









模型小型化的工作,把肥肉去掉只保留肌肉。
我的理解
参考文章及代码:
通俗易懂的知识蒸馏 Knowledge Distillation(下)——代码实践(附详细注释) - 知乎
重点在于软硬目标训练的损失函数的加入,使得学生模型的准确率比原来高。
教师模型训练后,学生模型再训练,在学生模型训练的时候,数据要经过训练好的教师模型和待训练的学生模型,再通过知识蒸馏指定的损失函数(参数有学生的输出,教师的输出,温度及其他参数),再反向传播,最后更新学生模型的梯度。

为什么叫做知识的蒸馏?
蒸馏是一种有效的分离不同沸点组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。化学蒸馏条件:(1)蒸馏的液体是混合物;(2)各组分沸点不同。
蒸馏的液体是混合物,这个混合物一定是包含了各种组分,即在我们今天讲的知识蒸馏中指原模型包含大量的知识。各组分沸点不同,蒸馏时要根据目标物质的沸点设置蒸馏温度,即在我们今天讲的知识蒸馏中也有“温度”的概念,那这个“温度“代表了什么,又是如何选取合适的”温度“?这里先埋下伏笔,在文中给大家揭晓答案。
温度作为临界点,会提取出更加精华的东西。(类比于模型的压缩)
进入我们今天正式的主题,到底什么是知识蒸馏?一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型(老师模型)学习到的知识去指导小模型(学生模型)训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
蒸馏方法
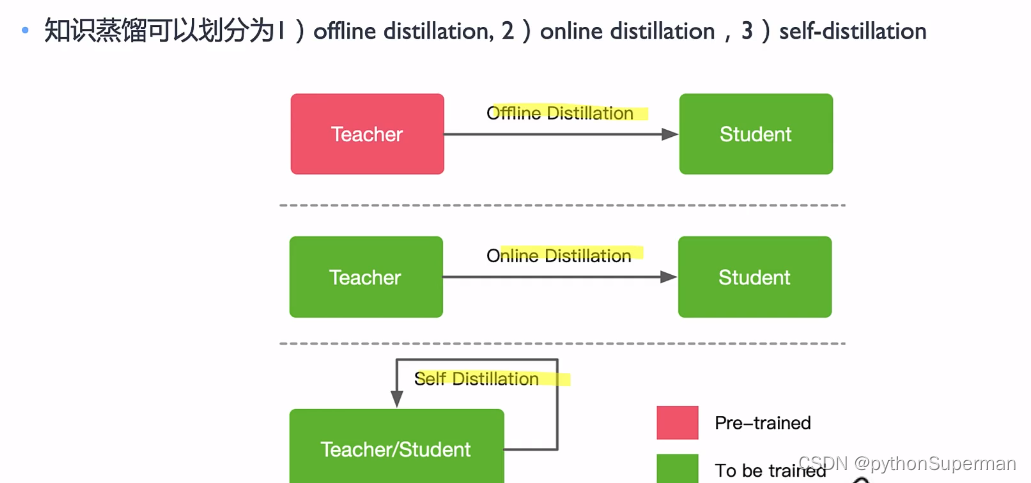
离线蒸馏
大多数蒸馏采用离线蒸馏,蒸馏过程被分为两个阶段:
1)蒸馏前教师模型预训练,需要教师模型参数量较大,训练时间较长,这种方式对学生模型的蒸馏比较搞笑。
2)蒸馏算法迁移知识。因此离线蒸馏主要侧重于知识迁移部分。
这种训练模式下的学生模型往往过度依赖于学生模型。
工业界用的比较多的是离线蒸馏,学生向预先训练好的老师学习,简单易于实现。离线蒸馏的主要关注点在知识的获取选择和损失函数的设计上。离线蒸馏的主要问题是大的teacher和小的student之间存在着model capacity gap,可能小的student就没有办法学得特别好,因为可能能力确实有限。这与人类的师生关系其实有本质的不同,人类的teacher和student只有闻道有先后的差别,没有human capacity gap。因此在人类的学习过程中,经常出现学生超过老师的情况,但在离线蒸馏中,学生往往很难超过老师。
在线蒸馏
老师学生一起学习。老师模型和学生模型的参数同时更新。
现有的在线蒸馏往往难以获得在线环境下参数量大、精度性能好的教师模型。
自蒸馏
属于在线蒸馏的其中一个特例。
自蒸馏非常有意思,同一网络同时用作teacher和student。常见的方式有低层学高层、后期学前期等。
- Offline Distillation(离线蒸馏):指知识渊博的教师向学生传授知识;
- Online Distillation(在线蒸馏):指教师和学生共同学习;
- Self-Distillation(自蒸馏):指学生自己学习知识。
Hard-target和Soft-target
训练教师网络的时候可以用hard targets,用soft targets去训练学生网络。
soft label包含了更多“知识”和“信息”,像谁,不像谁,有多像,有多不像,特别是非正确类别概率的相对大小,

