







文章目录
前言
自Yolov3结束,其作者不再在该系列进行研发,后续开启了工业界的狂潮,诸多公司开始研究目标检测算法的实时落地应用。
YOLOv4可以说是目标检测各种小技巧(tricks)的大总结,将其推向了工业界。
ps:YOLOv4算法是在原有YOLO目标检测架构的基础上,采用了近些年CNN领域中最优秀的优化策略,从数据处理、主干网络、网络训练、激活函数、损失函数等各个方面提出各种tricks总结,虽没有理论上的创新,但是将其应用推向高峰。文章如同目标检测的trick综述,尝试了各种优化算法,效果达到了实现FPS与Precision平衡的目标检测 new SOTA。
YOLOv4将技巧分为了bag of freebies(BoF)和bag of specials(BoS)两种,BoF指的是只增加训练的成本而不增加推理的成本的技巧,通常是预处理和后处理;BoS指的是只增加一点推理成本却可以显著提高模型效果的技巧,通常是模型结构上的变化。
提示:以下是本篇文章正文内容,下面内容可供参考
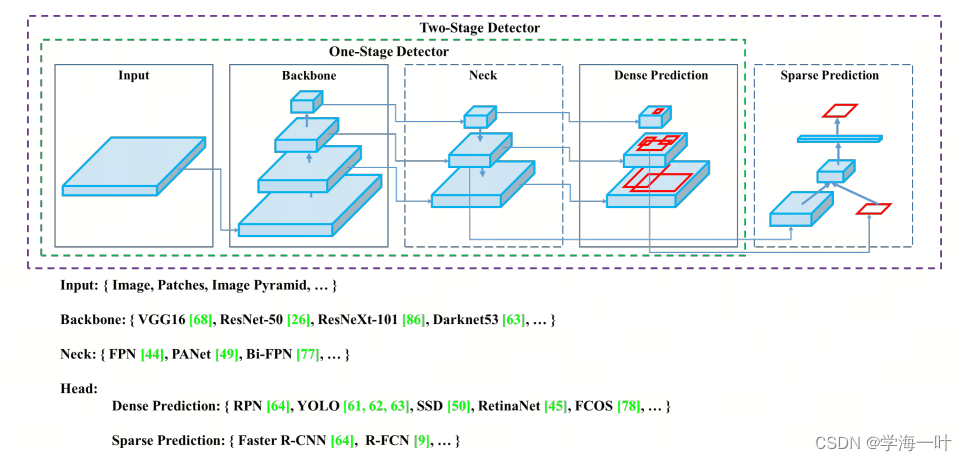
一、目标检测网络组成
总结了目标检测网络的组合和常见组件:包括输入、backbone、Neck(如特征融合网络)、Heads(检测网络)

二、BoF(Bag of Freebies)
指只改变训练策略或只增加训练成本,而不增加推理成本的方法
1. 数据增强
传统的处理手段如下:
- 光学失真法:调整图像的亮度、对比度、色调、饱和度和噪声
- 几何失真法:随机缩放、裁剪、翻转和旋转
上述数据增强方法都是逐像素调整,并且保留调整区域中的所有原始像素信息,更多的应用于图像分类领域,目标检测领域研究人员则将重点放在模拟对象遮挡问题上
CutOut和随机擦除(random erase):随机删除一个矩形区域(填充零/均值)hide-and-seek和grid mask:随机或均匀地选择图像中的多个矩形区域,并将它们全部替换为零
如果将上述理念用于特征图(feature maps),则有如下方法:
DropOut:随机将某层特征图中的元素 置零DropConnect:随机将某层的部分连接权重 置零DropBlock:随机将某层特征图中的一些矩形区域 置零
此外,一些研究人员提出了将多个图像一起使用来进行数据增强的方法:
MixUp:随机选择两个样本,对它们的输入和标签进行线性插值,从而生成一个新的样本,其输入是两个原始样本输入的线性组合,标签也是对应标签的线性组合。 λ \lambda λ是一个从 Beta 分布中采样的超参数。通常, λ \lambda λ取一个较小的值,比如 0.2
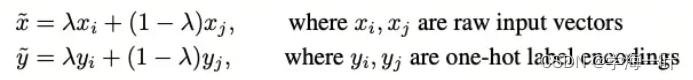
CutMix:从图像中生成掩码(mask),实质上是一个矩形块,将两幅图像的mask区域互换,对新的图像进行标签混合

此外,也有利用生成式方法的数据增强,如style transfer GAN
2.语义分布偏差问题
在处理语义分布偏差问题时,有两个非常重要的问题
- 一是不同类别之间存在数据不平衡的问题
