







Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。通过链接注册并联系客服,可以获得20元代金券(相当于6-7H的免费GPU资源)。欢迎大家体验一下~
1. 前言
特斯拉的FSD带火了自监督学习,而GPT这类大模型也使用了自监督学习的理念。众所周知,监督学习的成本过于高昂,尤其在任务复杂时,典型的就是FSD这样的系统。特斯拉收集的训练数据已经超出4亿公里,这些数据如果没有“自动标注系统”的帮助,根本无法用于训练。即便特斯拉构建了自己的Dojo超级计算机和自动标注、训练软件系统等整套自动化数据闭环体系,仍然无法足够快的完成数据标注和训练,因为标注永远会成为数据闭环的瓶颈,它依赖更大的网络和大量软件的清洗修正等动作,这些动作消耗大量算力、带宽和存储,甚至需要加入少量人工干预,打断循环。看看ChatGPT的训练步骤,第一列是Pre-trainning,这一步占据了99%的训练数据集,第二、三、四列才是肯尼亚团队(contractors)需要干的事情,这几步所产生或标记的数据量只占1%或更少。

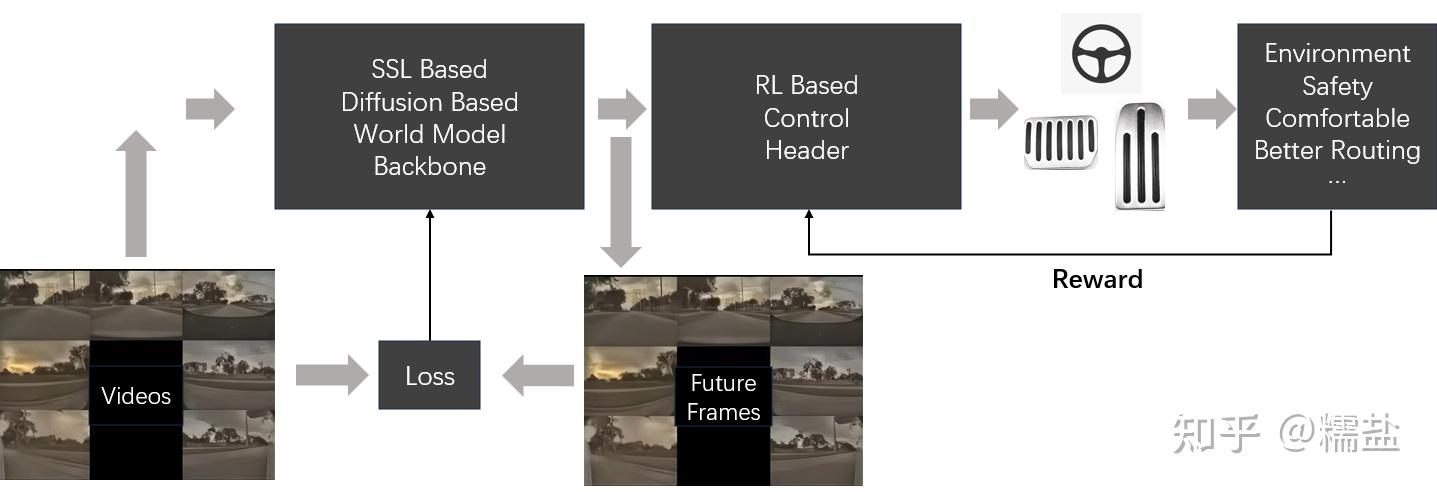
CVPR 2023 特斯拉展示了他们所谓“General World Model”,明确说明这个世界大模型可以预测未来,可以被控制,可以生成不同形式的输出,可用于仿真,可生成不常见的情况。这也间接性代表了自监督学习被作为了整个FSD 12.0版本的骨干网络。经过4亿公里视频的自监督学习训练,这个模型已经超出了以往“大感知”版本的范畴,它可以理解物理世界的运行规律。模型的大概可以被描述成这样
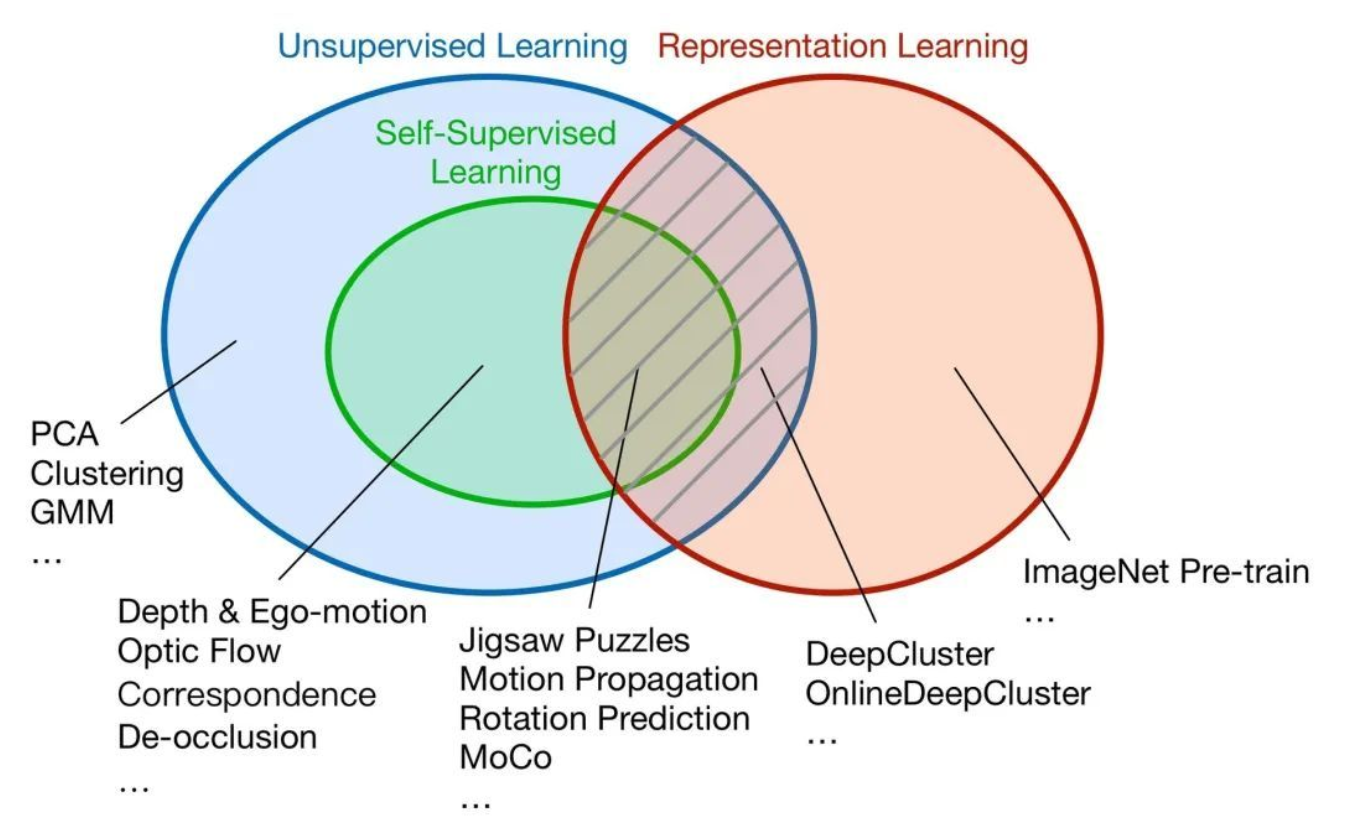
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。
1. 什么是自监督
在基于深度学习的模型中,我们一般先对数据通过主干网络Backbone来进行特征提取,比如用VGG、Resnet、Mobilenet和Inception等,然后再将提取到的Feature maps送入下游的分类、检测或者分割等任务。Backbone之所以有效是因为我们将其事先在Imagenet等数据集上进行了预训练,所以具有很强的特征提取能力。在这里,一个带标签的大数据集(比如Imagenet)是至关重要的,但如果我们在面临一个没有大量标注数据的新领域新任务时,自监督学习就显得非常重要了:
**自监督学习(Self-supervised learning) **是这两年比较热门的一个研究领域,它旨在对于无标签数据 ,通过设计 辅助任务(Proxy tasks) 来挖掘数据自身的表征特性作为监督信息,来提升模型的特征提取能力(PS:这里获取的监督信息不是指自监督学习所面对的原始任务标签,而是构造的辅助任务标签)。注意这里的两个关键词:无标签数据和辅助信息,这是定义自监督学习的两个关键依据。
既然说到了自监督,我们这里也顺便将几种学习类型进行一个统一介绍:
