







目录
shader学习好了,开始优化的学习,这个是现在工作息息相关的,碰到瓶颈了,把基础过一遍。
内容是学习并掌握《Unity游戏优化》(第二版)的知识。
书本内容总共9章268页。
按我学生时代的阅读书本的计划方式,1页10分钟,2680分钟,44小时,练习、研究时间应该是这个的2倍,120小时吧。一天2小时也要2个月.....,现在还打算记笔记.....
这本书针对的版本是Unity2017,英文书名是:《Unity 2019 Game Optimization》,我当前使用的Unity版本是2020.1.3f。
--------------------------------
《Unity Game Optimization - Third Edition》购买地址:https://www.packtpub.com/product/unity-game-optimization-third-edition/9781838556518
16美元,或者每个月9美元会员,一个月60....还行,没时间啃英语,还是中文掌握知识速度快。
英文第二版 PDF下载:https://download.csdn.net/download/u011003710/10339661
《Unity游戏优化》购买地址:https://item.jd.com/12652367.html
------------------------------------------------
前言
用户体验:游戏的剧情和玩法,运行时画面的流畅性、与多人服务器连接的可靠性、用户输入的响应性、最终程序文件的大小。
缺乏优化的的游戏会导致低帧率、卡顿、崩溃、输入延迟、过长的加载时间、不一致以及令人不舒服的运行时行为,以及物理引擎的故障甚至过高的电池消耗。
性能优化的目标之一是最大化地利用可用资源,包括CPU资源,如消耗的CPU循环数、使用的主存空间大小(RAM),也包括GPU资源(VRAM)、填充率、内存带宽等。
节省的资源越多,便能够在游戏中创造出更多的活动,从而产生更有趣、更生动的玩法。
要决定合适后退一步,停止增强性能。如果不这样做,就会重复实现那些很少或没有实际好处的变更,而每个变更都可能引入更多的Bug。
“用户会注意到吗?”
过早的优化是万恶之源。
过早优化是在没有任何必要证据的情况下,为提高性能而重新编写和重构代码的主要原因。
--------------------------------------------------
目录
第1章:性能问题
第2章:脚本策略
第3章:批处理的优势
第4章:处理艺术资源
第5章:加速物理
第6章:动态图形
第7章:XR优化
第8章:内存管理
第9章:提示与技巧
------------------------------------------------
我项目的主要问题是,模型太多,太大,太细,太杂,导致内存过大,渲染帧率过低。
原本采用Raycast扫描平面的方式隐藏看不到的模型,减少模型数量,一定程度上起到作用了,还是不够,感觉除了XR优化外,其他的都可能有帮助。
主要是需要培养一个系统的关于优化的知识和思路,能够具体项目具体分析的优化性能。
-------------------------------------------
第1章:研究性能问题
性能评估是一个非常科学的过程,确定所能支持的最大、最小性能指标,使用应用程序在场景中对应用程序执行负载测试,并在收集检测数据时对其进行测试。
分析和搜索性能瓶颈。
游戏应该有一个目标受众,来确定运行游戏的硬件限制是什么,需要达到什么性能目标。
执行性能测试,从多个子系统(CPU、GPU、内存、物理引擎、管道渲染)中收集性能数据。
首先证明存在性能问题,然后准确的找出瓶颈所在。
确保理解为什么会出现性能问题。
- 如何使用Unity Profiler收集分析数据
- 如何饭呢西Profiler数据以找到性能瓶颈
- 隔离性能问题并确定问题根源的技术
1.1 Untiy Profiler
Profiler通过在运行时为大量的Unity3D子系统生成使用情况和统计报告,来缩小性能瓶颈的搜索范围。
可以收集的数据:
CPU消耗量(每个主要子系统)
- 基本和详细的渲染和GPU信息
- 运行时内存分配和总消耗量
- 音频源/数据的使用情况
- 物理引擎(2D和3D)的使用情况
- 网络消息传递和活动情况
- 视频回放的使用情况
- 基本和详细的用户界面性能(2017新增)
- 全局光照统计数据
两种使用Profiler工具的方法,指令注入和基准分析。
指令注入通常意味着通过观察目标函数调用的行为,在哪里分配了多少内存,来密切观察应用程序的内部工作情况,这通常会得到当前执行情况的精确图像并可能找到问题的根源。然而并不高效,因为任何应用程序的性能分析都会带来性能损耗。
在开发模式下编译(Development Build),启用附加的编译标志,应用程序运行时生成特殊事件,被分析器记录并存储。额外的工作负载,将在运行时导致额外的CPU和内存开销。通过Unity编辑器进行分析会消耗更多的的CPU和内存,需要更新界面,渲染额外的窗口(场景),并处理后台任务。这种分析成本并非总是可以忽略不记的。在比较大的项目中,当启用Profiler时,有时会导致严重不一致的行为。在某些情况下,由于事件时机的变化和异步行为中潜在的竞争条件,这种不一致足以导致完全意外的行为。
这是为了运行时深入分析代码的行为而付出的必要代价,应该始终意识到它的存在。
体验,收集一些基本数据,执行测试场景。对用户可能体验到的东西有一个大致的感觉,在性能明显变差时持续关注一段时间,这些问题可能相当严重,需要进一步分析。
这个体验、测试活动通常称为基准分析,重要指标:FPS,总内存消耗,CPU活动的行为方式(寻找活动中较大的峰值),有时还有CPU/GPU温度。
这些指标的收集都相对简单,可以作为性能分析的最佳首选方法,一个重要的原因是:从长远来看,它会节省大量的时间,因为它确保我们只花时间研究用户会注意到的问题。
只有在基准分析测试表明需要进一步分析之后,才应该更深入地研究注入的指令。
真实的数据样本,尽可能多地模拟实际平台的行为来进行基准分析。
不应该接受通过Editor模式生成的基准数据作为真正游戏时的数据,因为Editor模式的额外开销可能会误导我们。在应用程序以独立格式在目标硬件上运行时,应将分析工具挂接到应用程序中。
Editor计算操作结果的速度有时比独立应用程序快得多,这在处理序列化数据(如音频、预制块和Scriptable Object)时特别常见,因为编辑器将缓存以前导入的数据。
连接目标设备,进行精确的基准分析测试。
1.1.1 启动Profiler
Window | Profiler