- 二是独热码这种标签编码方式很难表达不同类别之间的关联度关系
Two Stage检测器中,通常通过的硬反例挖掘(hard negative example mining)或在线硬例挖掘(online hard example mining)来解决数据不平衡问题,但实例挖掘方法不适用于One Stage检测器,因为这种检测器属于密集预测结构。何恺明大神提出了focal loss来解决此问题,关于focal loss,在目标检测-One Stage-RetinaNet中有介绍。
ps:
- 硬负样本挖掘的目标是找到对当前模型来说相对难以分类的负样本,以便加强训练模型对这些困难样本的处理能力,处理流程是:在每轮训练中,模型会首先使用当前参数对数据进行预测。然后,从被错误分类的负样本中选择那些“难以置信”的样本,即模型对其置信度较高的负样本,将其用于更新模型参数。
- 在线硬例挖掘的目标是找到对当前模型来说相对难以分类的样本,在训练过程中,每一步都实时选择那些难以处理的样本,而不是依赖于先前的训练轮次。
为解决问题二,可将硬标签转换为软标签进行训练,这可以使模型更加鲁棒,同时为了获得更好的软标签,Islam等人引入了知识蒸馏的概念来设计标签精化网络。
ps:
- 以独热码举例说明软硬标签,硬标签:[0, 1, 0],软标签:[0.1, 0.7, 0.2],一个模型经过训练后它输出的往往是软标签,软标签比硬标签具有更多的知识。
知识蒸馏
知识蒸馏就是把一个大模型的知识(软标签)迁移到小模型上,既要学习真实标签,也就是硬标签,还要学习大模型给的软标签,那么可将损失函数定义为:
L = t a r g e t h a r d + t a r g e t s o f t = α C E ( y , p ) + β C E ( q , p ) L = target_{hard } + target_{soft} = \alpha CE(y,p) + \beta CE(q,p) L=targethard+targetsoft=αCE(y,p)+βCE(q,p)
其中y是真实标签,p是小模型的预测,q是大模型的预测,CE是交叉熵损失, α \alpha α和 β \beta β是超参数
ps:
- 需要注意的是,要是直接使用大模型softmax层的输出值作为q的话,会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。
- 因此在softmax函数中加入了温度变量(T),让每个类的预测差距不那么大:

3.损失函数
-
对于目标框的定位,之前的做法是将其看作回归问题,采用MSE作为损失函数(L1或L2),直接回归框的位置{ x c e n t e r , y c e n t e r w , h x_{center}, y_{center}w, h xcenter,ycenterw,h},如果是基于anchor的则是回归偏移量{ x c e n t e r o f f s e t , y c e n t e r o f f s e t , w o f f s e t , h o f f s e t x_{center} offset, y_{center} offset, w_{offset}, h_{offset} xcenteroffset,ycenteroffset,woffset,hoffset}
