







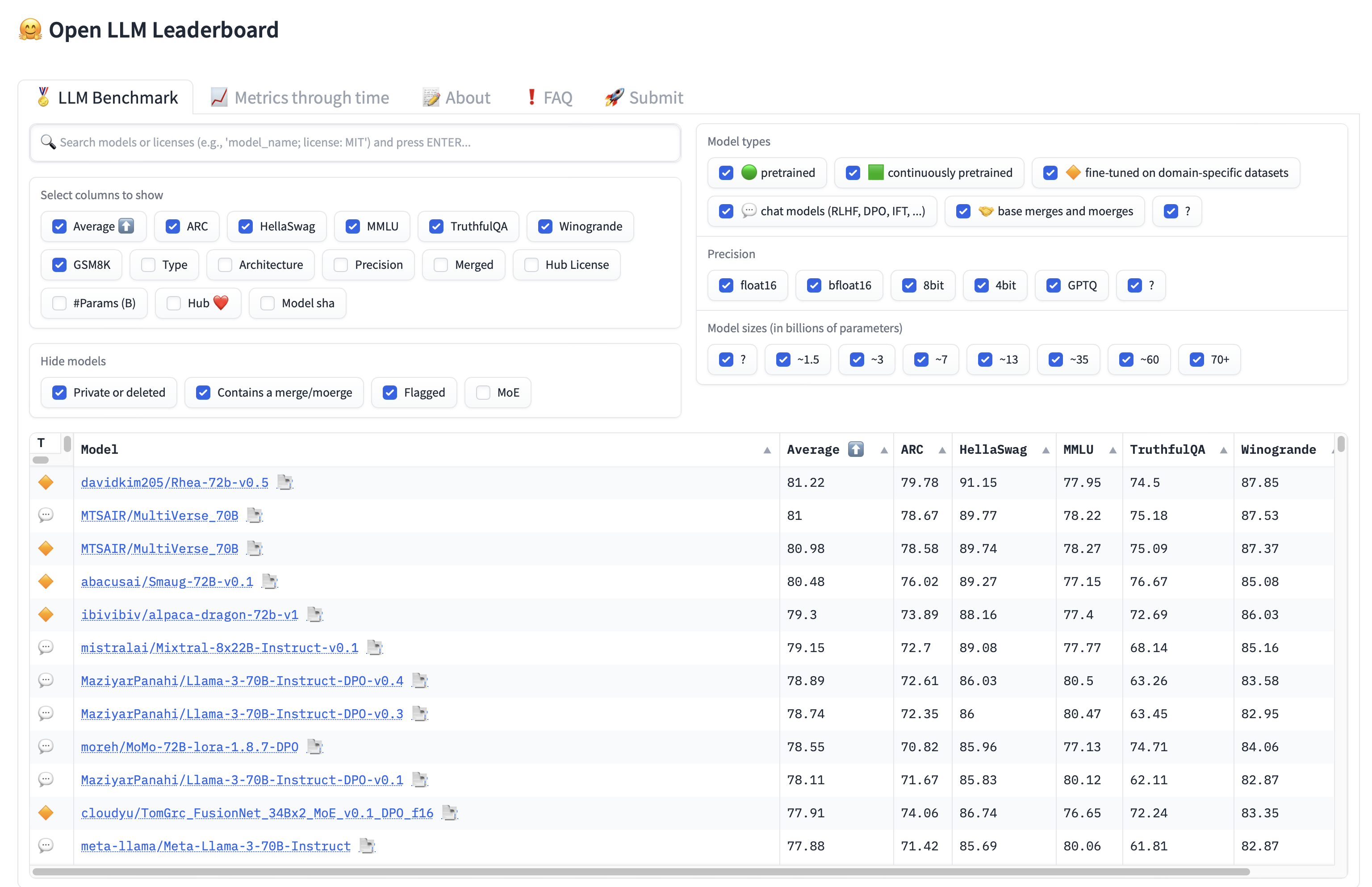
huggingface space 的 Leaderboard 打开都会比较慢,需要耐心等待
HuggingFaceH4 open_llm_leaderboard
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
其他榜单
可参考:https://zhuanlan.zhihu.com/p/660101812
2024-05-04 青年节快乐!
huggingface space 的 Leaderboard 打开都会比较慢,需要耐心等待
HuggingFaceH4 open_llm_leaderboard
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
其他榜单
可参考:https://zhuanlan.zhihu.com/p/660101812
2024-05-04 青年节快乐!
 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