有监督(Supervised): 监督学习是从给定的带标签训练数据集中学习出一个函数(模型参数),在输入新的测试数据时,可以根据这个函数预测结果;
无监督(Unsupervisedg): 无监督学习是从无标签数据中分析数据本身的规律性等解析特征。无监督学习算法分为两大类:基于概率密度函数估计的方法和基于样本间相似性度量的方法;
半监督习(Semi-supervised): 半监督介于监督学习和无监督之间,即训练集中只有一部分数据有标签,需要通过伪标签生成等方式完成模型训练;
弱监督(Weakly-supervised): 弱监督是指训练数据只有不确切或者不完全的标签信息,比如在目标检测任务中,训练数据只有分类的类别标签,没有包含Bounding box坐标信息。
1.1 自监督与有监督区别
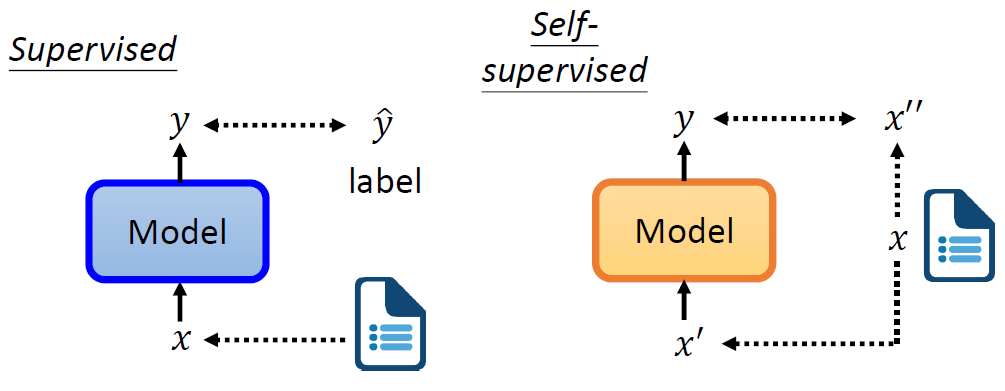
如下图所示,我们之前在做 Supervised Learning的时候,如何让model输出我们想要的 y y y呢?你得要有label的资料。假设今天要做情感分析,让机器看一段文字,输出对应的情感是正面的还是负面的。那你要有一大堆文章和对应的label,才能够训练model。
那 Self-Supervised 就是在没有label的情况下自己想办法监督自己。还是同样的一堆资料 x x x,我们现在把它分成2部分: x ′ x' x′和 x ′ ′ x'' x′′ 。然后把 x ′ x' x′输入到模型里面,让它输出 y y y ,然后我们让 y y y 与 x ′ ′ x'' x′′ 越接近越好,这个就是 Self-Supervised Learning。换言之在 Self-Supervised Learning里面输入的一部分作为了监督信号,一部分仍作为输入。
通过学习对两个事物的相似或不相似进行编码来构建表征,即通过构建正负样本,然后度量正负样本的距离来实现自监督学习。核心思想样本和正样本之间的相似度远远大于样本和负样本之间的相似度,类似Triplet模式。
根据人为设计的不同pretext预训练方法,自监督学习可以分为以下三种:
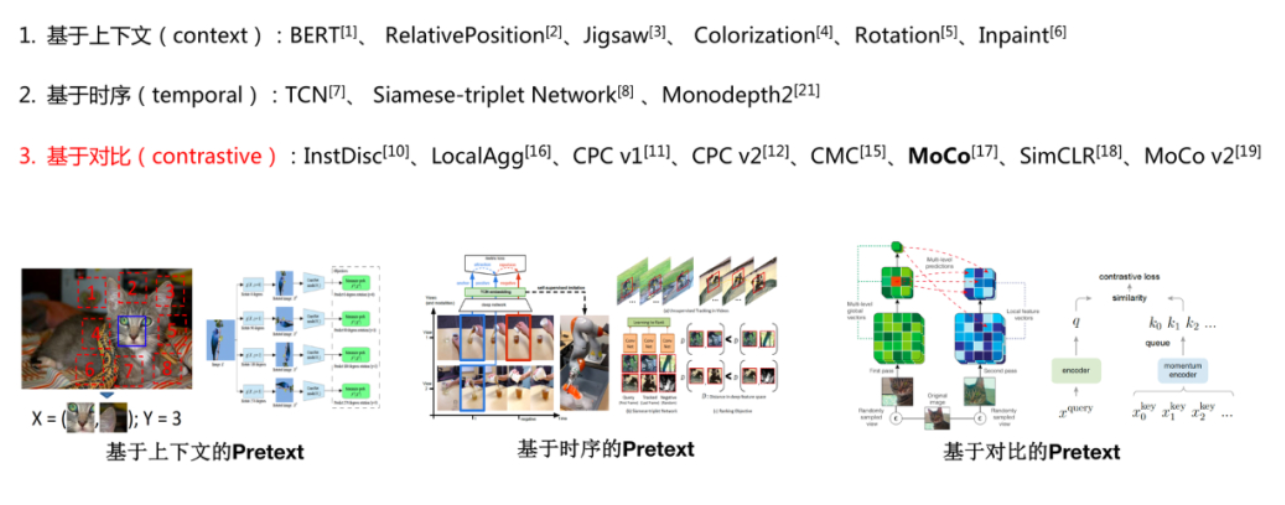
1.2 基于上下文(Context Based)
1.2.1 NLP的基于上下文预训练
句子的语序有很强的规律性,所以自然语言处理任务中,语序信息是用来设计辅助任务的关键。对于NLP而言,主要是通过 Pretrain-Fintune 的模式。 我们首先回顾下监督学习中的 Pretrain - Finetune 流程:我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。而自监督的 Pretrain - Finetune 流程:首先从大量的无标签数据中通过 pretext 来训练网络,得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。这也是大模型微调的操作。

