







文章目录
本文翻译自:https://github.com/huggingface/text-generation-inference
一、关于 Text Generation Inference
TGI : Text Generation Inference
TGI 是一个用于部署和服务大型语言模型(LLM)的工具包。使用 Rust、Python 和 gRPC 服务。
在 HuggingFace 的生产中使用,为 Hugging Chat、推理 API 和推理端点提供动力。
为最流行的开源 LLM 提供高性能文本生成功能,包括 Llama、Falcon、StarCoder、BLOOM、GPT-NeoX 和 更多。
- 官方文档 : https://huggingface.co/docs/text-generation-inference/index
- github : https://github.com/huggingface/text-generation-inference?tab=readme-ov-file
-
Text-generation-inference (TGI) deployment optimization and benchmarking
-
小工蚁创始人:TGI让Huggingface Transformer推理速度提升10倍(2023-07-03)
https://www.bilibili.com/video/BV1g14y1o7Yz/
功能特性
TGI 实现了许多功能,例如
- 简单的启动器,为最常用的 LLM 提供服务
- 生产可用(使用 Open Telemetry 和 Prometheus metrics 进行分布式跟踪)
- 在多个 GPU 上实现更快推理的张量并行性
- 使用服务器发送事件(SSE)的令牌流
- 连续批处理传入请求,提高总吞吐量
- 在最流行的架构上使用Flash Attention和Paged Attention进行推理的优化转换器代码
- 使用以下量化:
- Safetensors weight 加载
- 使用 A Watermark for Large Language Models 处理水印
- Logits warper(temperature scaling、top-p、top-k、重复惩罚,详见 transformers.LogitsProcessor
- 停止序列
- 对数概率
- 推测 ~2倍延迟
- Guidance/JSON. 指定输出格式以加快推理速度,并确保输出是有效的。
- 自定义提示生成:通过提供自定义提示来指导模型的输出,从而轻松生成文本
- 微调支持:利用微调模型执行特定任务,以实现更高的精度和性能
硬件支持
二、开始使用
1、Docker
更详细的使用向导,可以看 Quick Tour.
最简单的入门方法,是使用官方提供的 Docker container:
model=HuggingFaceH4/zephyr-7b-beta
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model
然后你可以发送请求:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
Note: 为了使用 NVIDIA GPUs, 你需要安装NVIDIA Container Toolkit.
我们也建议使用 CUDA 12.2 及以上版本 来使用 NVIDIA drivers。
对于在没有GPU或CUDA支持的机器上运行Docker容器,只需删除 --gpus all 标志并添加 --disable-custom-kernels 就足够了,请注意CPU不是该项目的预期平台,因此性能可能较差。
Note: TGI 支持 AMD Instinct MI210 and MI250 GPUs.
可以在这里查看详情 Supported Hardware documentation.
为了使用 AMD GPUs, 请使用替代以上命令
docker run --device /dev/kfd --device /dev/dri --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4-rocm --model-id $model
查看可用的命令选项:
text-generation-launcher --help
2、API 文档
您可以使用/docs 路由查阅text-generation-inference REST API的OpenAPI文档。
Swagger UI也可在以下位置获得:< https://huggingface.github.io/text-generation-inference> 。
3、使用个人或者 gated model
您可以选择使用 HUGGING_FACE_HUB_TOKEN 环境变量来配置 TGI 所使用的令牌。
这允许您访问受保护的资源。
例如,如果要为 gated Llama V2 模型提供服务:
- 前往 https://huggingface.co/settings/tokens
- 复制你的 cli READ token
- Export
HUGGING_FACE_HUB_TOKEN=<your cli READ token>
或者使用 Docker :
model=meta-llama/Llama-2-7b-chat-hf
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
token=<your cli READ token>
docker run --gpus all --shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model
