





 本文深入探讨了ResNet网络的设计理念,解释了为何简单的增加卷积层会导致梯度问题,而残差网络如何解决这一难题。ResNet通过恒等映射和残差映射的结合,有效防止了信息丢失,简化了学习目标,降低了学习难度。文章详细介绍了ResNet-34的网络结构,包括Block块和Layer层的概念,并提供了PyTorch代码实现。
本文深入探讨了ResNet网络的设计理念,解释了为何简单的增加卷积层会导致梯度问题,而残差网络如何解决这一难题。ResNet通过恒等映射和残差映射的结合,有效防止了信息丢失,简化了学习目标,降低了学习难度。文章详细介绍了ResNet-34的网络结构,包括Block块和Layer层的概念,并提供了PyTorch代码实现。
为什么ResNet
1 . 简单地增加卷积层导致梯度发散或梯度爆炸
2. 残差网络可以消除这种现象
ResNet 思想
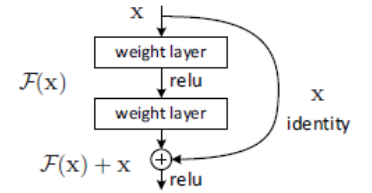
网络输出为 恒等映射 + 残差映射
好处
1 .由学习完整的输出变为学习残差,解决卷积过程的信息丢失。
2 . 通过将输入直接绕道传递到输出,保护了信息的完整性。
3 . 学习目标简化,降低了学习难度。
网络结构
block 块
ResNet-34 网络结构,当然还有其他变种如 ResNet-18 , ResNet-50 ,ResNet-101 等
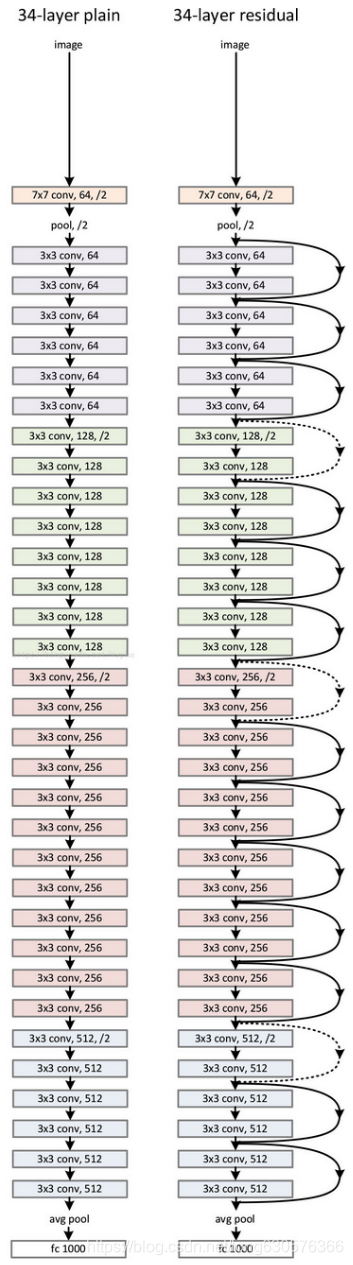
ResNet 网络结构:
- Block 块 : 一个残差块,定义残差网络结构
- Layer 层: 由数个Block 块叠加形成的一个层,每个层内的 Channel 相等。
一般是在层与层之间卷积后进行 Channel 数变换,同时缩减图像尺寸。
pytorch 代码实现
1. Block 块
定义 卷积分支,shortcut 分支
class resblock(nn.Module): ## that is a part of model
def __init__(self,inchannel,outchannel,stride=1):
super(resblock,self).__init__()
## conv branch
self.left = nn.Sequential( ## define a serial of operation
nn.Conv2d(inchannel,outchannel,kernel_size=3,stride=stride,padding=1),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel,outchannel,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(outchannel))
## shortcut branch
self.short_cut = nn.Sequential()
if stride !=1 or inchannel != outchannel:
self.short_cut = nn.Sequential(
nn.Conv2d(inchannel,outchannel,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(outchannel))
### get the residual
def forward(self,x):
return F.relu(self.left(x) + self.short_cut(x))
由Block 搭建残差网络 ResNet-34
class ResidualNet(nn.Module):
def __init__(self,resblock,input_channel,classnum):
super(ResidualNet,self).__init__()
## preprocess layer
self.pre = self._pre(input_channel,64)
## resnet layer
self.layer1 = self._makelayer(resblock,64,64,3,stride=1)
self.layer2 = self._makelayer(resblock,64,128, 4,stride=2)
self.layer3 = self._makelayer(resblock,128,256,6,stride=2)
self.layer4 = self._makelayer(resblock,256,512,3,stride=2)
## full connect layer
self.pool = nn.AvgPool2d(kernel_size=4,stride=1,padding=0)
self.fc = nn.Linear(512 ,classnum)
def forward(self,x):
x1 = self.pre(x)
x2 = self.layer1(x1)
x3 = self.layer2(x2)
x4 = self.layer3(x3)
x5 = self.layer4(x4)
#print "x5.shape = ", x5.shape
x6 = self.pool(x5)
x6 = x6.view(x6.size(0),-1)
x6 = self.fc(x6)
return x6
def _pre(self,input_channel,outchannel):
pre = nn.Sequential(
nn.Conv2d(input_channel,outchannel,kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=1,padding=1))
return pre
def _makelayer(self,resblock,inchannel,outchannel,blockmum,stride=1):
strides = [stride] + [1] * (blockmum -1)
layers = []
channel = inchannel
for i in range(blockmum):
layers.append(resblock(channel,outchannel,strides[i]))
channel = outchannel
return nn.Sequential(*layers)
def ResNet_34():
return ResidualNet(resblock,3,10)


















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