-
这样直接估计BBox每个点的坐标值,就是将这些点视为自变量,但实际上并没有考虑对象本身的完整性(即未考虑bbox四个顶点之间的相关性),模型在训练过程中会更偏向于尺寸更大的物体
因此出现了基于IoU的loss,将目标框看成一个整体来回归,IoU loss的定义是先求出2个框的IoU,然后再求负对数,即
-ln(IoU),在实际使用中则常用如下公式:IoU Loss = 1-IoU。并产生了一系列改进的IoU Loss,其中主要是对IoU的改进,包括GIoU、DIoU、CIoU
IoU
IoU就是交集比上并集,如下图所示:
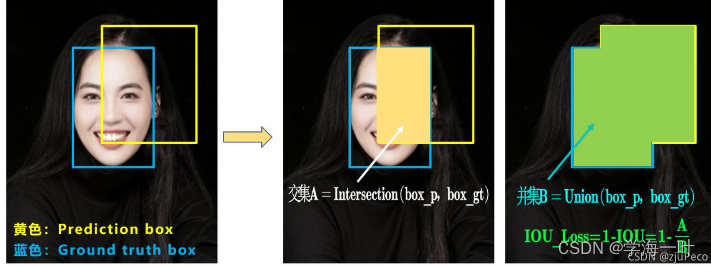
这种计算方法真实框和预测框交叉情况的算法有如下缺点:

- 如左图所示,当预测框与真实框完全没有交叠时,不管预测框离真实框多远,IoU都是一样的,但其实离真实框近的比离真实框远的要好一些。
- 如中图和右图所示,当交集和并集一致时,不同方向的预测框得到IoU是一样的,但其实右图比中图要好一点,因为中图的中心点对齐需要预测框的水平和垂直都发生比较大的变化,而右图只需要水平平移即可
GIoU
为了解决上述的两个缺点,有了GIoU(
G
I
o
U
=
I
o
U
−
差集
/
最小外接矩形
GIoU= IoU − 差 集 / 最 小 外 接 矩 形
GIoU=IoU−差集/最小外接矩形),如图所示
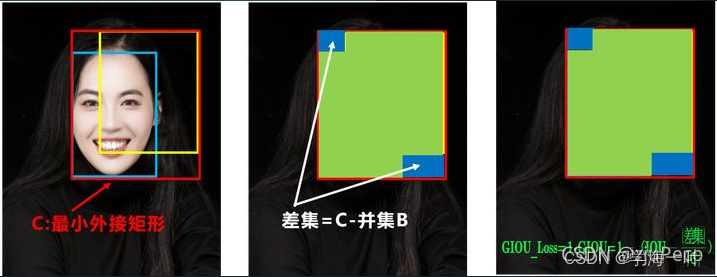
但GIoU仍存在问题:当预测框在真实框内部的时候,不管预测框在那个位置,GIoU都是一样的,但是下图的中图显然是优于左图和右图的,因为中图的水平和垂直方向的坐标已经对齐了,只需要改变长宽即可。

DIoU
为了解决上述缺点,出现了DIoU(
D
I
o
U
=
I
o
U
−
(
D
i
s
t
a
n
c
e
_
2
)
/
(
D
i
s
t
a
n
c
e
_
C
)
DIoU= IoU- (Distance\_2) / (Distance\_C)
DIoU=IoU−(Distance_2)/(Distance_C)),如图所示

但是DIoU没有考虑长宽比
CIoU
最终诞生了CIoU
C I o U = I o U − D i s t a n c e _ 2 2 D i s t a n c e _ C 2 − v 2 1 − I o U + v CIoU=IoU−\frac{Distance\_2^2}{Distance\_C^2}− \frac{v^2}{1−IoU+v} CIoU=IoU−Distance_C2Distance_22−1−IoU+vv2
其中,v是长宽比的一致性参数,定义为
v
=
4
π
(
a
r
c
t
a
n
w
g
t
h
g
t
−
a
r
c
t
a
n
w
p
r
e
d
h
p
r
e
d
)
2
v=\frac{4}{π}(arctan \frac{w_{gt}}{h_{gt}} − arctan \frac{w_{pred}}{h_{pred}})^2
