






作者 | wnwn 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/27983835711
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端』技术交流群
本文只做学术分享,如有侵权,联系删文
背景
自动驾驶感知最近似乎进入瓶颈期,接近一年的时间Nuscenes障碍物检测榜单都不再有更新,而大模型如火如荼的发展把数据驱动的AI发展逻辑也代入了自动驾驶领域。这篇博客主要是想把最近关注到的一些自动驾驶端到端的论文整理一下,捋出一些有价值的思路和想法。
参考VAD的论文思路,我会把端到端整体划分为3部分:
感知端到端
预测端到端
规划端到端-端到端整体架构
感知端到端
感知端到端这一块主要涉及到多传感器融合和时序融合。我想从障碍物和车道线这2个领域分别调一篇比较有代表性的论文聊一聊。
障碍物:Sparse4D v3: Advancing End-to-End 3D Detection and Tracking
nuscensce视觉障碍物检测SOTA方案,整体架构延续DETR一派,新增维护memory队列,其中巧思很多,主要有一下几点:
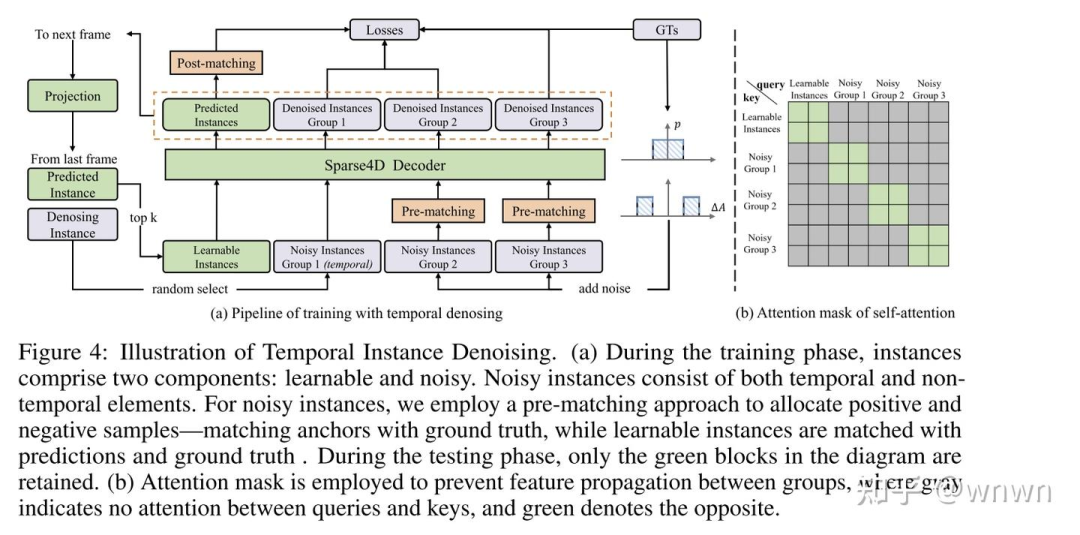