-------------------------------------------------------------
Profiler(Standalone Process)功能是2020.1版本增加的,我当前使用的是2020.1.3版本,这个模式不会影响编辑器性能。
其他新功能(https://blog.csdn.net/zhenghongzhi6/article/details/106949795/):
Profiler作为单独程序启动
Profiler可以独立于Unity启动一个单独的进行,可以减少对编辑器造成的性能问题,并且采集的数据更为精准
Profile Analyer包的更新
这个包可以让你比较帧之间的数据,更容易找出影响性能的问题所在。
Recorder API增加GPU信息
2020.1之前,Profile的Recorder API只能获取CPU的信息,现在也可以获取GPU的profile信息了
C# Profiler API支持自定义数据
Profiler增加了底层的API,支持自定义跟踪字符串或数字类型的数据,可以在Profiler中看到跟踪项对应的值。
Job调度可视化
如下图所示开启Show Flow Events后,可以可视化看到主线程的代码执行时,等待多线程中的Jobs如何在多个线程中调度并执行完成
-------------------------------------------------------
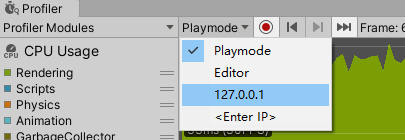
Playmode:编辑器运行模式分析
Editor:编辑器编辑模式分析
127.0.0.1:连接本机Development Build打包程序分析
<Enter IP>:连接其他机器分析
1.编辑器或者独立运行的实例
编辑器:启动Profiler,进入运行模式。
独立运行:启用了DevelopmentBulild和Autoconnect Profiler标志。

2.连接到WebGL实例
可以在构建WebGL应用程序并从编辑器中运行它时,确保启用DevelopmentBuild和AutoconnectProfiler标志。
Profiler连接只能在应用程序首次从Editor中启动时建立。
3.连接到iOS设备
通过共享Wi-Fi连接来实现。
从ConnectedPlayer中选择设备。
,这个下拉框就是ConnectedPlayer
Profiler使用54998~55511的端口来广播分析数据。如果系统存在防火墙,确保这些端口可用于向外发送数据。
4.远程连接到Android设备
通过Wi-Fi连接或使用Android Debug Brideg(ADB)工具。
5.编辑器分析
分析编辑器自身,在分析自定义的编辑器脚本时使用。
1.1.2 Profiler窗口
Profiler窗口分4个部分:Profiler控件、时间轴视图、细分视图控制栏、细分视图