a、单词预测(Word prediction)----这类其实GT就是原对话,从而来计算loss
最常见的通过随机删去训练集句子中的单词来构造辅助任务训练集和标签,来训练网络预测被删去的单词,以提升模型对于语序特征的提取能力(BERT)

1.2.2 Image的基于上下文
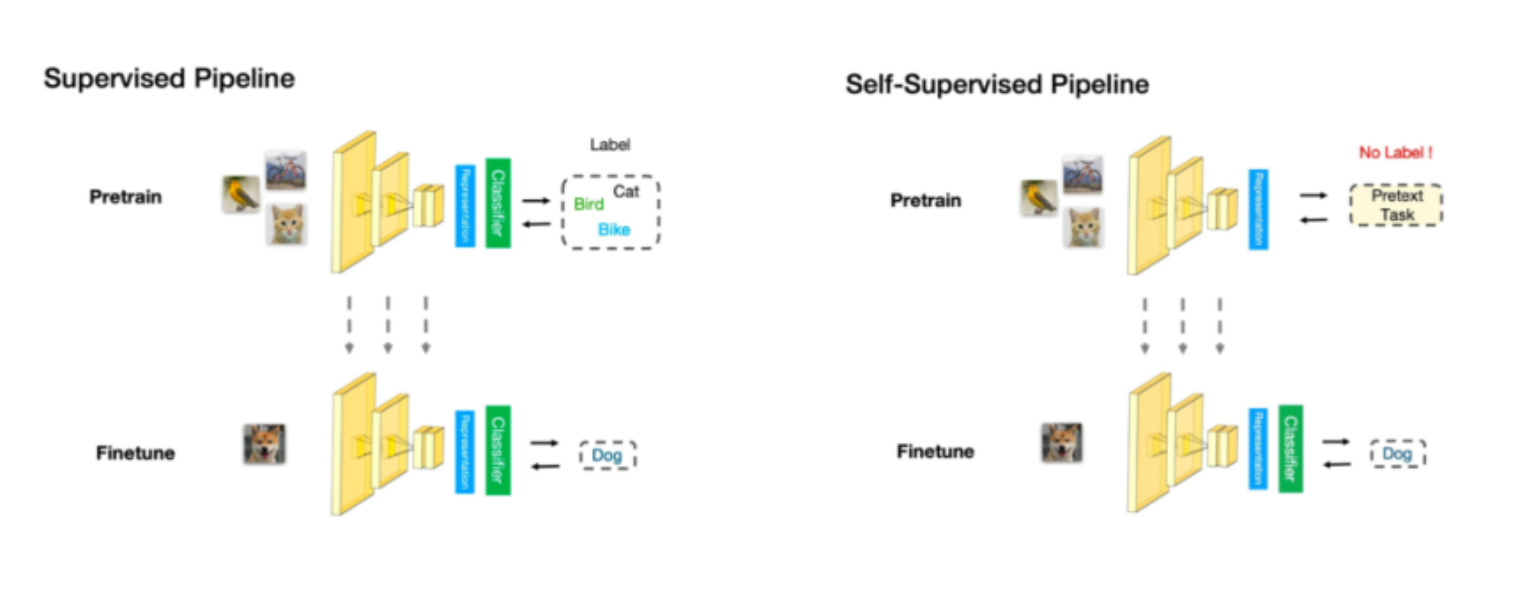
a) 图像重组(Jigsaw Puzzles)----这类其实GT就是原图像,从而来计算loss
在图像中,研究人员通过一种名为 Jigsaw(拼图)[7] 的方式来构造辅助任务。我们可以将一张图分成 9 个部分,然后通过预测这几个部分的相对位置来产生损失。比如我们输入这张图中的小猫的眼睛和右耳朵,期待让模型学习到猫的右耳朵是在脸部的右上方的,如果模型能很好的完成这个任务,那么我们就可以认为模型学习到的表征是具有语义信息的。
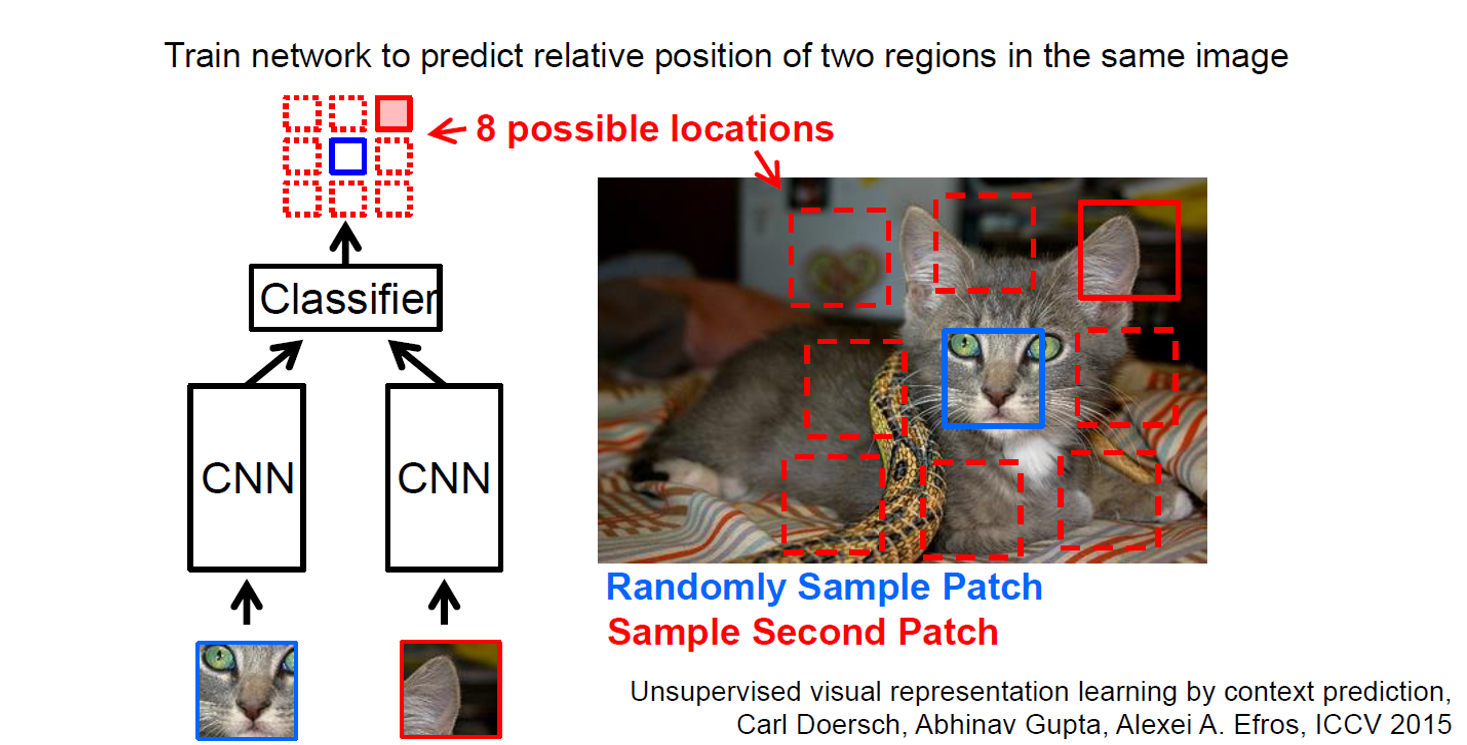
后续的工作[8]人们又拓展了这种拼图的方式,设计了更加复杂的,或者说更难的任务。首先我们依然将图片分为 9 块,我们预先定义好 64 种排序方式。模型输入任意一种被打乱的序列,期待能够学习到这种序列的顺序属于哪个类,和上个工作相比,这个模型需要学习到更多的相对位置信息。这个工作带来的启发就是使用更强的监督信息,或者说辅助任务越难,最后的性能越好。
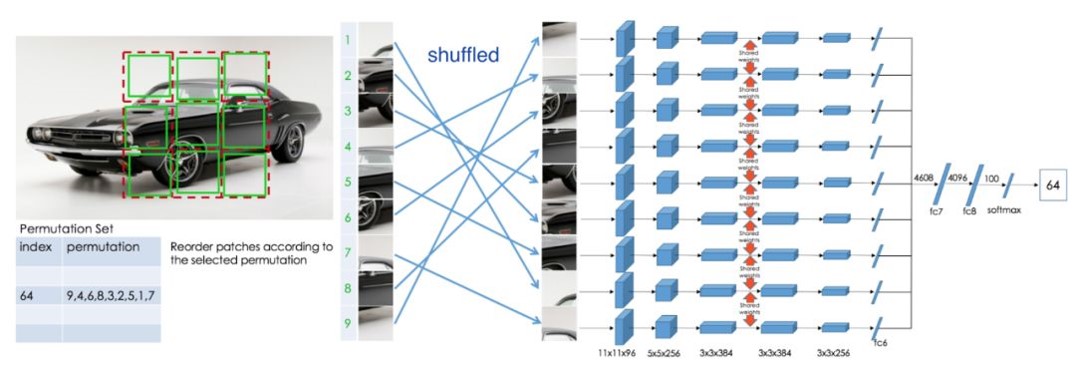
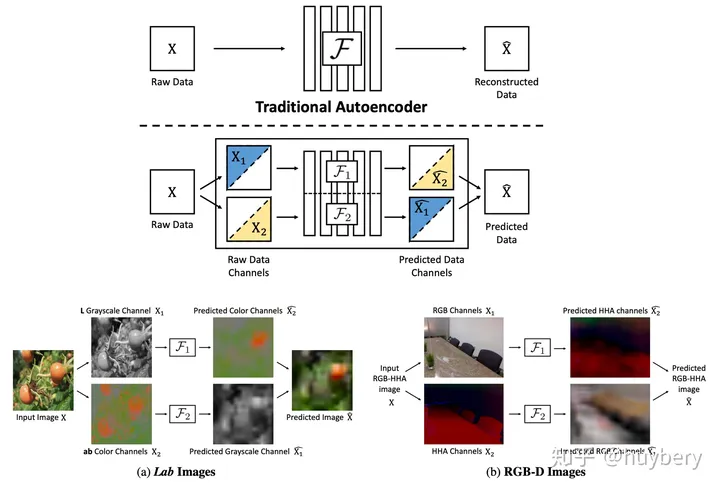
b) 图像渲染(Image Colorization)
这里将原来数据集中的RGB图像进行灰度化处理,然后通过图像色彩恢复任务来训练网络。通过图片的颜色信息[11],比如给模型输入图像的灰度图,来预测图片的色彩。只有模型可以理解图片中的语义信息才能得知哪些部分应该上怎样的颜色,比如天空是蓝色的,草地是绿色的,只有模型从海量的数据中学习到了这些语义概念,才能得知物体的具体颜色信息。同时这个模型在训练结束后就可以做这种图片上色的任务。
预测颜色的生成模型带给了人们新的启发,其实这种灰度图和 ab 域的信息我们可以当做是一张图片的解耦表达,所以只要是解耦的特征,我们都可以通过这种方式互相监督的学习表征,著名的 Split-Brain Autoencoders [12] 就在做这样一件事情。对于原始数据,首先分成两部分,然后通过一部分的信息来预测另一部分,最后再合成完成的数据。
