







什么是类别不平衡
当每个类别的样本不平衡时,即在类别分布之间没有平衡比率时,会出现类别不平衡的问题。 这种失衡可能是轻微的,也可能是严重的。 取决于样本量,比率从1:2到1:10可以理解为轻微的不平衡,比率大于1:10可以理解为强烈的不平衡。 在这两种情况下,都必须使用特殊技术(例如欠采样,过采样,cost-sensitive代价敏感等)处理具有类不平衡问题的数据。 稍后,我们将用imblearn [1]介绍欠采样和过采样以及它们的实现。
准确率悖论
准确度这个指标看似很合理,但面对非均衡数据集时,这个指标会严重失真,甚至变得毫无意义。来看下面这个例子:数据集里有1000个数据点,其中990个为类别0,而剩下的10个为类别1,如图1所示。
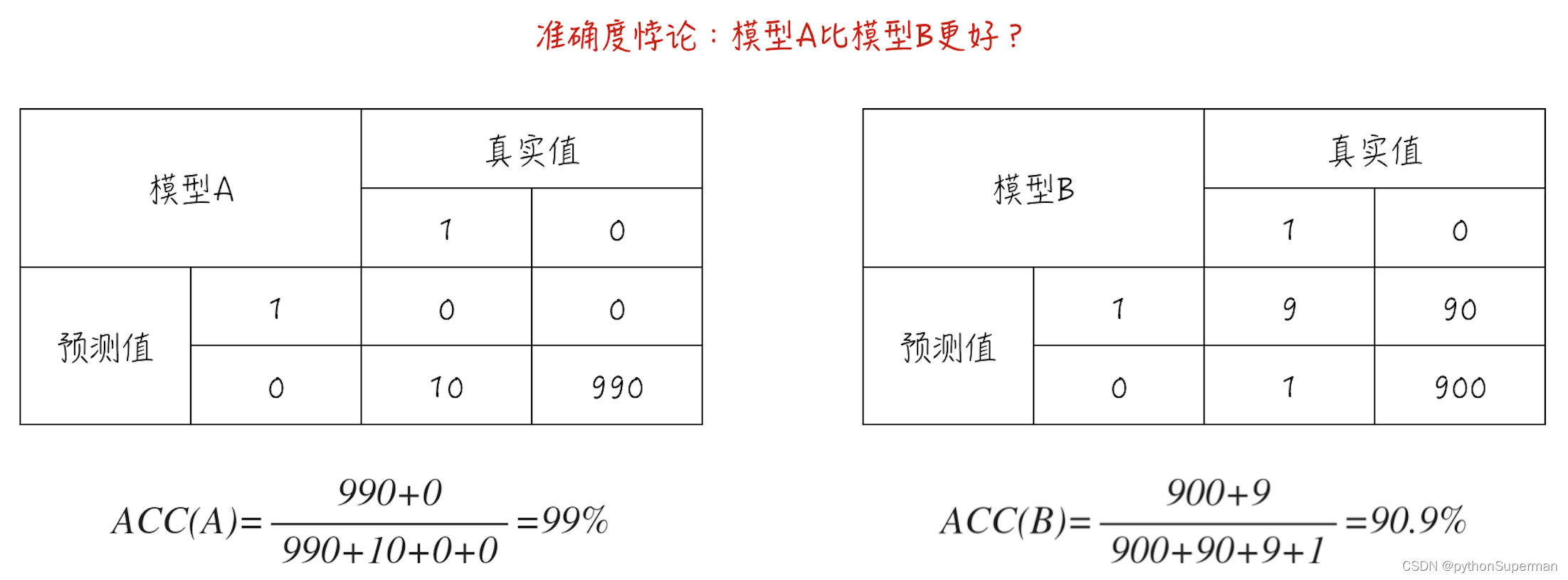
模型A对所有数据的预测都是类别0,因此这个模型其实并没有提供什么预测功能。但它的准确度却高达99%。模型B的预测效果其实很不错:对于类别1,10个数据里有9个预测正确;而对于类别0,990个数据里有900个预测正确,但它的准确度只有90.9%远低于模型A。
这就是所谓的准确度悖论:面对非均衡数据集时,准确度这个评估指标会使模型严重偏向占比更多的类别,导致模型的预测功能失效。
精确率:
在模型A里,预测0的精确率为990/1000 = 0.99。预测1的精确率为0
在模型B里,预测0的精确率为900/901 = 0.9988901。预测1的精确率为9/90 = 0.1
解决办法-修改损失函数中不同类别的权重
非均衡数据集指的是在数据集中,不同类别的样本数量极不平衡。例如,在一个医疗数据集中,患病样本(类别1)可能远少于健康样本(类别0)。
为了解决这个问题,一种常见的方法是通过修改损失函数中的类别权重。具体来说,如果某个类别的样本较少,就增加这个类别的权重。这样做的目的是增加模型对于少数类别的关注,使得模型在学习时更加“重视”这些样本。权重通常设定为类别所占比例的倒数。例如,如果某类别只占总数据的10%,那么这个类别的权重可以设为10(即1/0.1)。
但是,这种方法可能会带来一些副作用。增加少数类别的权重,会使得模型倾向于将更多的样本预测为这个少数类别。例如,原本是类别0的样本,也可能被模型错误地判定为类别1。这种现象在机器学习中被称为模型的偏见,即模型因为权重调整而过度倾向于某一类别。
在文中提到的例子中,尽管权重调整带来了一些预测错误,但整体模型的表现(以AUC为标准)还是有所提升。AUC是一个评估模型整体性能的指标,较高的AUC值表明模型具有较好的分类能力。文中还提到,调整权重后,准确率(ACC)和AUC指标几乎相等,并在图形中重叠,这说明在这种情况下,AUC和准确率给出了相似的模型评估结果。
总之,这种通过调整类别权重的方法可以提升模型对少数类别的识别能力,但也可能带来预测偏见,需要在实际应用中仔细权衡。
本来在数据不平衡的情况下,模型预测一个样本呢,更可能预测为数量多的样本,这样改进以后,会少预测为数量多的样本,更多预测数量少的样本。
在模型训练过程中,模型尽可能会去减少损失。损失越大,模型会在下一轮调整预测结果,就是将本来预测为样本多的类别预测为样本少的类别。
每一个类的损失越大,模型讲会在训练中专门为了去预测这个类去更新相关参数,使得模型越来越倾向于预测这个类。
















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