v=π4(arctanhgtwgt−arctanhpredwpred)2
三、BoS(Bag of Specials)
指只增加一点推理成本,而使精度显著增加的方法
对于那些只会少量增加推理成本但能显著提高对象检测精度的插件模块和后处理方法,我们称之为“特殊包”。一般来说,这些插件模块用于增强模型中的某些属性,如扩大感受野、引入注意力机制或增强特征集成能力等,后处理是筛选模型预测结果的一种方法。
增强感受野
- 可用于增强感受野的常见模块有:SPP(空间金字塔池化)、
ASPP和RFB
ps:SPP的输出是一维张量,不适用于全卷积网络,因此YOLOv3采用了核为k的max-pooling( k = {1; 5; 9; 13},stride=1),在这种设计下,相对较大的k×k最大池化有效地增加了主干特征的感受野
注意力机制
- 注意力常见模块有:
Squeeze-and-Excitation (SE),Spatial Attention Module (SAM)
ps:
SE模块可以将ResNet50在ImageNet图像分类任务中的能力提高1%(top-1的准确度),只需增加2%的计算工作量,但在GPU上,它通常会增加约10%的推理时间,因此更适合用于移动设备
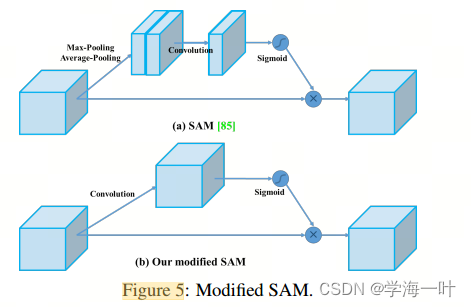
SAM模块可以将ResNet50-SE在ImageNet图像分类任务中的能力提高0.5%(top-1的准确度),只需要增加0.1%的额外计算量。最棒的是,它根本不会影响GPU上的推理速度。作者改进了SAM模块
特征融合
- 最早使用
skip connection或hyper-column将低级物理特征集成到高级语义特征 - 多尺度特征融合方法:
FPN、SFAM、ASFF、BiFPN、PANet
激活函数
ReLU、LReLU、PReLU、ReLU6、标度指数线性单元(SELU)、Swish、hard Swish和Mish
ps:
- ReLU用于解决传统tanh和sigmoid激活函数中经常遇到的梯度消失问题
- LReLU和PReLU的主要目的是解决当输出小于零时ReLU的梯度为零的问题
- ReLU6和hard Swish,它们是专门为量化网络设计的
- 对于神经网络的自归一化,提出了SELU激活函数来满足这一目标
后处理
-
R-CNN中添加了分类置信度得分作为参考,并根据置信度得分的顺序,按照高分到低分的顺序进行
贪婪NMS -
软NMS,考虑了对象的遮挡可能导致具有IoU分数的贪婪NMS的置信度分数下降的问题。 -
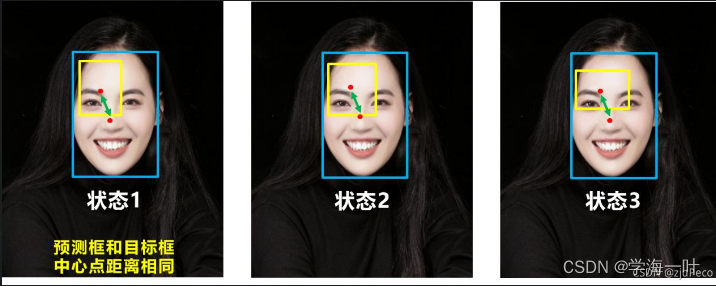
DIoU NMS开发人员的思路是在软NMS的基础上,将中心点距离的信息添加到BBox筛选过程中。
值得一提的是,由于上述后处理方法都没有直接参考捕获的图像特征,因此在后续开发无anchor方法时不再需要后处理
四、YOLO v4的网络结构和创新点
1.缓解过拟合(BoF)
- CutMix:基于MixUp,区别在于不对影像进行线性插值,而是将从影像中随机裁剪一块影像到另一张影像上