可学习query中新增队列实例做初始化(注意速度,是否拿来做障碍物的位置编码残差项?)
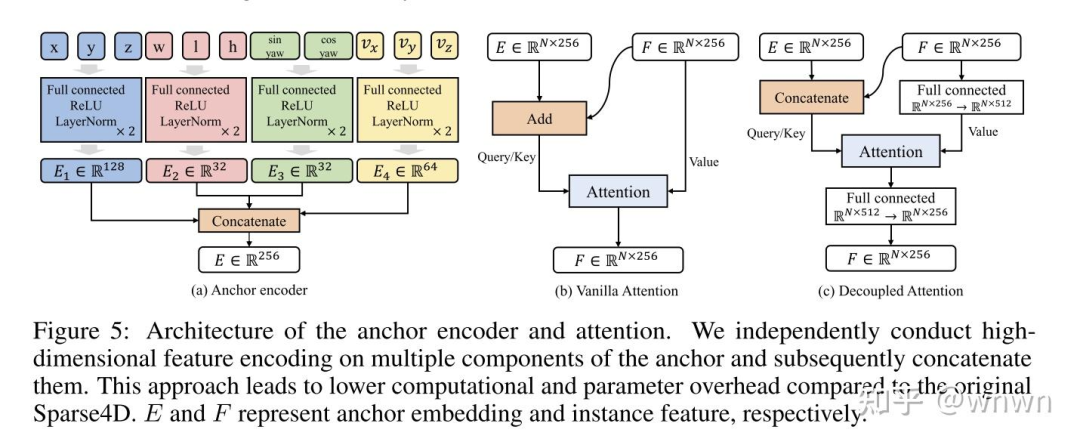
按属性拆分的attention

在模型中做实例信息整合,而无需显式匹配,在记忆队列里维护实例id
车道线:MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping
选择这篇主要是思路和效果都不错,放个效果图大家感受一下~
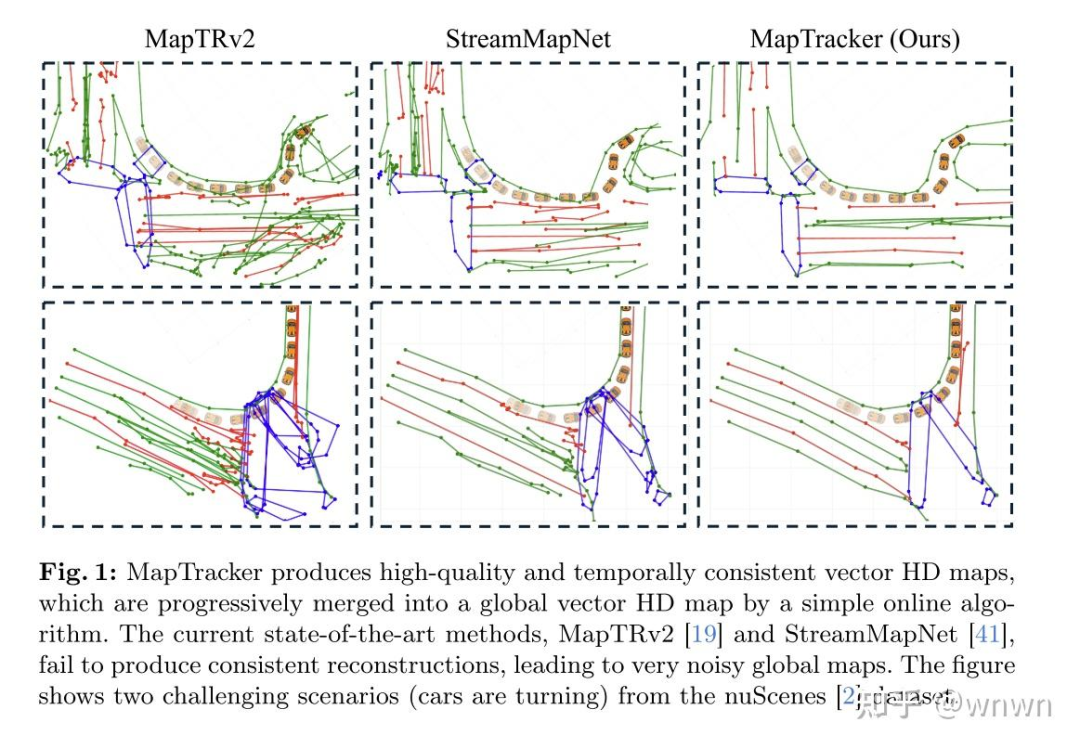
这篇文章比较吸引我的一个点在架构上
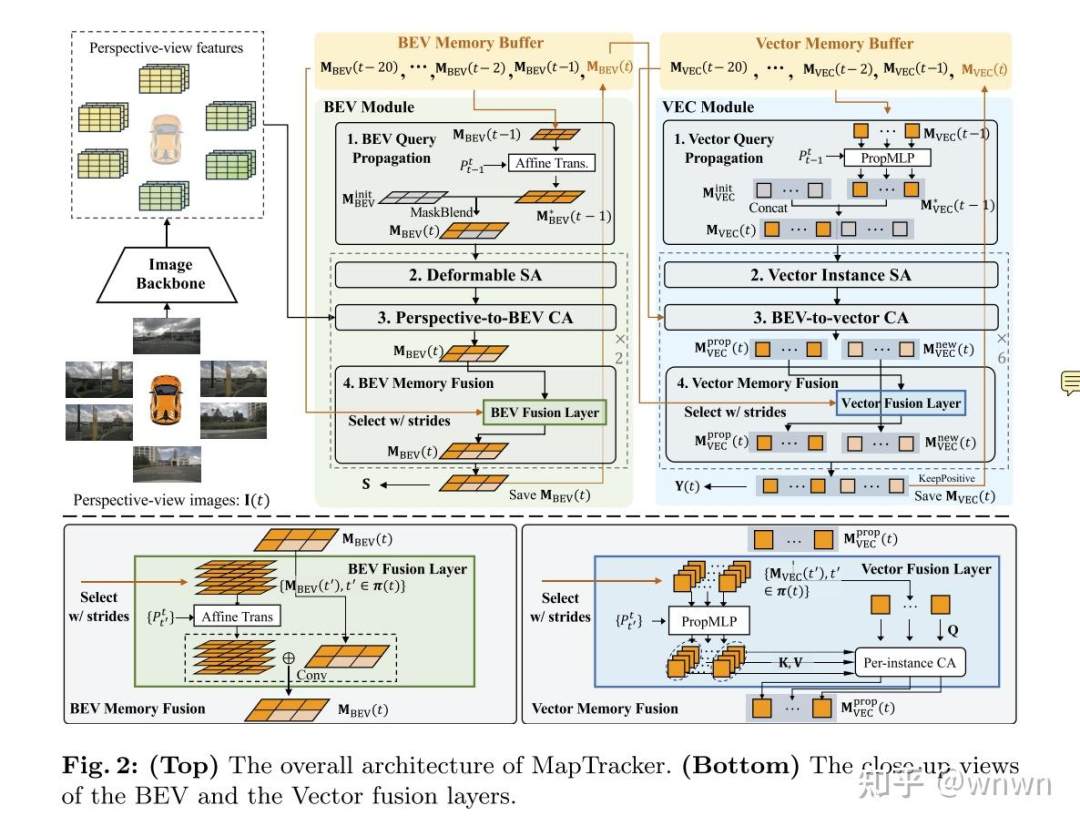
这篇文章和上面的Sparse4D一样是维护了2个记忆队列,可以把这些记忆队列理解为车道线的隐藏状态,这个状态在时序迭代中是越来越切合实际的。可以着重关注一下Minit的2个feature,可以看到在推理的初始阶段这2个tensor是不包含什么信息的,随着推理,这2个tensor的信息实际上由t-1时刻的特征替代,整个架构的前一部分是做t-1 - > t时刻的预测,后一个阶段是做t-1和t时刻的特征融合和t时刻的状态估计,整个流程和卡尔曼滤波几乎别无二致,这也算是一种致敬吧,哈哈哈
思考点:这里的所有CA能不能参考LLM换成因果attention?