4、关于共享内存 (shm)
NCCL 是 PyTorch 用来进行分布式训练/推理的通信框架。
TGI 利用 NCCL 使张量并行,大大加快了大型语言模型的推理速度。
为了在 NCCL 组的不同设备之间共享数据,如果不能对等使用NVLink或PCI,则 NCCL 可能会回退到使用主机存储器。
为了允许容器使用1G的共享内存 并支持SHM共享,我们在上面的命令中添加了 --shm-size 1g 。
如果你在 Kubernetes 中运行 TGI,您还可以通过以下方式创建卷,将共享内存添加到容器中:
- name: shm
emptyDir:
medium: Memory
sizeLimit: 1Gi
将它挂载到 /dev/shm。
最后,还可以使用 NCCL_SHM_DISABLE=1 环境变量禁用SHM共享。
但是,请注意,这将影响性能。
5、分布式跟踪
text-generation-inference 使用OpenTelemetry进行分布式跟踪。
您可以通过使用 --otlp-endpoint 参数将地址设置为OTLP收集器,来使用此功能。
6、架构
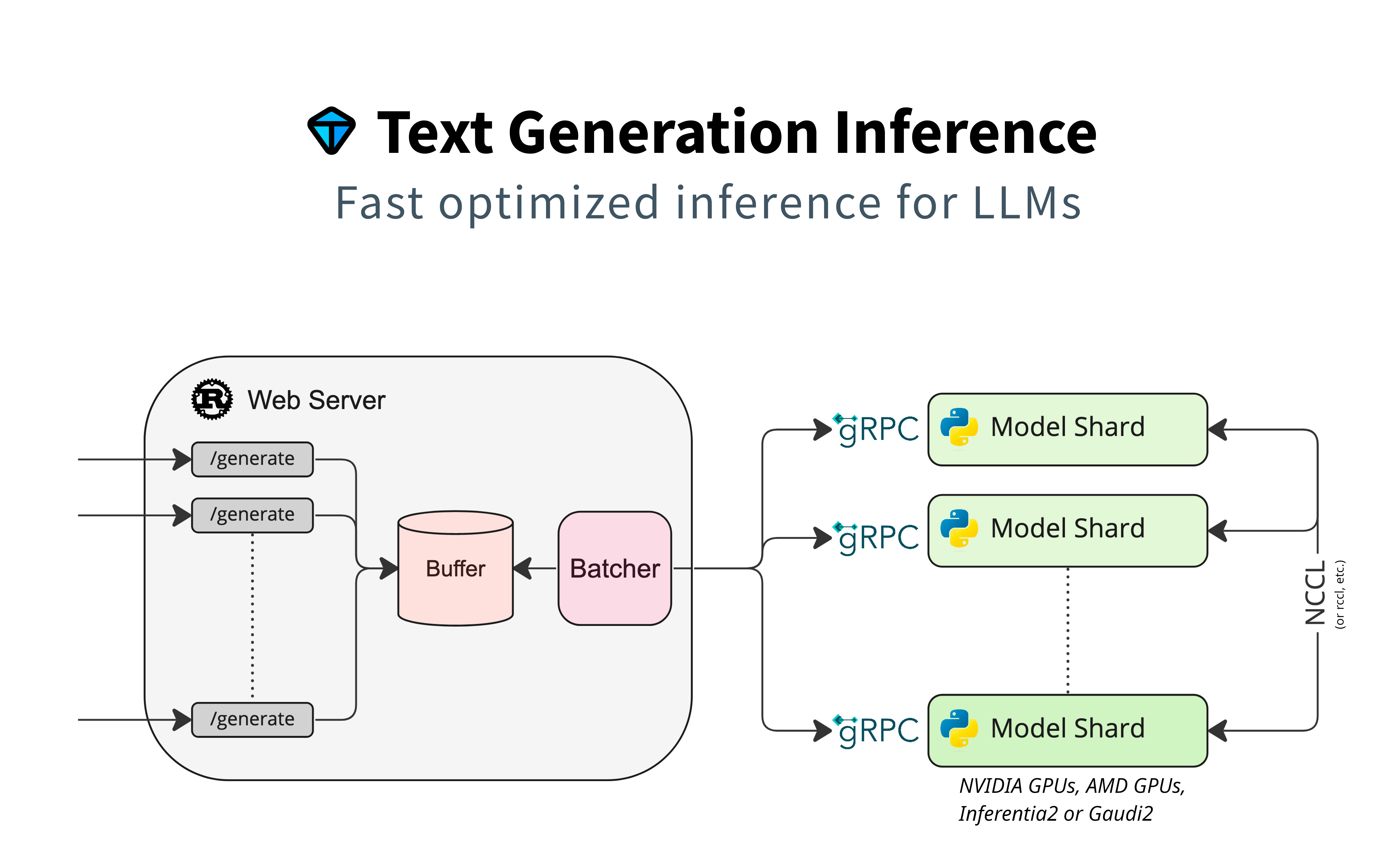
7、本地安装
在本地您也可以选择安装 text-generation-inference。
首先安装 Rust,然后使用至少Python 3.9创建Python虚拟环境。
我的 Rust 安装教程:https://blog.csdn.net/lovechris00/article/details/124808034
这里示例使用 conda 创建环境:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
conda create -n text-generation-inference python=3.11
conda activate text-generation-inference
你可能需要安装 Protoc.
在 Linux 上:
PROTOC_ZIP=protoc-21.12-linux-x86_64.zip
curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP
sudo unzip -o $PROTOC_ZIP -d /usr/local bin/protoc
sudo unzip -o $PROTOC_ZIP -d /usr/local 'include/*'
rm -f $PROTOC_ZIP
在 MacOS 上, 使用 Homebrew:
brew install protobuf
然后运行:
BUILD_EXTENSIONS=True make install # Install repository and HF/transformer fork with CUDA kernels
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2
注意: 在某些计算机上,您可能还需要 OpenSSL库和gcc。
在Linux计算机上,运行下面代码来安装依赖库:
sudo apt-get install libssl-dev gcc -y
三、Optimized architectures
TGI开箱即用,为所有现代模型提供优化模型。
可以在这个列表看到: https://huggingface.co/docs/text-generation-inference/supported_models
其他体系结构尽最大努力支持,使用:
AutoModelForCausalLM.from_pretrained(<model>, device_map="auto")
或
AutoModelForSeq2SeqLM.from_pretrained(<model>, device_map="auto")
四、本地运行
1、运行
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2
2、量化
You can also quantize the weights with bitsandbytes to reduce the VRAM requirement:
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2 --quantize
4bit quantization is available using the NF4 and FP4 data types from bitsandbytes. It can be enabled by providing --quantize bitsandbytes-nf4 or --quantize bitsandbytes-fp4 as a command line argument to text-generation-launcher.
五、开发 & 测试
1、开发
make server-dev
make router-dev
2、测试
# python
make python-server-tests
make python-client-tests
# or both server and client tests
make python-tests
# rust cargo tests
make rust-tests
# integration tests
make integration-tests
2024-03-21



















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