Hard-target:原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。
Soft-target:Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。Soft-target:希望学习到其他额外相关的知识。
知识蒸馏用Teacher模型预测的 Soft-target 来辅助 Hard-target 训练 Student模型的方式为什么有效呢?softmax层的输出,除了正例之外,负标签也带有Teacher模型归纳推理的大量信息,比如某些负标签对应的概率远远大于其他负标签,则代表 Teacher模型在推理时认为该样本与该负标签有一定的相似性。而在传统的训练过程(Hard-target)中,所有负标签都被统一对待。也就是说,知识蒸馏的训练方式使得每个样本给Student模型带来的信息量大于传统的训练方式。
如在MNIST数据集中做手写体数字识别任务,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率会比其他负标签类别高;而另一个"2"更加形似"7",则这个样本分配给"7"对应的概率会比其他负标签类别高。这两个"2"对应的Hard-target的值是相同的,但是它们的Soft-target却是不同的,由此我们可见Soft-target蕴含着比Hard-target更多的信息。
在使用 Soft-target 训练时,Student模型可以很快学习到 Teacher模型的推理过程;而传统的 Hard-target 的训练方式,所有的负标签都会被平等对待。因此,Soft-target 给 Student模型带来的信息量要大于 Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。同时,使用 Soft-target 训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少。这也解释了为什么通过蒸馏的方法训练出的Student模型相比使用完全相同的模型结构和训练数据只使用Hard-target的训练方法得到的模型,拥有更好的泛化能力。
梯度的基本概念
在深度学习中,梯度是一个函数(通常是损失函数)相对于其输入(通常是模型的权重)的导数或偏导数。简而言之,梯度指向函数增长最快的方向,并且其大小表示函数在这个方向上增长的速度。在训练神经网络时,我们计算损失函数关于模型权重的梯度,然后使用这些梯度来更新权重,目的是减少损失,也就是改善模型的预测准确性。
硬目标训练中的梯度
在硬目标训练中,每个样本的目标是一个确定的类别标签,例如,一个样本属于第3类,其目标可能表示为[0, 0, 1, 0, ...]。这种情况下,模型对于正确类别以外的预测给予的梯度几乎为零,因为模型的任务仅仅是增加正确类别的预测概率。这可能导致梯度更新过程中出现较大的波动,因为模型对于错误类别的任何微小预测概率都不会进行调整,除非预测完全错误。
软目标训练中的梯度
软目标训练使用的是教师模型对每个类别给出的概率分布,这些概率即使对于错误类别也不是零。这意味着即使是错误类别,只要教师模型给出了一定的概率,学生模型在这些类别上的预测也会被优化,目的是更接近教师模型的概率分布。因此,每一步的梯度更新不仅仅基于一个类别的正确与否,而是基于整个概率分布的匹配程度。这导致梯度更新更加平缓,减少了训练过程中的波动。
结果
- 梯度方差更小:由于梯度更新更加平缓,训练过程中梯度的方差(即梯度大小的波动)减小。这使得训练过程更稳定,减少了因梯度爆炸或消失导致的问题。
- 更大的学习率:梯度方差较小使得可以使用更大的学习率进行训练,而不会导致权重更新过程中的不稳定。更大的学习率可以加速学习过程,使模型更快地收敛。
- 加速学习过程:由于可以使用更大的学习率,且训练过程更稳定,学生模型能够更快地学习教师模型的知识,从而更快地提高性能。
综上所述,软目标训练相比硬目标训练,通过提供更平滑的梯度更新过程,使得学习过程更稳定、更高效,从而提高了学生模型的学习能力和最终性能。
Softmax with Tempetature

当温度等于1的时候 。等于标准的softmax的函数。T越高,softmax输出的概率的分布就越平滑。
- 如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率。
- 如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码。
- 如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。
- 如果T等于无穷,就是一个均匀分布。

如何选择T


温度的特点
在回答这个问题之前,先讨论一下温度T的特点
- 原始的softmax函数是 �=1 时的特例, �<1 时,概率分布比原始更“陡峭”, �>1 时,概率分布比原始更“平缓”。
- 温度越高,softmax上各个值的分布就越平均(思考极端情况: (i) �=∞ , 此时softmax的值是平均分布的;(ii) �→0,此时softmax的值就相当于 ������ , 即最大的概率处的值趋近于1,而其他值趋近于0)
- 不管温度T怎么取值,Soft target都有忽略相对较小的 �� 携带的信息的倾向
在化学中,蒸馏是一个有效的分离沸点不同的组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。在前面提到的这个过程中,我们先让温度 T TT 升高,然后在测试阶段恢复「低温」,从而将teacher网络中的知识提取出来,因此将其称为是蒸馏。
温度代表了什么,如何选取合适的温度?
温度的高低改变的是Net-S训练过程中对负标签的关注程度: 温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Net-S会相对多地关注到负标签。
实际上,负标签中包含一定的信息,尤其是那些值显著高于平均值的负标签。但由于Net-T的训练过程决定了负标签部分比较noisy,并且负标签的值越低,其信息就越不可靠。因此温度的选取比较empirical,本质上就是在下面两件事之中取舍:
- 从有部分信息量的负标签中学习 --> 温度要高一些
- 防止受负标签中噪声的影响 -->温度要低一些
总的来说,T的选择和Net-S的大小有关,Net-S参数量比较小的时候,相对比较低的温度就可以了(因为参数量小的模型不能capture all knowledge,所以可以适当忽略掉一些负标签的信息)
underfitting和overfitting
模型就像一个容器,训练数据中蕴含的知识就像是要装进容器里的水。当数据知识量(水量)超过模型所能建模的范围时(容器的容积),加再多的数据也不能提升效果(水再多也装不进容器),因为模型的表达空间有限(容器容积有限),就会造成underfitting;而当模型的参数量大于已有知识所需要的表达空间时(容积大于水量,水装不满容器),就会造成overfitting,即模型的variance会增大(想象一下摇晃半满的容器,里面水的形状是不稳定的)。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