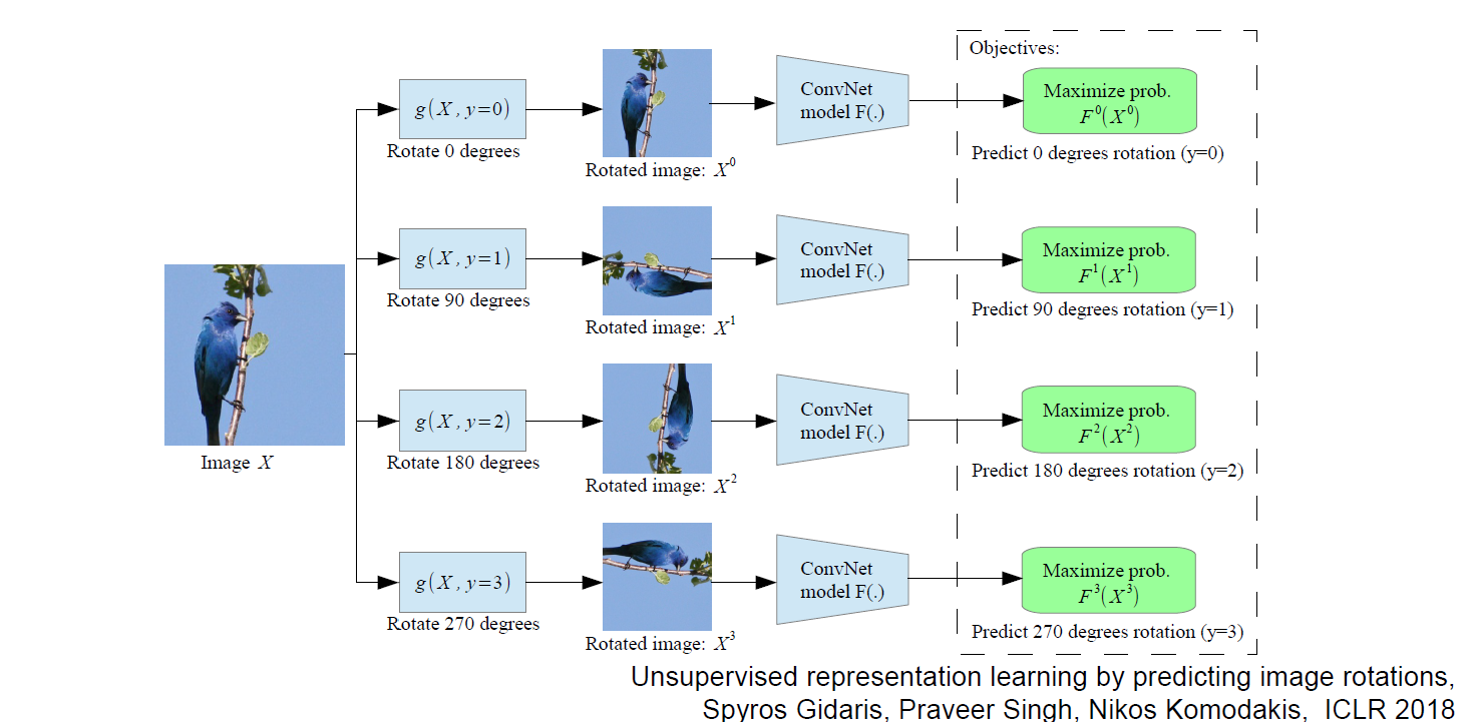
c) 图像旋转角度预测(Image Colorization)
将训练集中的图像进行随机旋转,然后通过旋转角回归任务来训练网络。ICLR 2018 [13]的工作是给定一张输入的图片,我们对其进行不同角度的旋转,模型的目的是预测该图片的旋转角度。这种朴素的想法最后带来的增益竟然是非常巨大的,所以数据增强对于自监督学习也是非常有益处的,我个人的想法是数据增强不仅带来了更多的数据,还增加了预训练模型的鲁棒性。
d、图像修复(Image In-painting)
最后一种是抠图[9]。想法其实也很简单粗暴,就是我们随机的将图片中的一部分删掉,然后利用剩余的部分来预测扣掉的部分,只有模型真正读懂了这张图所代表的含义,才能有效的进行补全。这个工作表明自监督学习任务不仅仅可以做表征学习,还能同时完成一些神奇的任务。
e、多任务学习(Multi-Tasks)
结合上述的几种辅助任务一起对模型进行训练
论文一:《Rethinking Data Augmentation: Self-Supervision and Self-Distillation》
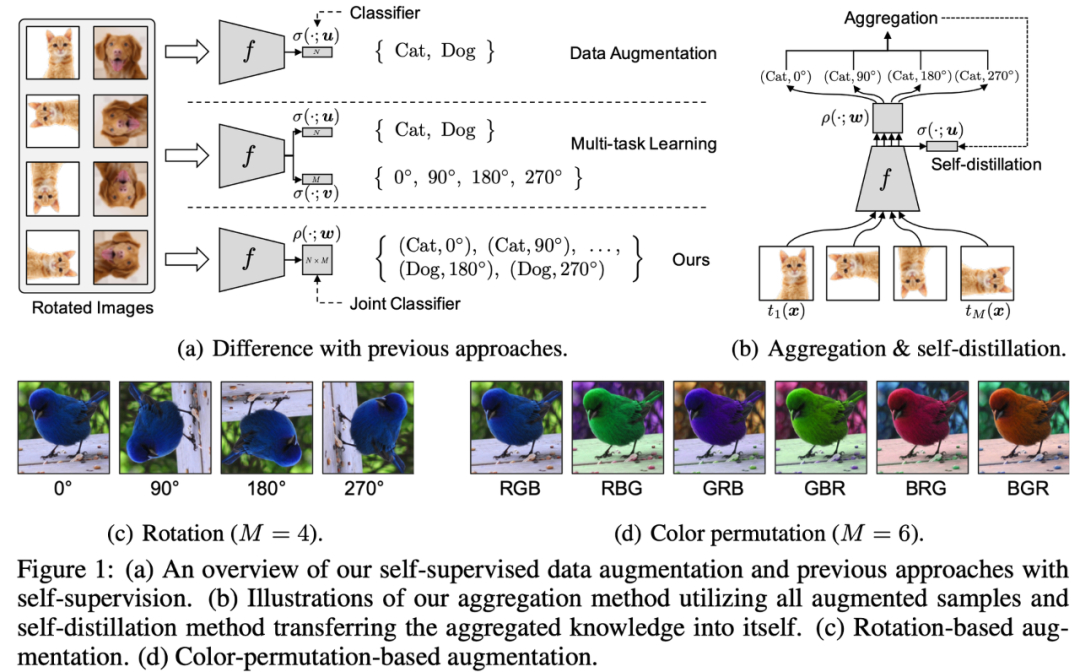
Data Augmentation相关的方法会对通过对原始图片进行一些变换(颜色、旋转、裁切等)来扩充原始训练集合,提高模型泛化能力;
Multi-task learning将正常分类任务和self-supervised learning的任务(比如旋转预测)放到一起进行学习。
作者指出通过data augmentation或者multi-task learning等方法的学习强制特征具有一定的不变性,会使得学习更加困难,有可能带来性能降低。
因此,作者提出将分类任务的类别和self-supervised learning的类别组合成更多类别(例如 (Cat, 0),(Cat,90)等),用一个损失函数进行学习。
论文二:《S4L: Self-Supervised Semi-Supervised Learning》
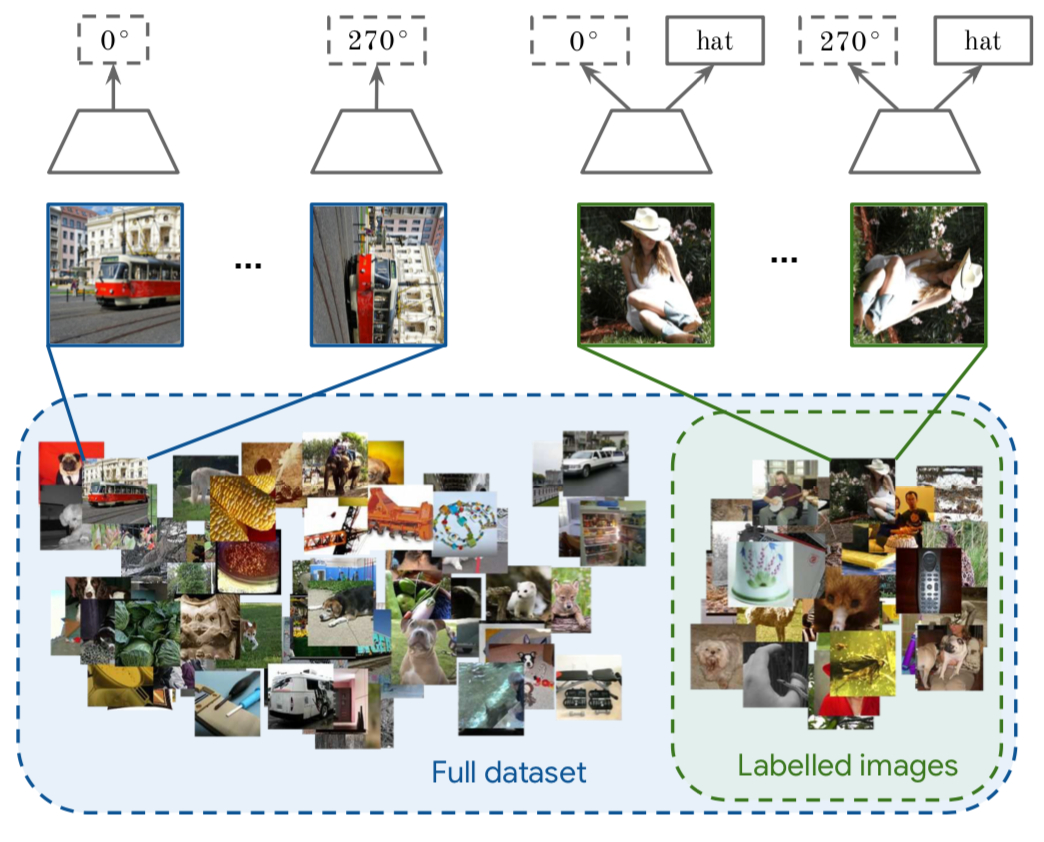
自监督和半监督学习(大量数据没有标签,少量数据有标签)也可以进行结合,对于无标记的数据进行自监督学习(旋转预测),和对于有标记数据,在进行自监督学习的同时利用联合训练的想法进行有监督学习。通过对 imagenet 的半监督划分,利用 10% 或者 1% 的数据进行实验,最后分析了一些超参数对于最终性能的影响。
对于标记数据来说,模型会同时预测旋转角度和标签,对于无标签数据来说,只会预测其旋转角度,预测旋转角度”可以替换成任何其它无监督task(作者提出了两个算法,一个是 S4L-Rotation,即无监督损失是旋转预测任务;另一个是S4L-Exemplar,即无监督损失是基于图像变换(裁切、镜像、颜色变换等)的triplet损失)