- Mosaic:把4张图片,通过随机缩放、随机裁减、随机排布的方式进行拼接
- Class label smoothing:即将硬标签转为软标签
- DropBlock正则化和CmBN归一化
2. 网络结构的改进(BoS)
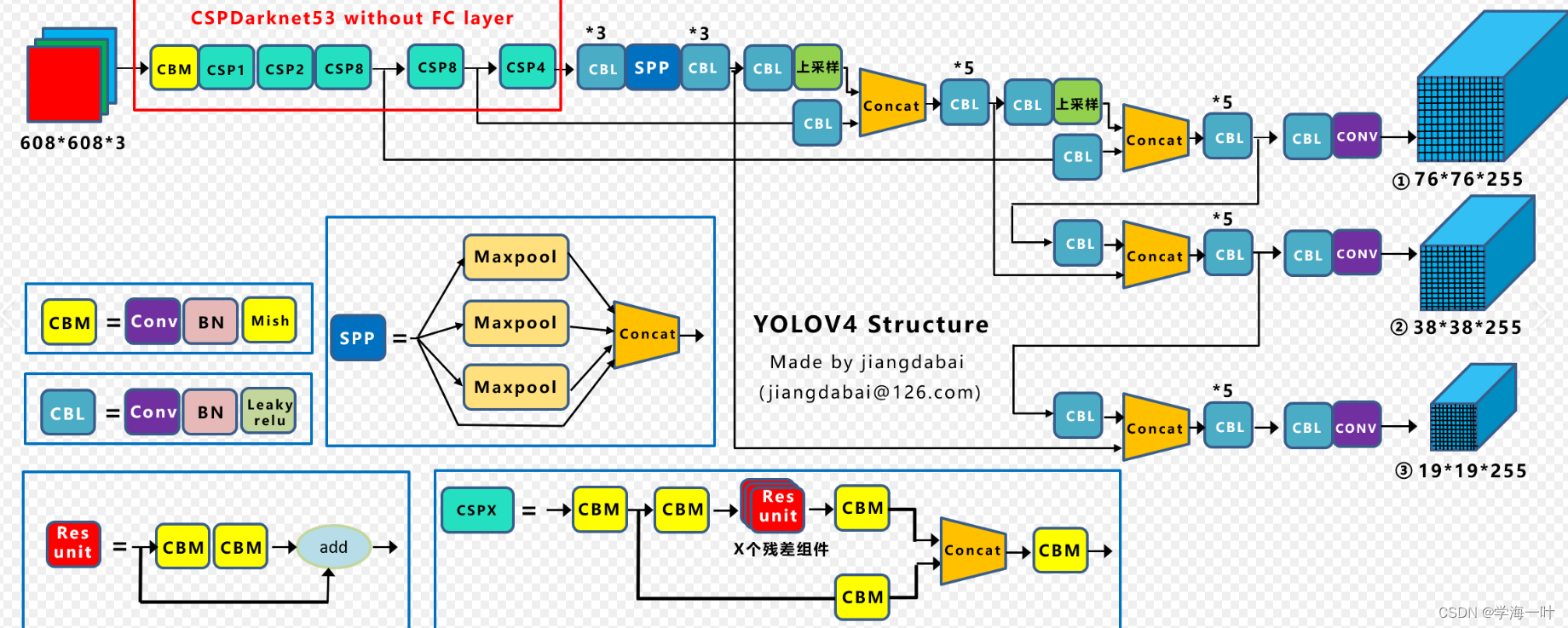
ps:将Darknet53修改为CSPDarknet53
- backbone:
- 1)卷积块从CBL->CBM(激活函数从Leaky relu改为Mish);
- 2)Res残差块改成了CSP残差块(Cross-stage partial connections),增加了一路CBM
- 3)在特征融合时,加入了加权残差连接(MiWRC)-对每个残差连接加上一个可学习的系数,可使得模型能在训练初期更加稳定,进而促进整个训练过程
- neck:
- 1)新增SPP模块,增大感受野;
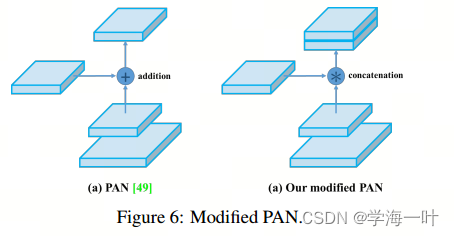
- 2)改进PAN结构,从add改为concat,且输出特征金字塔尺寸由从小到大变为从大到小,这主要是为了增加特征融合性,使feature map中融合更多层的信息
ps:
3. 训练(BoF)
- 边框回归loss的修改:MSE改为CIOU loss
- 学习率衰减策略:余弦退火(Cosine annealing scheduler)
- 自对抗训练(Self-Adversarial Training,SAT):实质上代表了一种新的数据增强技术
ps:SAT技术分为 2 个训练阶段:
- 为了最小化成本函数,神经网络会改变原始图像而不是网络权重。与通常的方法相反,这实际上会降低网络性能,或者简单地说,模型会对自己进行“对抗性攻击”,改变原始图像以产生图像上没有所需对象的欺骗。
- 使用第一阶段修改后的图像用于在第二次迭代中训练网络。通过这种方式,能够减少过拟合并使模型更具通用性。
3. 后处理(BoS)
- 在训练的时候用的是CIOU,但是在做nms的时候,用的DIOU。用DIOU可以把一些重叠度很高的框,但表示不同物体的给保留下来
总结
在目标检测的所有tricks中,一些专门针对某些模型,专门针对某些问题,或仅针对小规模数据集进行操作;而另一些tricks,如批处理规范化和残差连接,适用于大多数模型、任务和数据集。
YOLOv4假设这些通用tricks包括加权残差连接(WRC)、跨阶段部分连接(CSP)、跨小批量归一化(CmBN)、自对抗性训练(SAT)和Mish激活。
YOLOv4使用了如下tricks:WRC、CSP、CmBN、SAT、Mish激活、Mosaic数据增强、CmBN,DropBlock正则化和CIoU loss,并将其中一些功能结合起来,实现了SOTA:在Tesla V100上,针对MS COCO数据集的AP为43.5%(AP50为65.7%),实时速度为~65 FPS。















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











