







1. 引言
近年来,具身智能正悄然成为科技领域的新风口。从最初试探性的机器人走路跌跌撞撞,到如今能在春晚舞台上翩翩起舞、在高速奔跑中展现灵敏反应,机器人运动控制技术正以前所未有的速度进步。构建一个具备类人认知与运动能力的AGI机器人,不仅是许多科研工作者的梦想,更是工业界迈向智能制造的重要突破。随着量产流程不断成熟以及硬件成本的持续降低(价格已降至万元级别左右),机器人从实验室逐渐走向实际应用的舞台。本文基于《宇树开源整理(1) - 概览》的系列文章,结合当前网络上的前沿研究信息,全面解析宇树开源平台的技术体系,并对相关算法和实验细节做进一步探讨。
2. 开源仓库全景解析
宇树开源平台目前涵盖了超30个不同项目,其中以下16个仓库在GitHub上受到了广泛关注,按Star数降序排列如下:
| 排名 | 仓库名称 | 仓库介绍 | Star 数量 |
|---|---|---|---|
| 1 | unitree_rl_gym | 基于NVIDIA Isaac强化学习示例,支持Go2、H1、G1等多个型号机器人。 | 1516 |
| 2 | unitree_ros | ROS仿真包,内含所有Unitree系列机器人的URDF文件,并提供详细的物理参数。 | 767 |
| 3 | avp_teleoperate | 利用Apple Vision Pro平台实现远程操控Unitree G1和H1_2机器人。 | 677 |
| 4 | unitree_guide | 结合《四足机器人控制算法 —— 建模、控制与实践》一书的实例,实现控制算法示范。 | 373 |
| 5 | unitree_legged_sdk | 面向Aliengo、A1、Go1、B1等机器人开发真实环境应用的SDK。 | 332 |
| 6 | unitree_mujoco | 以Mujoco为模拟器,支持C++/Python接口,集成地形生成器,用于仿真与真实系统之间的迁移。 | 326 |
| 7 | point_lio_unilidar | 针对SLAM实现的Point-LIO激光惯性里程计,适用于Unitree L1激光雷达。 | 277 |
| 8 | unitree_sdk2 | 为Go2、B2、H1、G1等机器人在真实环境开发提供SDK工具。 | 252 |
| 9 | unitree_IL_lerobot | 以G1双臂作为数据采集及测试平台,基于改进的LeRobot框架实现。 | 168 |
| 10 | unitree_ros2 | 在ROS2环境下开发Go2与B2机器人,接口与unitree_sdk2保持一致。 | 196 |