预测端到端
1. FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
虽然是21年的文章,但是确实非常经典
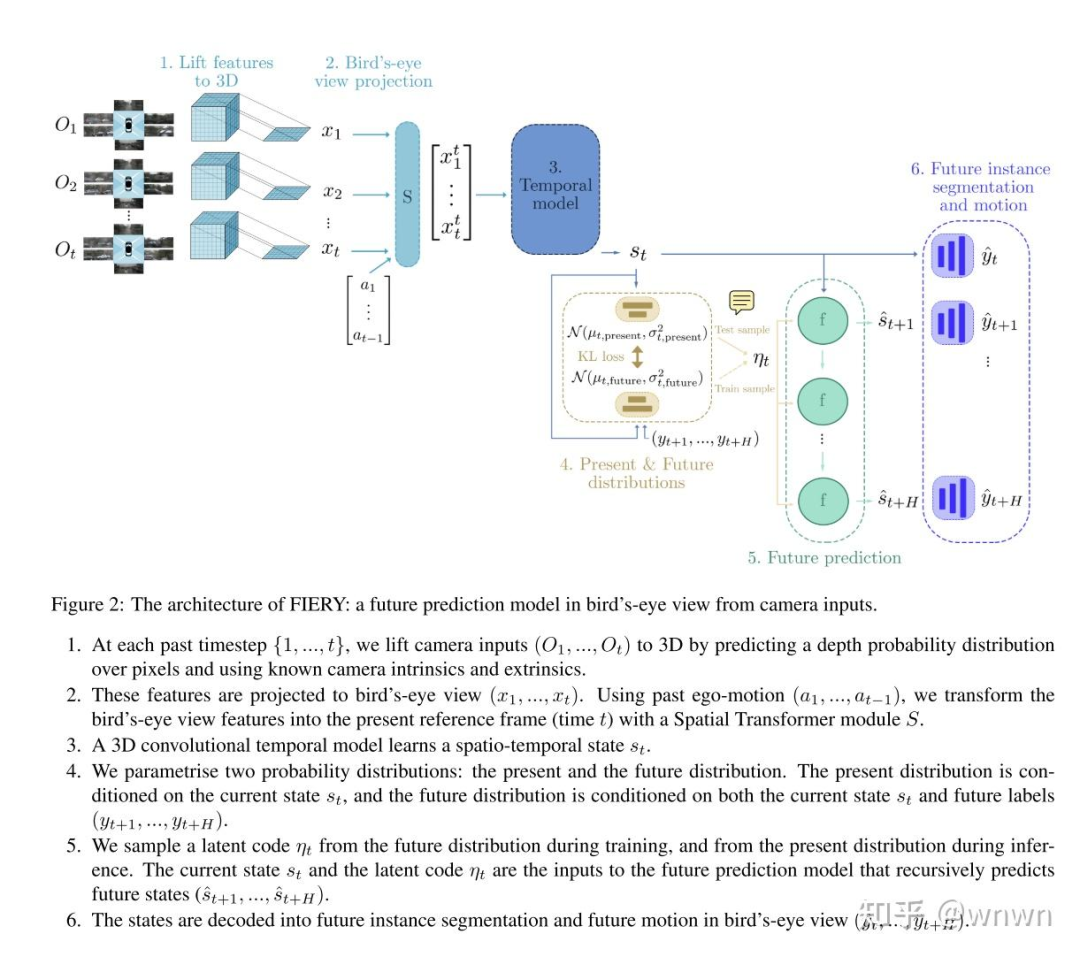
文章的预测部分引入一个隐藏的状态,这个状态满足个元素相互独立的多元正态分布,通过网络预测其期望和方差,再通过分布采样一个状态作为当前时刻的隐藏状态,这个隐藏状态又作为输入用来预测下一时刻的环境。
个人觉得这样建模是比较好的体现了未来的不确定性。
2. Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction
把障碍物轨迹预测建模为多智能体+多运动模式的组合,核心点在下面这个公式,可以按MapTRV2的思路去理解,即智能体和运动模式看做正交的2个变量,通过2者间的组合可以构建其智能体运动空间