总的来说,需要借助于无监督学习,为无标注数据创建一个pretext task,这个pretext task能够使得模型利用大量无标注学习一个好的feature representation
2.2 基于时序(Temporal Based)
之前介绍的方法大多是基于样本自身的信息,比如旋转、色彩、裁剪等。而样本间其实也是具有很多约束关系的,比如视频相邻帧的相似性、物体多个视觉的视频帧。
2.2.1 NLP基于时序----这类其实GT就是原对话,从而来计算loss
b、句子序列预测(Sentence sequence prediction)
通过随机打乱每段话中的句子顺序来构造辅助任务训练集,来训练网络对句子进行正确的排序,标签为原来正确的句子顺序。
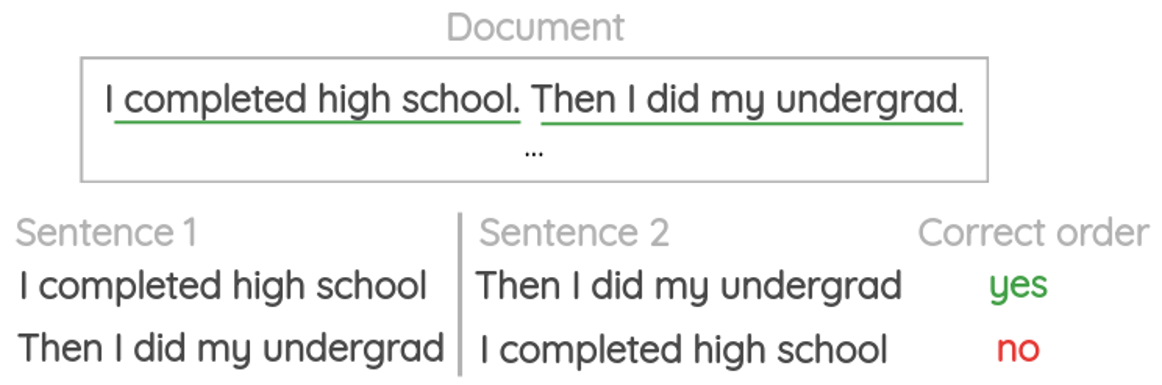
c、词序列预测(Word sequence prediction)
打乱正常语句中的单词顺序,让模型学习组句,标签信息为原来正确的词序。
image 基于时序----这类其实GT就是原视频的顺序,从而来计算loss
之前介绍的方法大多是基于样本自身的信息,比如旋转、色彩、裁剪等。而样本间其实也是具有很多约束关系的,这里我们来介绍利用时序约束来进行自监督学习的方法。最能体现时序的数据类型就是视频了(video)。
a) 基于视频中目标的相似性
第一种思想是基于帧的相似性[17],对于视频中的每一帧,其实存在着特征相似的概念,简单来说我们可以认为视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。
论文三:《Time-Contrastive Networks: Self-Supervised Learning from Video》
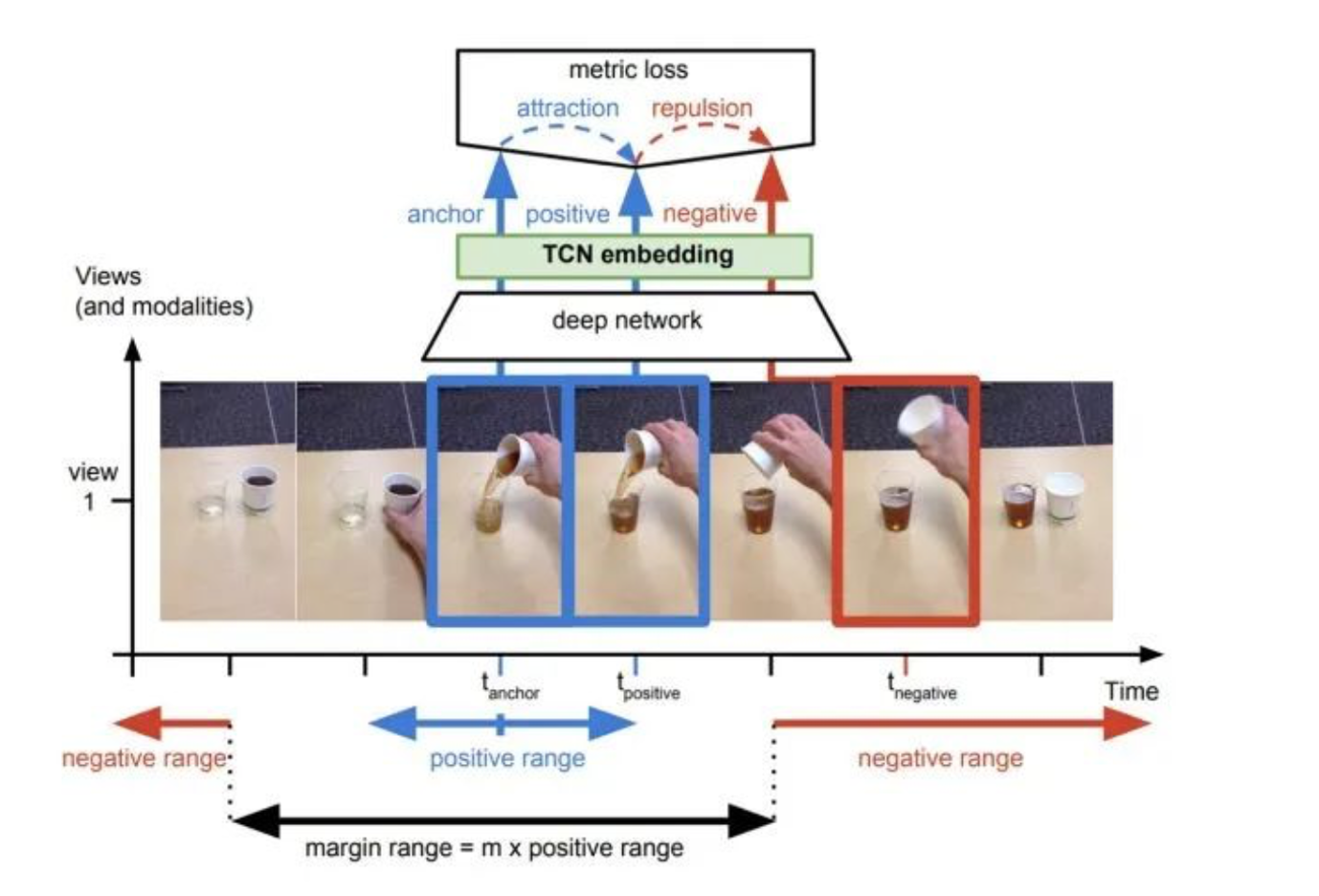
b) 基于无监督目标跟踪
对于同一个物体的拍摄是可能存在多个视角(multi-view),对于多个视角中的同一帧,可以认为特征是相似的,对于不同帧可以认为是不相似的。然后让网络学习同一目标和不同目标在不同帧中的相似性判别来提升特征提取能力
论文四:《Unsupervised Learning of Visual Representations Using Videos》
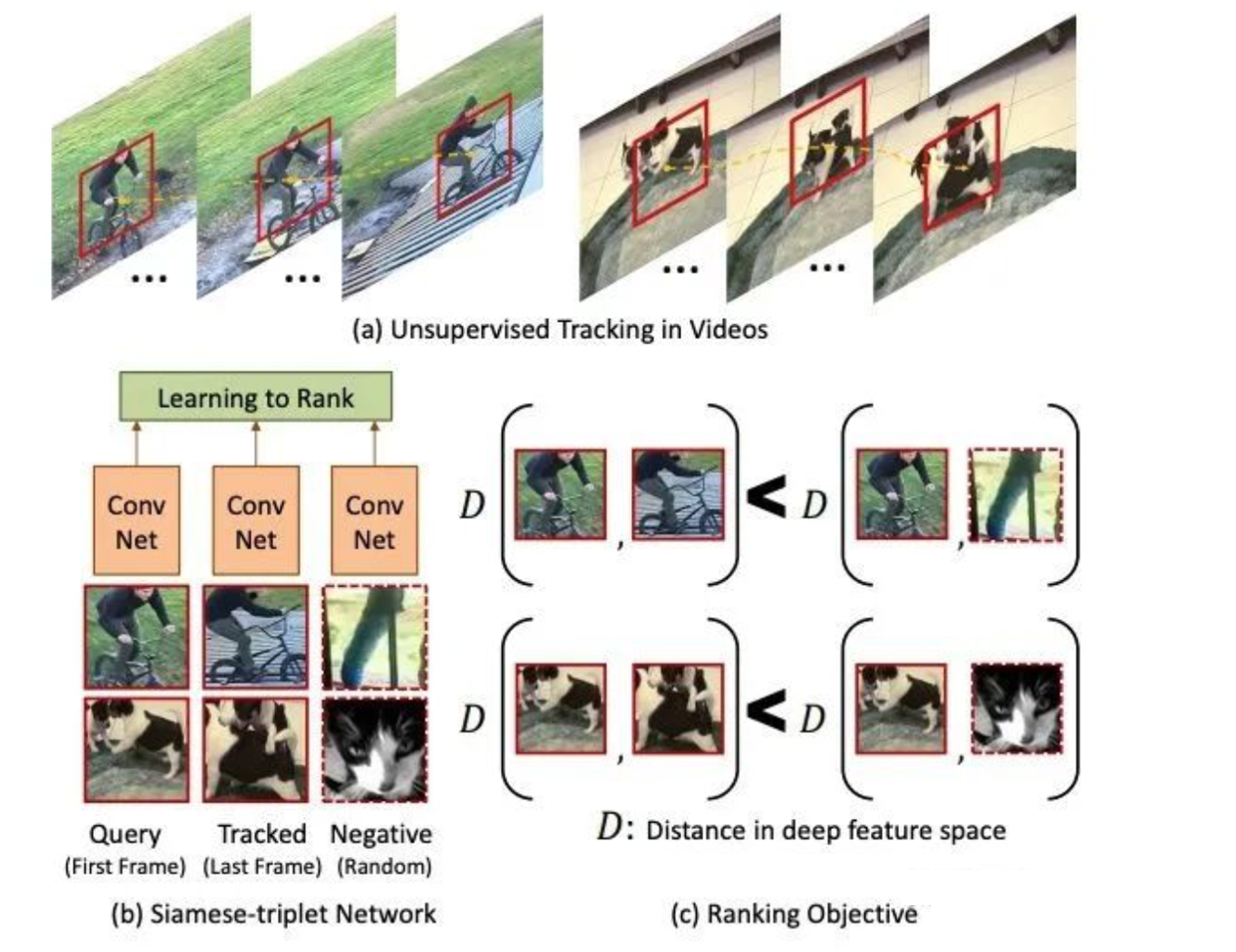
c) 基于视频帧的序列信息
这个跟自然语言处理中的语序预测很相似,我们通过随机打乱训练集中视频帧的顺序,来训练网络让其对正确视频时序进行预测。基于顺序约束的方法,可以从视频中采样出正确的视频序列和不正确的视频序列,构造成正负样本对然后进行训练。简而言之,就是设计一个模型,来判断当前的视频序列是否是正确的顺序。
