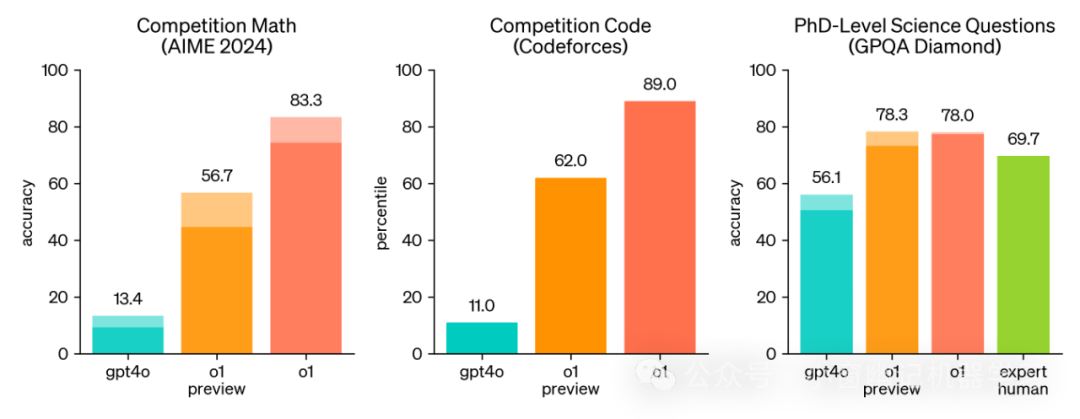
o1在具有挑战性的推理基准测试上大大优于GPT-4o。实心区域表示pass@1的准确率,阴影区域表示使用64个样本进行多数投票(共识)时的表现。
来源:https://openai.com/index/learning-to-reason-with-llms/
AIME 2024,一个高水平的数学竞赛,GPT4o准确率为13.4%,而这次的o1 预览版,是56.7%,还未发布的o1正式版,是83.3%。
代码竞赛(Codeforces),GPT4o准确率为11.0%,o1 预览版为62%,o1正式版,是89%。
而超高难度的博士级科学问题 (GPQA Diamond),GPT4o得分是56.1,人类专家水平是69.7,o1达到了78%。
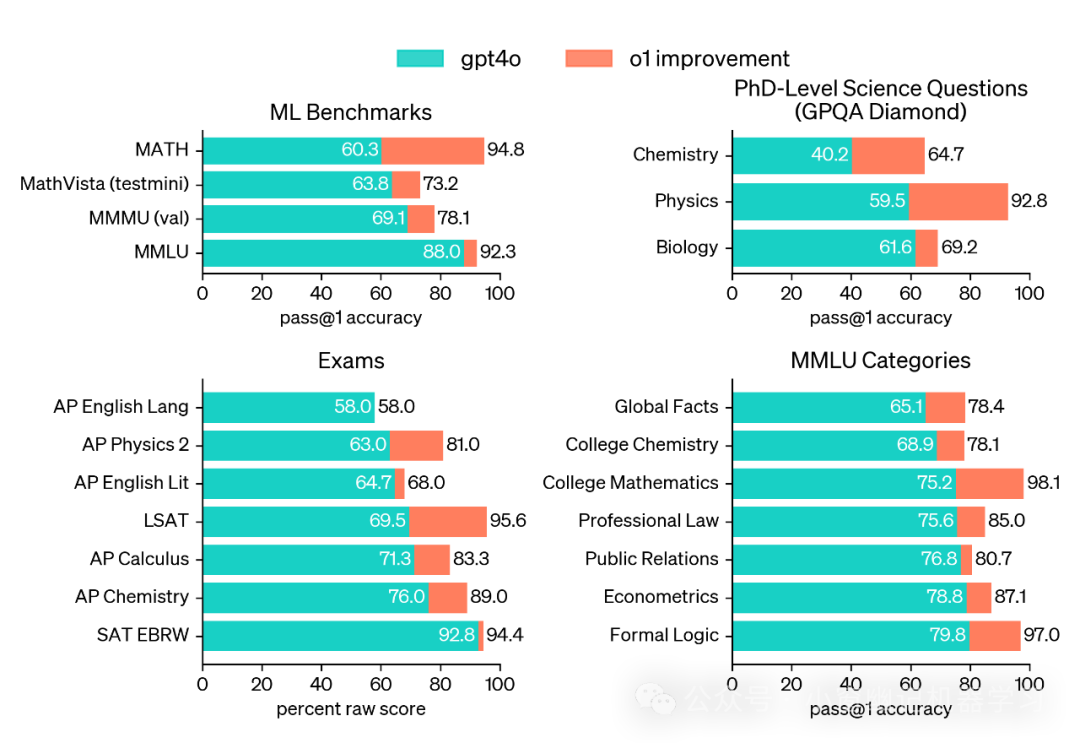
o1在多种基准测试上优于GPT-4o,包括54/57个MMLU子类别。这里展示了其中的七个作为例子。来源:https://openai.com/index/learning-to-reason-with-llms/
在许多以推理为主的基准测试中,o1的结果可媲美人类专家。最近的几个前沿模型,包括claude-3-5-sonnet和gemini-pro已经几乎打爆MATH和GSM8K榜单,以至于这些基准测试不再有效区分模型的优劣。为此,在AIME考试上评估各个模型的数学表现,AIME是专为挑战美国最优秀的高中数学学生而设计的考试。在2024年的AIME考试中,GPT-4o平均仅解决了12%(1.8/15)的题目,而o1平均解决了74%(11.1/15)的题目,当使用64个样本进行投票时达到83%(12.5/15),当用学习得来的评分函数对1000个样本进行重新排序时达到93%(13.9/15)。这个13.9分的成绩使o1跻身全美前500名学生之列,并高于美国数学奥林匹克的入围分数。
官方还在GPQA diamond上评估了o1,这是一项测试化学、物理和生物学专业知识的高难度智能基准。为了将模型与人类进行比较,官方招募了拥有博士学位的专家来回答GPQA diamond的问题。结果显示,o1超越了那些人类专家的表现,成为首个在该基准上做到这点的模型。
官方还谦虚地表示,这些结果并不意味着o1在各方面都比拥有博士学位的人更有能力,而是仅仅说明该模型在解决一些博士学位持有者预期能够解决的问题上更为出色。在其他几个机器学习基准上,o1也超越了当前的最先进水平。启用视觉感知能力后,o1在MMMU上得分78.2%,使其成为首个在此方面能与人类专家比肩的模型。o1还在57个MMLU子类别中击败了GPT-4o中的54个。说是全面遥遥领先真不为过!