下面是不同运动模式的运动终点的可视化分析,可以看到不同运动模式的偏好
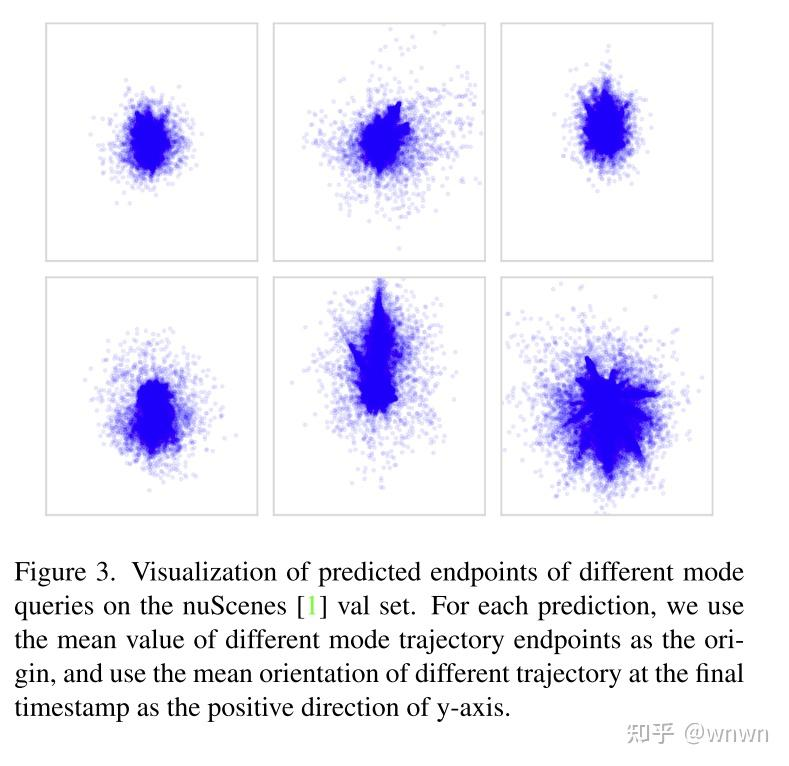
这篇文章的建模稍显复杂,感觉不是很必要,整体思路上参考一下就行了
规划端到端-端到端架构
这一部分主要介绍一下最近看的几篇比较流行的端到端架构,总结一下异同。
1. VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
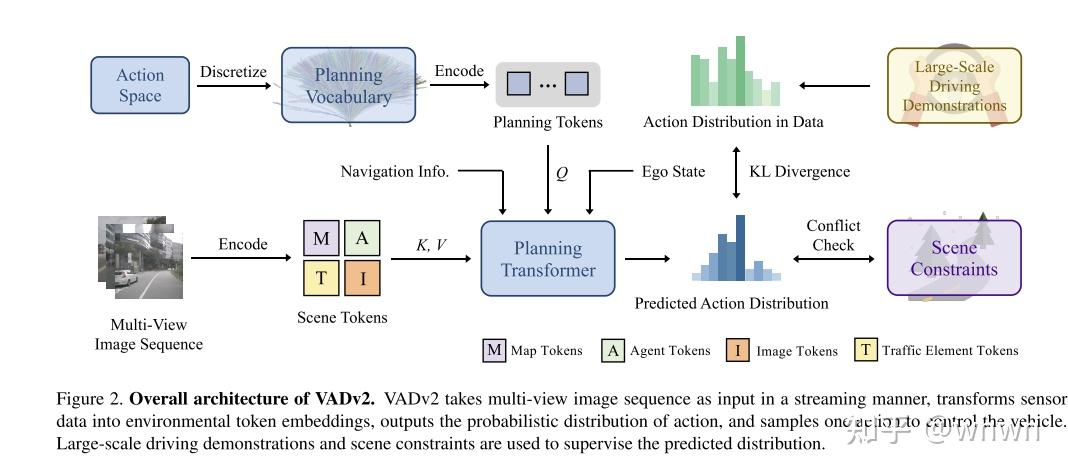
首当其冲的这篇论文架构重点确实清新,指出了端到端的核心点,规划模块。实际上这篇论文很清晰的指出了规划模块的输入输出和约束。
输入包含几块:感知结果,原始图像信息,导航信息和自车运动信息。
输出:规划轨迹的概率分布
监督信号:实际轨迹与预测轨迹的KL散度
约束信息:地图和其他障碍物约束