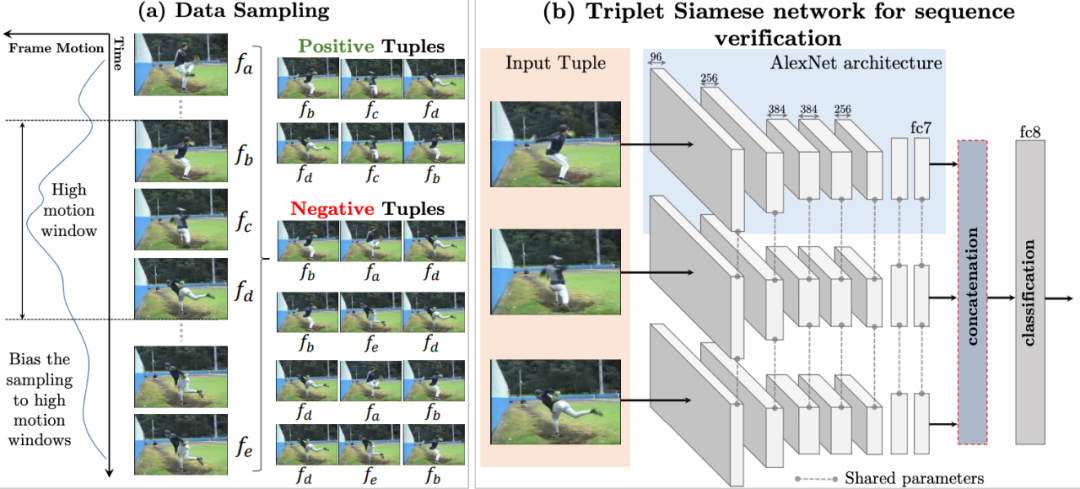
论文五:《Shuffle and learn: unsupervised learning using temporal order verification》

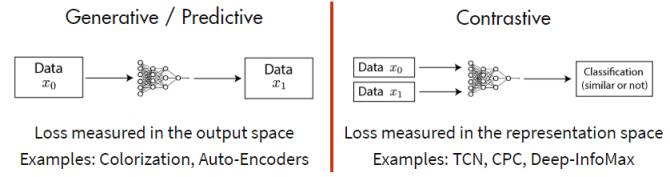
2.3 基于对比(Contrastive Based)----这类其实GT就是两个事物是否相似,从而来计算loss
第三类自监督学习的方法是基于对比约束,它通过学习对两个事物的相似或不相似进行编码来构建表征,这类方法的性能目前来说是非常强的,从最近的热度就可以看出,很多大牛的精力都放在这个方向上面。其实我们第二部分所介绍的基于时序的方法已经涉及到了这种基于对比的约束,通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现自监督学习。核心思想样本和正样本之间的相似度远远大于样本和负样本之间的相似度:
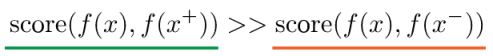
这里的 x x x 通常也称为 「anchor」数据,为了优化 anchor 数据和其正负样本的关系,我们可以使用点积的方式构造距离函数,然后构造一个 softmax 分类器,以正确分类正样本和负样本。这应该鼓励相似性度量函数(点积)将较大的值分配给正例,将较小的值分配给负例:
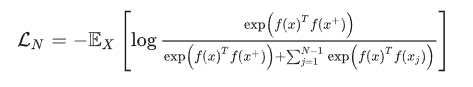
论文六:《Learning deep representations by mutual information estimation and maximization》
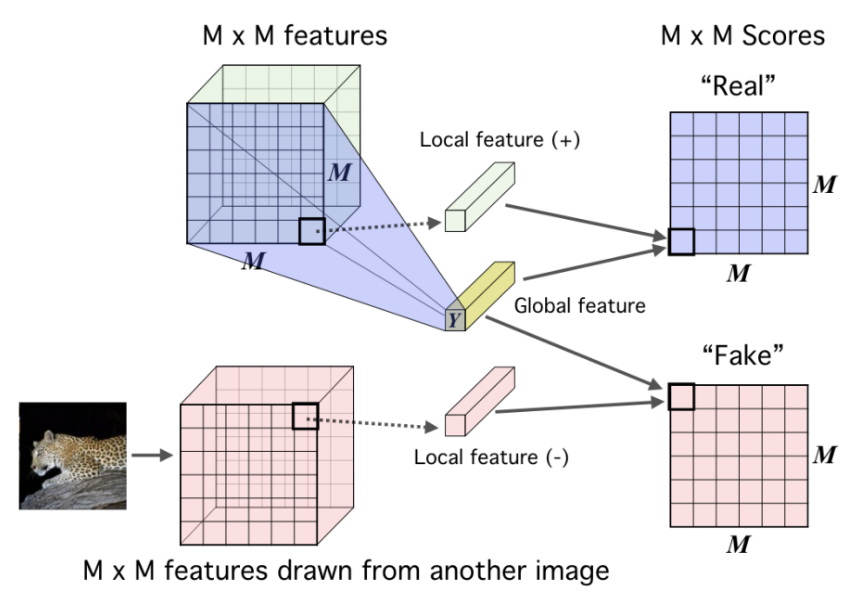
Deep InfoMax 通过利用图像中的局部结构来学习图像表示,对比任务是对一对图像中的全局特征和局部特征进行分类。
全局特征是CNN的最终输出,局部特征是编码器中的中间层的输出。每个局部特征图都有一个有限的感受野。
对于一个 anchor image x x x, f ( x ) f(x) f(x)是来自一幅图像的全局特征,正样本 f ( x + ) f(x+) f(x+)是相同图像的局部特征,负样本 f ( x − ) f(x−) f(x−)是不同图像的局部特征。
本文探讨的简单思想是训练一个表示学习函数,即编码器,以最大化其输入和输出之间的互信息(MI)。作者以一种类似于对抗自动编码器的方式,将MI最大化和先验匹配结合起来,根据期望的统计特性约束表示。
为了得到一个更适合分类的表示,作者将图像的高层表示与局部patch之间的平均MI值最大化。
论文七:《Representation Learning with Contrastive Predictive Coding》