思维链(CoT)
与人类在回答难题之前会长时间思考类似,o1 在尝试解决问题时会使用思维链。通过强化学习(具体到这里是 Self-play RL),o1 学会磨练其思维链并优化其使用的策略。o1学会了识别和纠正错误,并可以将复杂的步骤分解为更简单的步骤,并在当前方法无效时尝试不同的方法。这个过程极大地提高了模型的推理能力。为了展示这一进步,在下面展示了o1-preview在几个困难问题上的思维链。需要特别注意的是,这些思维链的思考过程,都统一算为输出token。示例比较长,这里就不演示了,感兴趣的可以看文末的参考资料。
编程能力
基于 o1 进行初始化并进一步训练编程技能后得到了一个非常强大的编程模型。该模型在 2024 年国际信息学奥林匹克竞赛(IOI)赛题上得到了 213 分,达到了排名前 49% 的水平。并且该模型参与竞赛的条件与 2024 IOI 的人类参赛者一样:需要在 10 个小时内解答 6 个高难度算法问题,并且每个问题仅能提交 50 次答案。
针对每个问题,这个经过专门训练的 o1 模型会采样许多候选答案,并根据测试时选择策略提交其中的50个。选取标准包括在 IOI 公共测试案例、模型生成的测试案例以及一个学习得到的评分函数上的性能。研究表明,这个策略是有效的。因为如果改为随机提交一个答案,则平均得分仅有156。这说明在该竞赛条件下,这个策略至少值 60 分。
OpenAI 发现,如果放宽提交限制条件,模型性能显著提高。如果每个问题允许提交 1 万次答案,即使不使用上述测试时选取策略,该模型也能得到 362.14 分,超过了金牌门槛。
最后,OpenAI 模拟了 Codeforces 主办的竞争性编程竞赛, 以展示该模型的编码技能。采用的评估与竞赛规则非常接近,允许提交 10 份代码。GPT-4o 的 Elo 评分为 808,在人类竞争对手中处于前 11% 的水平。该模型远远超过了 GPT-4o 和 o1,获得了1807的Elo评分,表现优于93%的参赛者。
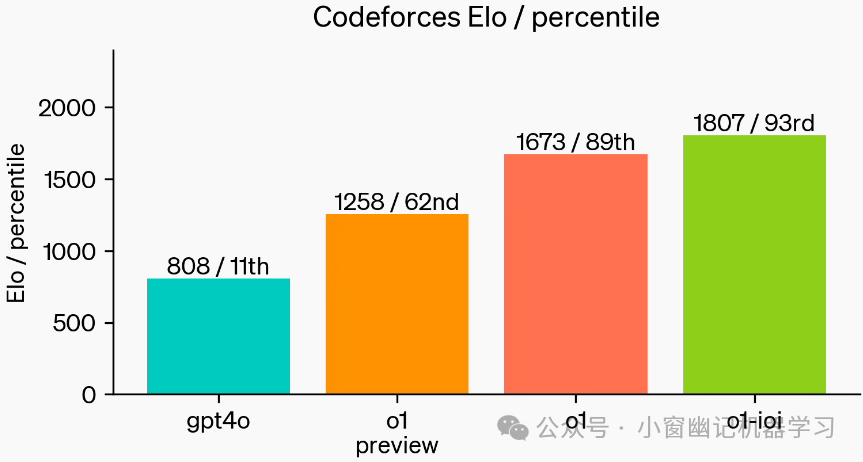
编程竞赛上进一步微调使得 o1 能力增强,并在 2024 年国际信息学奥林匹克竞赛(IOI)规则下排名前 49%。
人类偏好评估
除了考试和学术基准之外,OpenAI 还在更多领域的具有挑战性的开放式提示上评估了人类对 o1-preview 和 GPT-4o 的偏好。
在这次评估中,人类训练者对 o1-preview 和 GPT-4o 的提示进行匿名回答,并投票选出他们更喜欢的回答。在数据分析、编程和数学等推理能力较强的类别中,o1-preview 的受欢迎程度远远高于 GPT-4o。然而,o1-preview 在某些自然语言任务上并不受欢迎,这表明它并不适合所有用例。