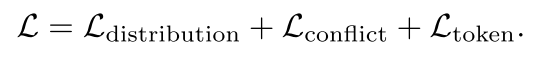
最后提一句损失函数,有3部分:
轨迹的概率分布之间的KL散度
碰撞等约束条件的冲突损失
感知的监督损失
这样重点清晰,逻辑自谦,可视化简洁的文章可真是懒人最爱~~~
2. Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
这篇文章与VAD师出同门,一样优秀的可视化功底,几张图基本把训练流程、模型架构和模块间相互支撑的关系讲清楚了
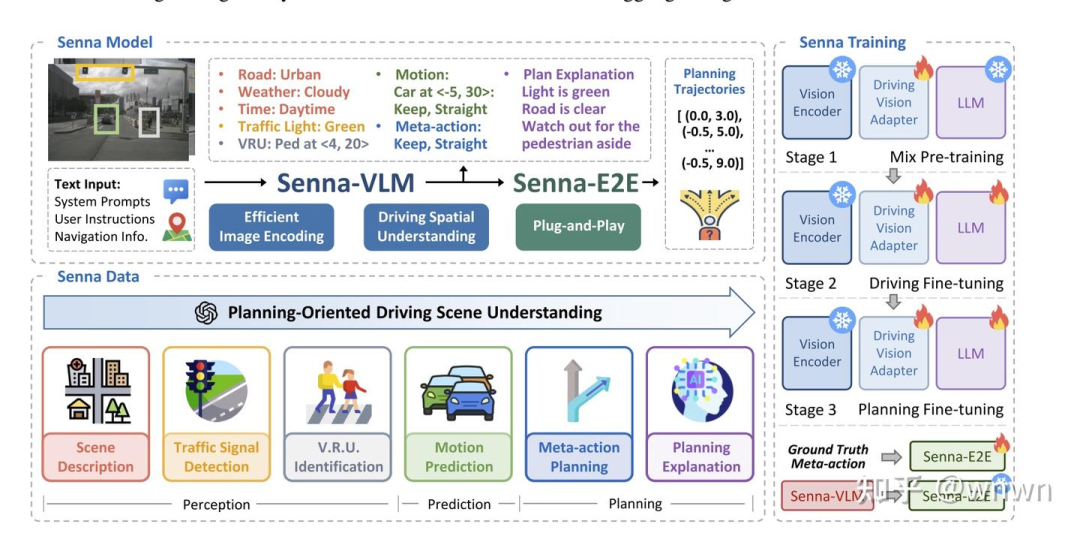
这篇是VLM结合端到端的文章,重点主要在VLM的设计上,以下是VLM关注的几个问题:
场景描述
交通灯状态
VRU信息
其他障碍物的运动信息
自车的运动规划
运动规划的解释
这几个问题解释了规划的逻辑并为端到端提供高级的驾驶意图指导
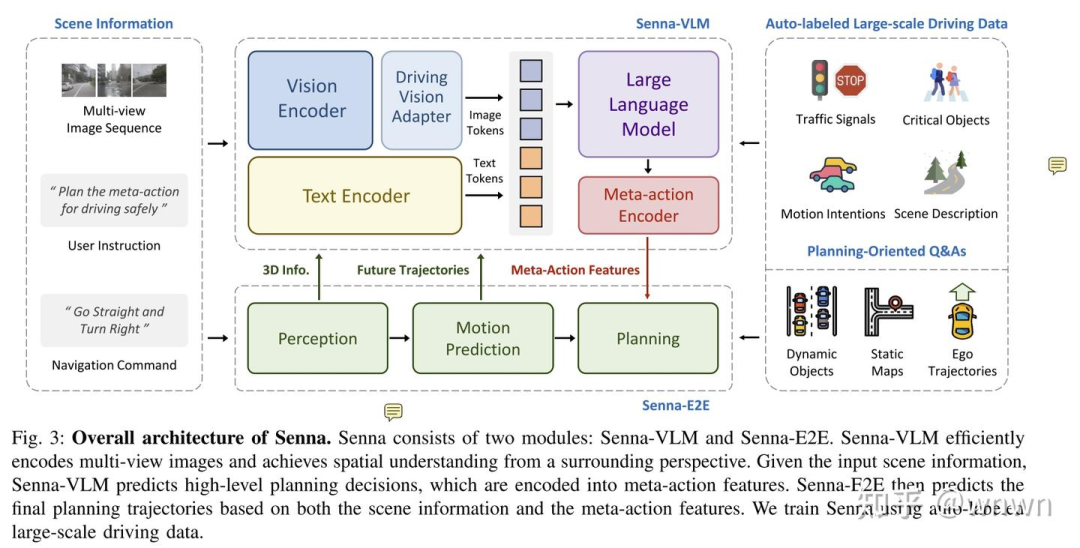