1.Profiler控件
默认情况下,Profiler将为几个不同的子系统收集数据,这些子系统被组织成包含相关数据的各个区域。

GPU子系统默认不收集,会导致内存溢出。
对于独立的应用程序,它(应用程序)必须时活动的窗口,不然会挂起收集数据。
Deep Profile
普通的分析只记录常见Unity回调方法(如Awake,Start,Update和FiexedUpdate)所返回的时间和内存分配信息。启用Deep Profile选项可以用更深层次的的指令重新编译脚本,运行它统计每个调用的方法。这导致运行时的指令注入成本比正常情况下要大的多,并要使用大量的内存,因为在运行时收集的是整个调用堆栈的数据。因此,在大型项目中,Deep Profiling甚至是不可能的,因为Unity可能在测试开始之前就用完了内存,或者应用程序可能运行得太慢,以至于测试变得毫无意义。
切换DeepProfile需要完全重新编译整个项目,才能再次开始分析,避免在测试中来回切换。
在大多数分析测试中启用这个选项是不明智的。测试一个小场景的性能时,可以使用这个选项来隔离某种行为。
如果较大的项目和场景需要使用Deep Profiling,但Deep Profile选项在运行时会阻碍性能,那么可以使用其他方法来进行更详细的分析,如“针对代码片段的分析”。
2.时间轴视图
时间轴视图显示运行期间收集的分析数据,将其组织到一系列的区域中。每个区域关注Unity引擎中不同子系统的分析数据。
在时间轴视图中选中一个区域时,在当前选中帧的细分视图中(时间轴视图下方)会显示子系统的更多详细信息。根据在时间轴视图中选中的区域不同,细分视图将显示不同类型的信息。
3.细分视图控件栏
根据时间轴上选中的区域,细分视图控制栏内将显示不同的下来框和切换按钮选项。
4.细分视图
根据当前选择的区域以及在细分视图控件栏中选择的选项,细分视图中显示的信息会有很大的不同。
- “CPU使用”区域
CPU所有的使用情况和统计数据。它可能时最复杂、最有用的,因为它包括Unity的大量子系统,诸如MonoBehaviour组件、摄像机、一些渲染和物理处理、用户界面、音频处理、Profiler等。
细分视图中的三种模式:Hierarchy模式,Raw Hierarchy模式,Timeline模式。
Hierarchy模式显示大部分调用栈的调用,还会合并类似的数据元素和Unity的全局函数的调用。
Hierarchy模式有助于作为第一步,来决定执行哪个函数调用会花费最多的CPU时间。
Raw Hierarchy模式不会合并,比较难以阅读,但是更清楚每个函数被调用了多少次。
Timeline模式是最有用的模式,将细分视图垂直组织到不同的部分,代表运行时的不同线程,例如主线程、渲染线程和各种后台工作线程,称为UnityJobSystem,用于加载诸如场景和其他资源等活动。
水平轴表示时间,垂直轴代表调用栈。
Timeline模式提供了一种非常清晰、条理分明的方式,以明确调用栈中的哪个方法消耗的时间最多,以及处理时间如何与同一帧中调用的其他方法进行比较。
- “GPU使用”区域
发生在GPU上的方法调用和处理时间。这个区域中的相关Unity方法调用与摄像机、绘制、不透明的和透明的几何图形、光照和阴影等有关。
提供了和CPU类似的层级信息,并估计调用各种渲染函数所花费的时间。
通常,“GPU使用”区域对于检测问题最有效果,这些问题能通过第2章中研究的方案来解决。

- “渲染”区域
提供了一些常用的渲染统计数据,关注GPU为渲染而准备的相关活动,这一系列活动发生在CPU上(与渲染行为不同,渲染是在GPU内部处理的,在“GPU使用情况”区域显示详情)。

和Game视图的Stats信息差不多

可以打开Frame Debugger,详见第3章”批处理的优势”,还有第6章。

- "内存“区域
Simple模式

第8章在深入学习内存管理的复杂性。
- “音频”区域
音频需要大量潜在的磁盘访问和CPU处理,第4章讨论。
- Physics和Physics(2D)
物理统计数据,Physics Debbuger
第5章“物理加速”

- 网络消息和网络操作区域
Unity网络系统的信息,所显示的信息取决于应用程序是否使用Unity提供的高级API(HLAPI)或传输层API(TLAPI)。HLAPI是一个更易用的系统,用于管理Player和GameObject自动网络同步,而TLAPI只是套接字层级上操作的一个薄层,它运行Unity开发者构建自己的网络系统。
网络拥塞优化本书不具体介绍。
- “视频”区域
分析视频回放行为,不予讨论
- UI和UI详情
用于洞察使用Unity内建UI系统(UGUI)的应用程序。
优化差的UI通常会影响CPU和/或GPU,第2章、第6章。
- 全局光照
这个区域在第6章研究光照和阴影时会很有用。















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