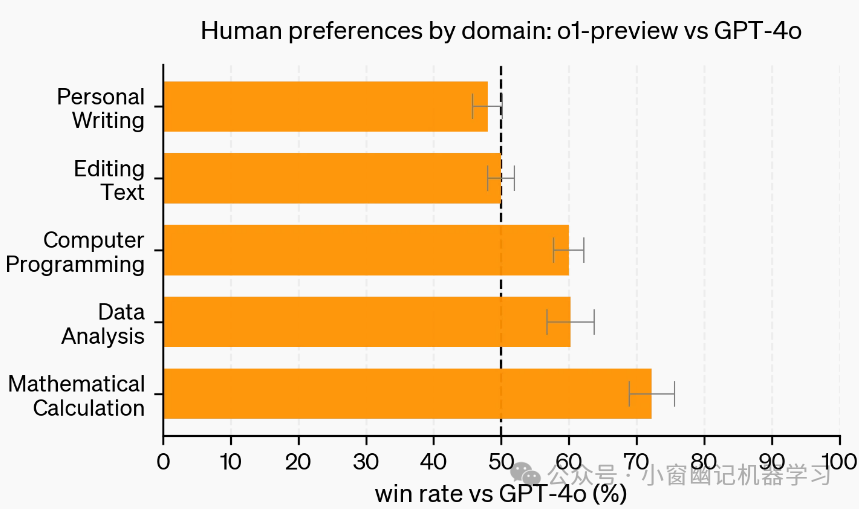
可以看出在更需要推理能力方面的任务上,人们更青睐 o1-preview的结果。
安全
思维链(CoT)推理为安全和对齐提供了新的思路。OpenAI 发现,将模型行为策略整合到推理模型的思维链中,可以高效、稳健地向模型教授人类价值观和原则。通过向模型教导人类设置的安全规则以及如何在上下文中推理它们,OpenAI发现推理能力直接有利于模型稳健性:o1-preview 在关键越狱评估和用于评估模型安全拒绝边界的最严格内部基准上取得了显著的性能提升。
OpenAI 认为,使用思维链可以为安全和对齐带来重大进步,因为 1)它能够以清晰的方式观察模型思考过程 2)关于安全规则的模型推理对于分布之外的场景更具稳健性。
为了对自己的改进进行压力测试, OpenAI 在部署之前根据自己的安全准备框架(https://cdn.openai.com/openai-preparedness-framework-beta.pdf)进行了一系列安全测试和红队测试。结果发现,思维链推理有助于在整个评估过程中提高能力。尤其值得注意的是,观察到了一些有趣的奖励机制漏洞利用实例。
隐藏思维链
OpenAI 认为隐藏的思维链为监控模型提供了独特的机会。假设它是可信的且易于理解,隐藏思维链使得能够"读懂"模型的思想并了解其思维过程。例如,人们将来可能希望监控思维链以寻找操控用户的迹象。
但要做到这一点,模型必须能够自由地以未改变的形式表达其思想,因此不能在思维链方面训练进行任何政策合规性或用户偏好性训练。OpenAI 也不想让用户直接看到不一致的思维链。
因此,在权衡用户体验、竞争优势和追求思维链监控的选项等多种因素后,OpenAI 决定不向用户展示原始的思维链。OpenAI自己也承认这个决定有不好的地方,因此努力通过教导模型在答案中重现思维链中的任何有用想法来部分弥补这一缺失。小编猜测,之所以隐藏是为了避免被构建训练数据集。同时,对于 o1 模型系列,OpenAI 展示了模型生成的思维链摘要。
总结
可以说,OpenAI o1显著提升了目前 AI 逻辑推理的最高水平。真的是遥遥领先!OpenAI 计划在不断迭代的过程中发布此模型的改进版本,并期望这些新的推理能力将提高将模型与人类价值观和原则相结合的能力。OpenAI 相信 o1 及其后续产品将在科学、编程、数学和相关领域为 AI 解锁更多新用例。
附录:
参考资料:https://openai.com/index/learning-to-reason-with-llms/

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