这个图展示了VLM和E2E的信息交互,2个模块间的相互支撑很明显
2.1 DRIVEVLM: The Convergence of AutonomousDriving and Large Vision-Language Models
DriveVLM的架构跟Senna很像,都是VLm和E2E并行交互,但是某种程度上来说DriveVLM走的更远一些
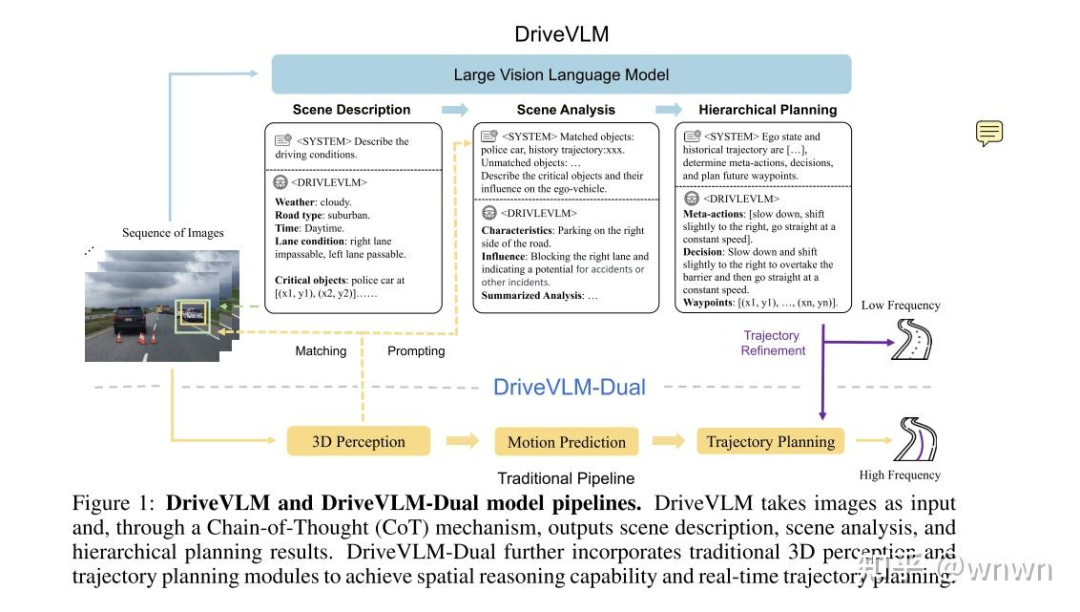
上面是DriveVLM的架构,VLM的推理部分更加格式化,且推理之间的递进关系可能能帮助其推理逻辑更加缜密
VLM推理的3步:
分析理解场景,找出关键障碍物
分析关键障碍物,给出其状态和其与自车的交互信息
生成驾驶意图,分为3层:
3.1 meta-action:意图动作
3.2 decision:动作规划
3.3 Waypoints:具体的轨迹点