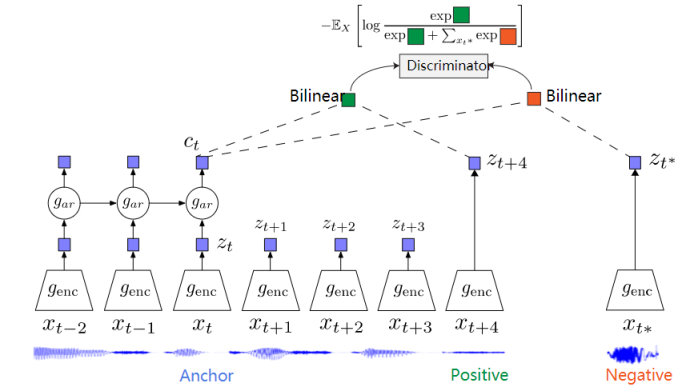
CPC是一个基于对比约束的自监督框架,可以适用于文本、语音、视频、图像等任何形式数据的对比方法(图像可以看作为由像素或者图像块组成的序列)。
CPC通过对多个时间点共享的信息进行编码来学习特征表达,同时丢弃局部信息。这些特征被称为“慢特征”:随时间不会快速变化的特征。比如说:视频中讲话者的身份,视频中的活动,图像中的对象等。
CPC 主要是利用自回归的想法,对相隔多个时间步长的数据点之间共享的信息进行编码来学习表示,这个表示 c t c_t ct 可以代表融合了过去的信息,而正样本就是这段序列 t t t 时刻后的输入,负样本是从其他序列中随机采样出的样本。CPC的主要思想就是基于过去的信息预测的未来数据,通过采样的方式进行训练。
论文八:Moco《Momentum Contrast for Unsupervised Visual Representation Learning》
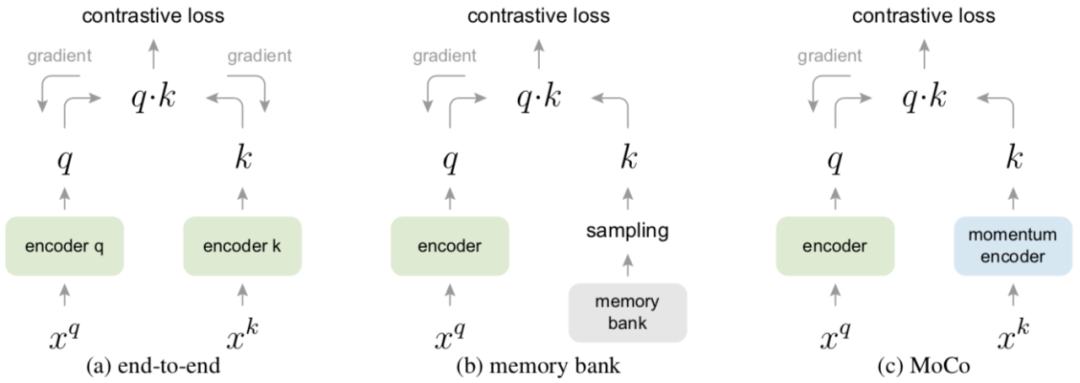
基于对比的自监督学习其实就是训练一个编码器然后在一个大的字典里确保和对应的key是相似的,和其它的是不相似的。
传统上字典的大小就是batch-size,由于算力的影响不能设置过大,因此很难应用大量的负样本。因此效率较低。
本文采用队列来存储这个字典,在训练过程中,每一个新batch完成编码后进入队列,最老的那个batch的key出队列,字典的大小与batchsize实现分离,这样可用的字典大小就可以远远大于batchsize,负样本的数目就会大大扩增,效率得到大幅提升。
a) 传统方法-端到端,这种方式query和key用两个encoder,然后两个参数是都进行更新的,但这种方式你的字典大小就是mini-batch的大小。
b) 采用一个较大的memery bank存储较大的字典(存储所有的样本),但是每次进行query之后才会对memory进行更新,所以每次采样得到的query可能是很多步骤之前编码的的向量,这样就丢失了一致性。
c) 使用queue,每次query之后都删除最早的batch的样本,然后将最新的batch更新入队,这样就巧妙的缓解了memory-bank一致性的问题。同时利用队列可以保存远大于batchsize的样本,这样也解决了end-to-end的batch-size的耦合问题。
论文九:SimCLR《A Simple Framework for Contrastive Learning of Visual Representations》
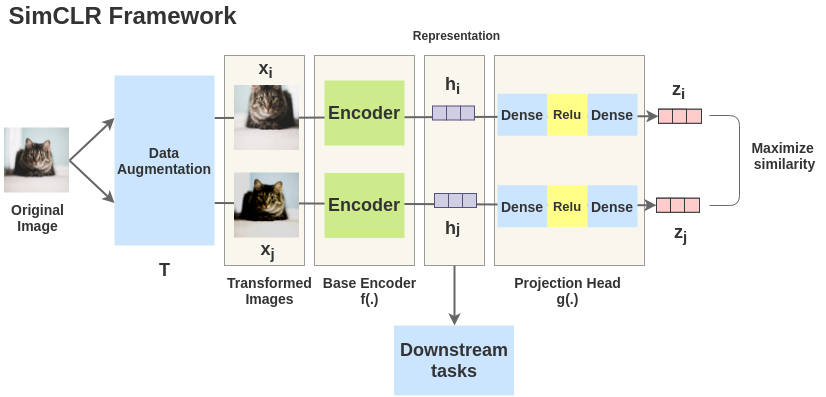
取一幅图像对其进行随机变换,得到一对增广图像 x i x_i xi和 x j x_j xj。该对中的每个图像都通过编码器以获得图像的表示。然后用一个非线性全连通层来获得图像表示 z z z,其任务是最大化相同图像的 z i z_i zi和 z j z_j zj两种表征之间的相似性。