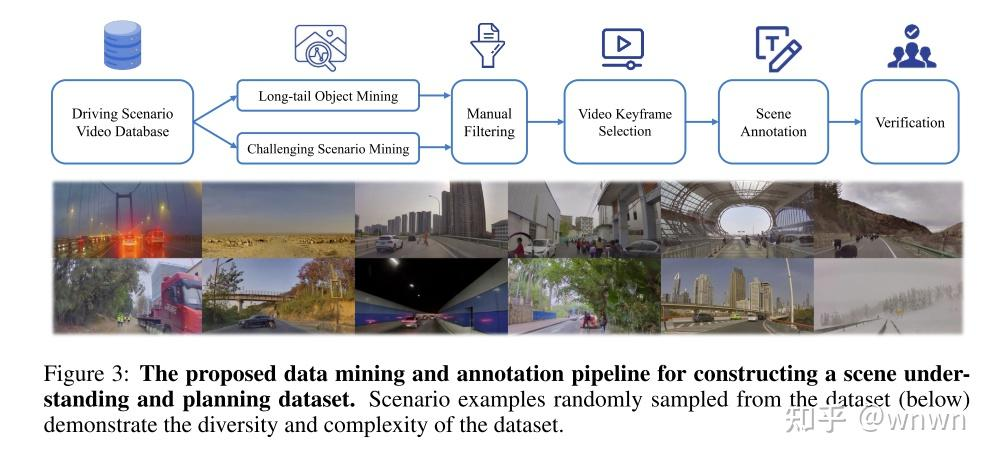
还给出了推理标注流程,数据集构建流程:
长尾目标挖掘和挑战的场景挖掘
人工过滤
关键帧挑选
场景标注
人工校验
3. EMMA: End-to-End Multimodal Model for Autonomous Driving
这篇文章是纯VLM支撑的端到端自动驾驶,输入图像和文本信息,输出感知和规划路径
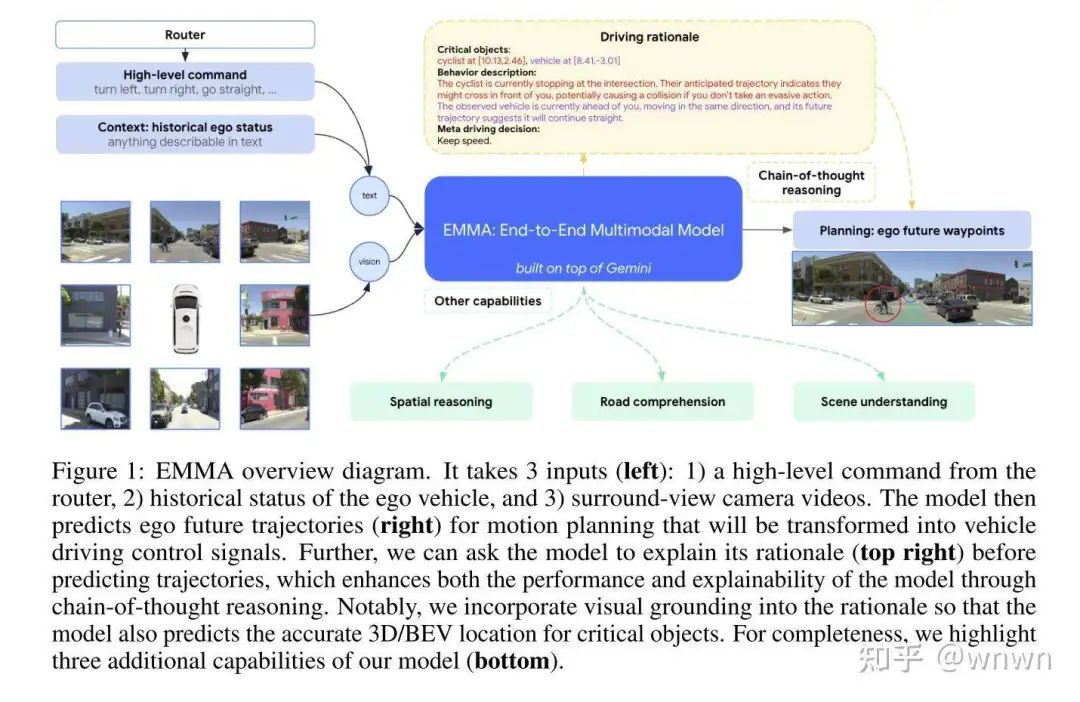
基于CoT的规划,推理部分包含4个主题:
场景理解
关键目标
关键物体的行为描述
元决策(例如保持低速直行)

方案有些激进,但是一体化的思路值得参考
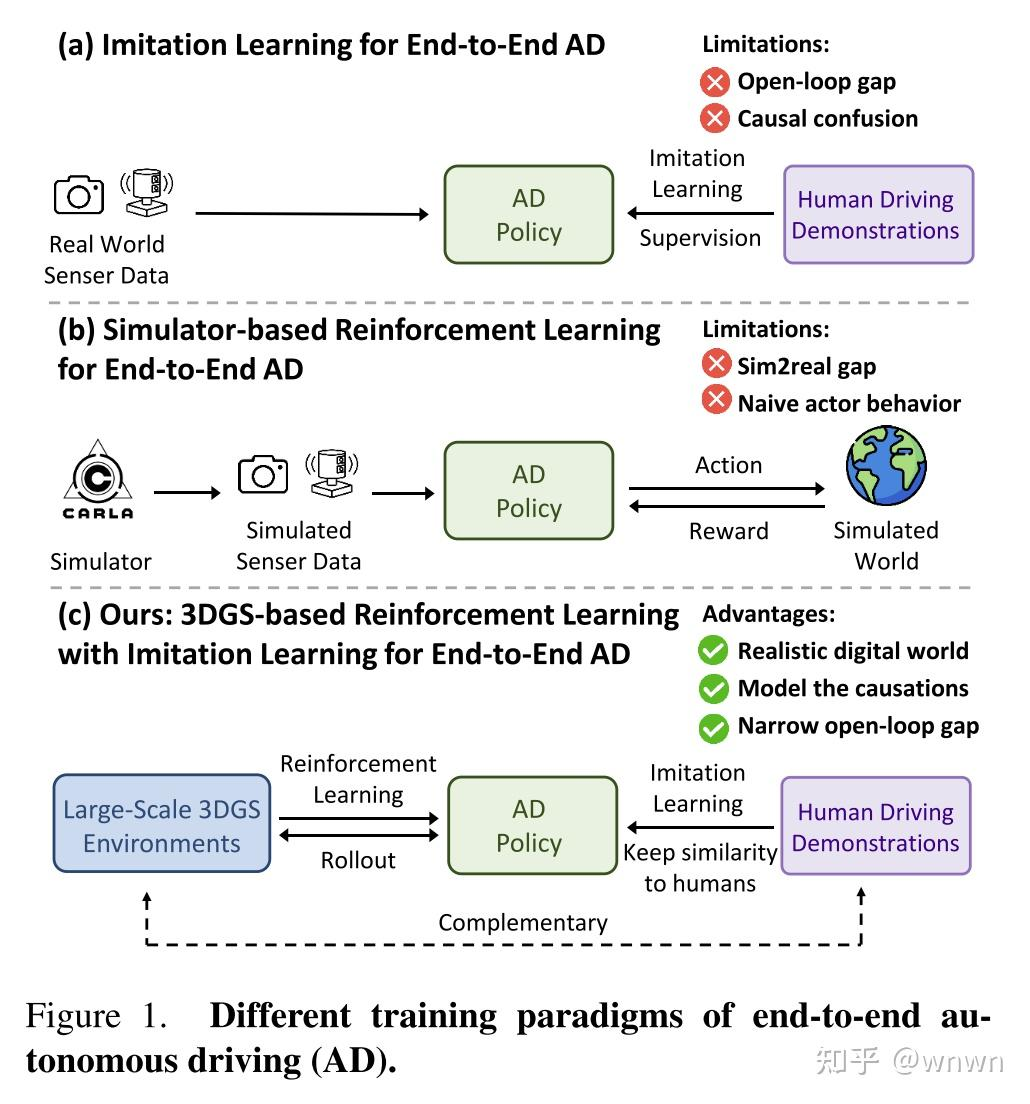
4. RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based
Reinforcement Learning
提出利用GS多视角图像,支持训练的反馈闭环
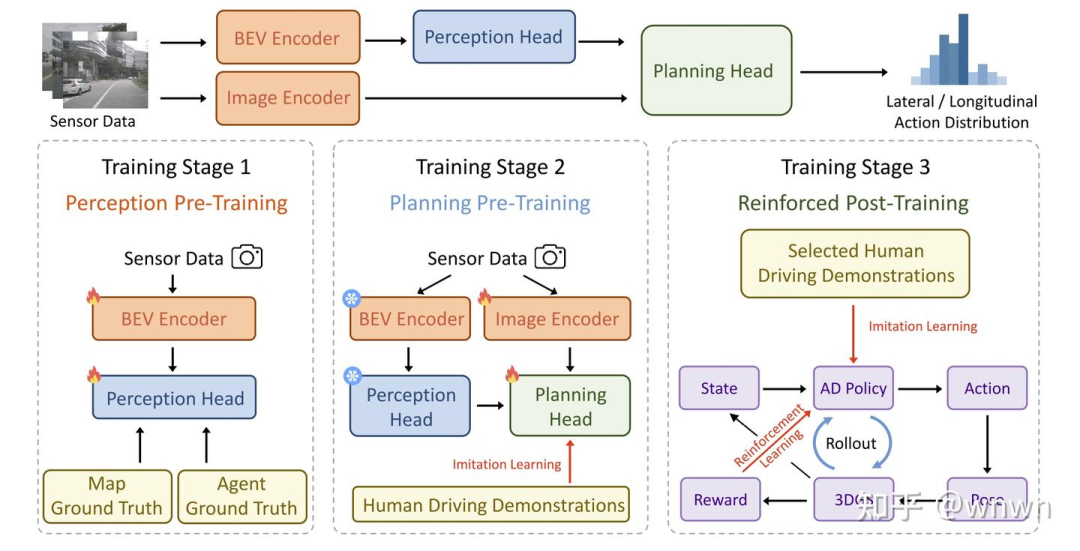
3阶段训练:
s1:感知预训练
s2:规划预训练
s3:规划策略网络强化学习
同时使用PPO强化学习和模仿学习
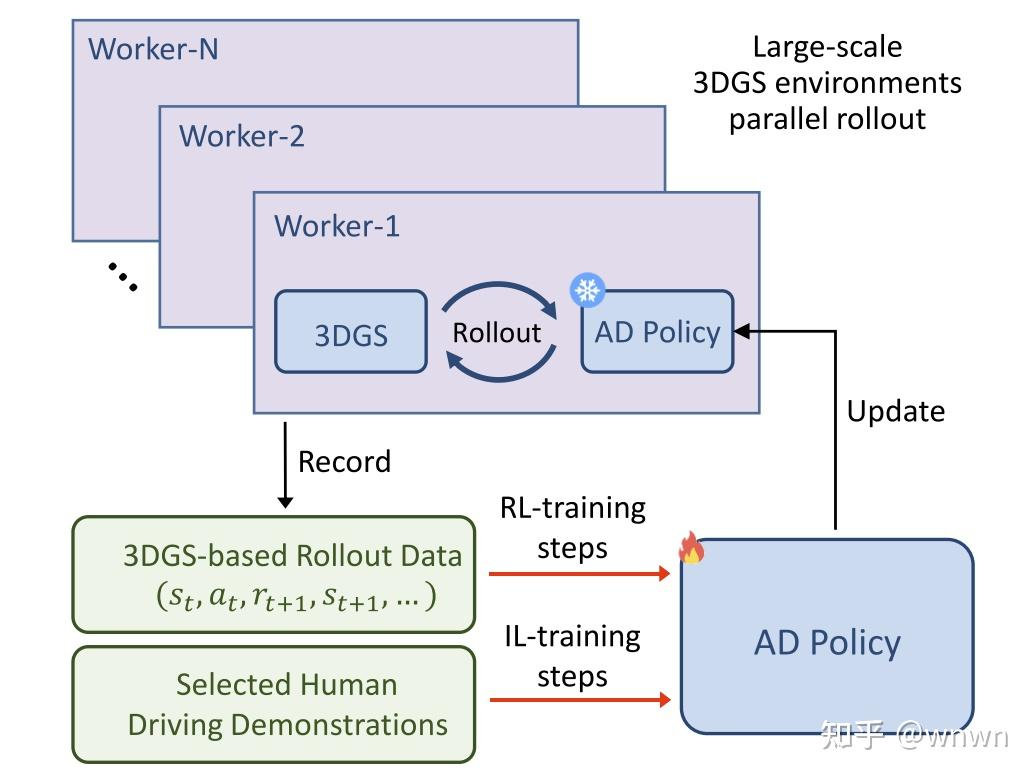
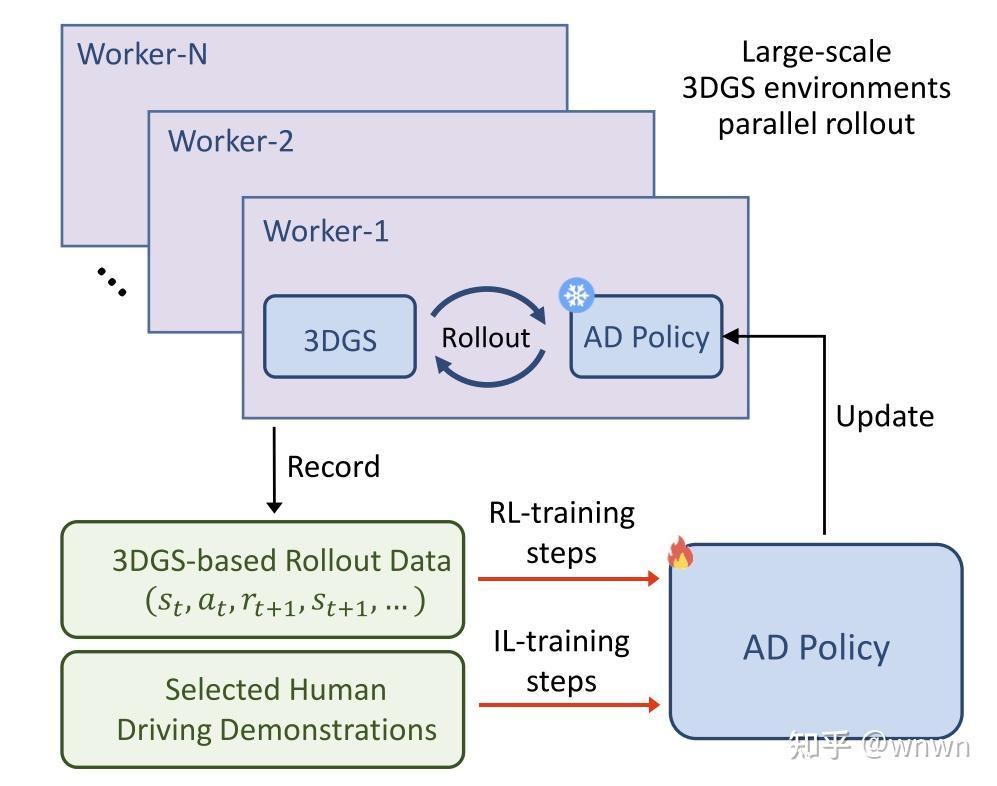
强化学习的4种反馈信息,GS生成能比较好的模拟这些corner case:
动态障碍物碰撞
静态账务碰撞
位置偏移专家轨迹
航向角偏移专家轨迹

以上是我最近关注端到端自动驾驶的一些记录,欢迎大家来一起讨论~
① 自动驾驶论文辅导来啦
② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