随机数据增强模块:随机剪裁之后Resize到同一尺寸,接着是随机颜色扰动,随机高斯模糊。随机剪裁和颜色扰动的组合对获得好性能至关重要。
用于从增强后的数据样本中提取表征向量的神经网络基础编码器。该框架能够无限制的适用不同的网络框架。作者们采用简单通用的ResNet。
神经网络projection head g ( ) g() g(),用来将表征映射到对比损失应用的空间。
对比损失函数,用于对比预测任务。给定一个包含正样本对的数据集,对比预测任务目标是识别出正样本对。
3. 自动驾驶自监督端到端
不要忘了我们本文的核心-------自动驾驶自监督端到端。这也是要通过类似World Model这类方法来实现端到端的自动驾驶。自动驾驶领域中的端到端驾驶策略学习将原始传感器数据(图片,车身信号,点云等)作为输入,直接预测控制信号或规划路线。由于驾驶环境的复杂性和不确定性以及传感器数据中的大量无关信息,对于端到端的驾驶策略模型,从头开始学习是很困难的,它通常需要大量的标注数据或环境交互反馈才能达到令人满意的性能。
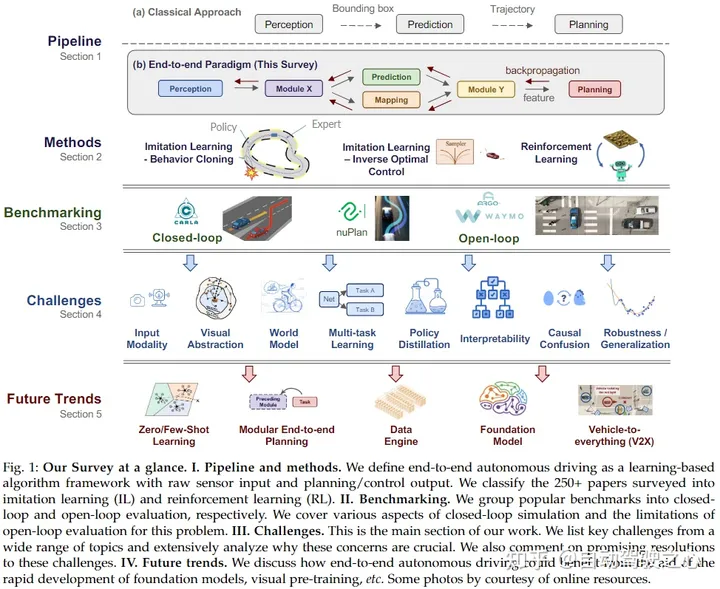
一个典型的端到端自动驾驶系统如图所示:
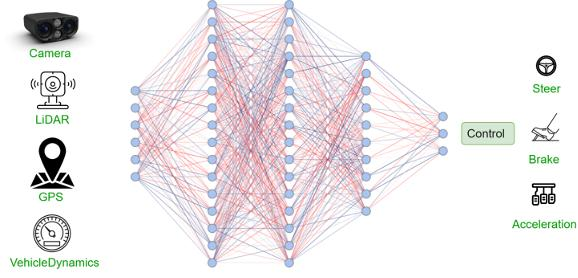
输入:大部分自动驾驶汽车都装载了相机、Lidar、毫米波雷达等各类传感器,采集这些传感器的数据,输入深度学习系统即可。
输出: 可以直接输出转向角、油门、刹车等控制信号,也可以先输出轨迹再结合不同的车辆动力学模型,将轨迹转为转向角、油门、刹车等控制信号。
可见,端到端自动驾驶系统就像人类的大脑,通过眼睛、耳朵等传感器接受信息,经过大脑处理后,下达指令给手脚执行命令,但是这种简单也隐藏了巨大的风险,例如可解释性很差,无法像传统自动驾驶任务一样将中间结果拿出来进行分析;对数据的要求非常高,需要高质量的、分布多样的、海量的训练数据,否则AI就会实现垃圾进垃圾出。
传统的自动驾驶是分任务的,必然是多个模块。端到端自动驾驶可以用单模块来实现,当然也可以用多模块来实现,其区别在于是否端到端训练。分任务系统是每个任务独立训练、独立优化、独立测评的,而端到端系统是把所有模块看成一个整体进行端到端训练、端到端测评的。
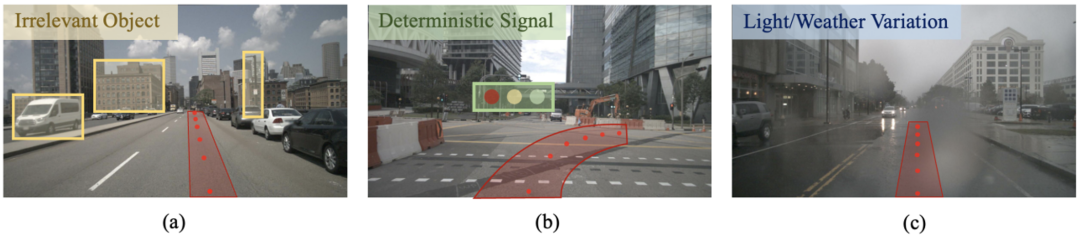
自然环境中存在着许多不需要关注的信息如建筑物、天气变化以及光照变化等,于驾驶任务而言,下一步往哪里行驶,信号灯是否允许通行,这些信息才是真正需要关注的。


















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