| 11 | unitree_sdk2_python | unitree_sdk2的Python接口。 | 121 |
| 12 | unitree_model | 提供多种格式的机器人3D建模文件(包括xacro和URDF)。 | 39 |
| 13 | kinect_teleoperate | 利用Azure Kinect DK相机,实现对Unitree H1机器人的远程操控。 | 42 |
| 14 | unitree_actuator_sdk | 针对机器人执行器(电机等)的专用SDK。 | 61 |
| 15 | unilidar_sdk2 | 针对Unitree L2激光雷达开发的SDK。 | 12 |
| 16 | z1_ros | 针对Z1机器人的ROS仿真包。 | 23 |
各仓库从底层物理建模到高层控制策略,构成了一个完整、开放的机器人研发生态。这样的开放平台不仅加速了学术研究的进程,也大大降低了机器人技术应用的门槛。
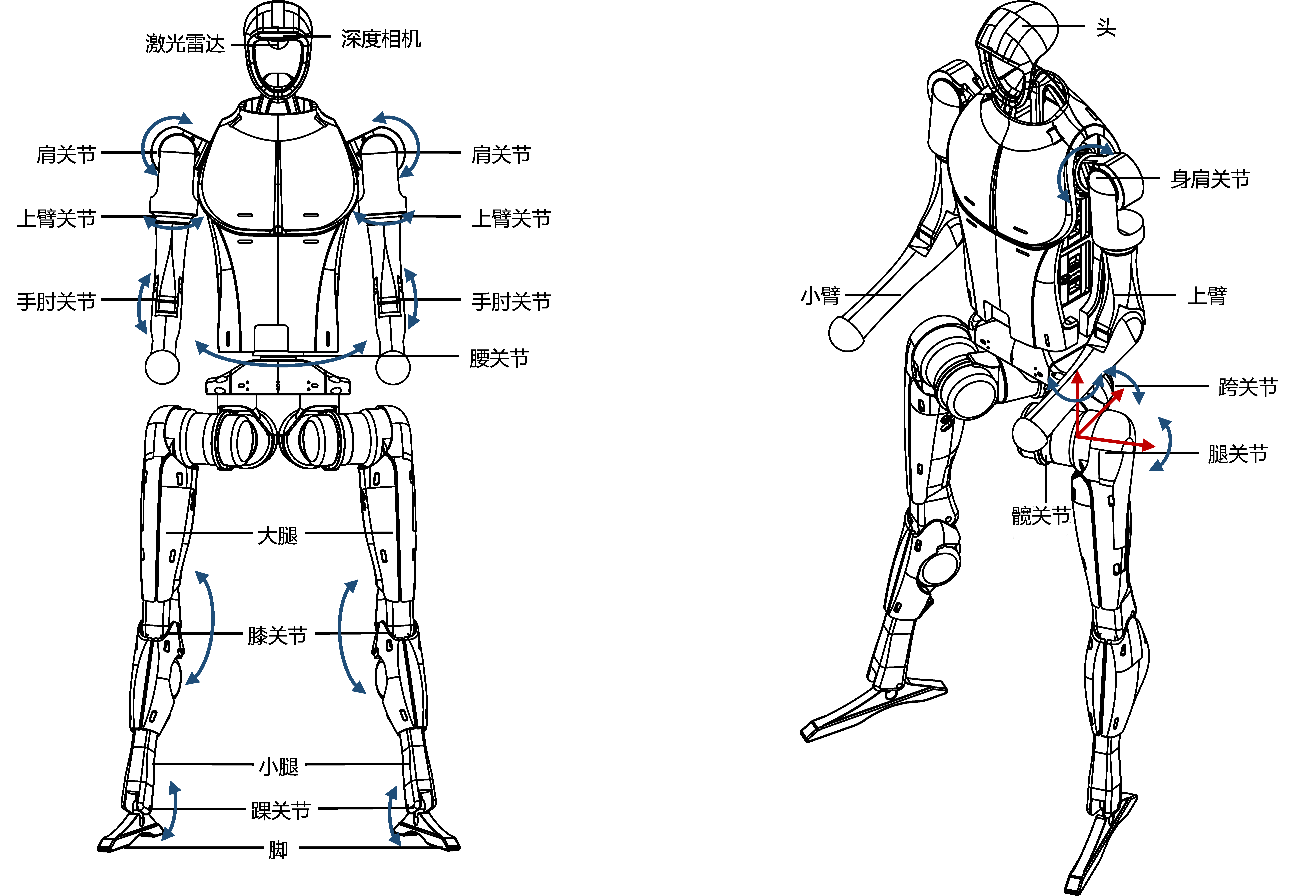
3. 人形机器人平台与硬件构成
目前市面上最具代表性的人形机器人包括Unitree H1、H1-2和G1,它们在感知模块、处理器配置以及自由度设计上各有侧重:
| 机器人名称 | 感知传感器 | 控制计算单元 | 开发计算单元 | 总自由度(单腿/单手臂) |
|---|---|---|---|---|
| Unitree H1 | 3D激光雷达(MID-360) + 深度相机(D435) | Intel Core i5-1235U | Intel Core i7-1255U/1265U | 5/4 |
| Unitree H1-2 | 3D激光雷达(MID-360) + 深度相机(D435) | Intel Core i5-1235U | Intel Core i7-1255U/1265U | 6/7 |
| Unitree G1 | 3D激光雷达(MID-360) + 深度相机(D435i) | —— | Jetson Orin NX | 6/5 |
注意: 此处"运控计算单元"指机器人内部专用的运动控制程序,不对外开放;而"开发计算单元"则提供了二次开发接口,为算法升级和功能扩展提供硬件支持。
!机器人硬件示意图
此外,当前硬件平台不断追求轻量化与高性能计算的平衡,这不仅使得机器人运动更加敏捷准确,同时也为多传感器融合和实时决策提供了保障。诸如Jetson Orin NX这样的嵌入式计算平台已成为智能机器人控制的重要加速器。
4. 强化学习基础与实现原理
4.1 核心要素综述
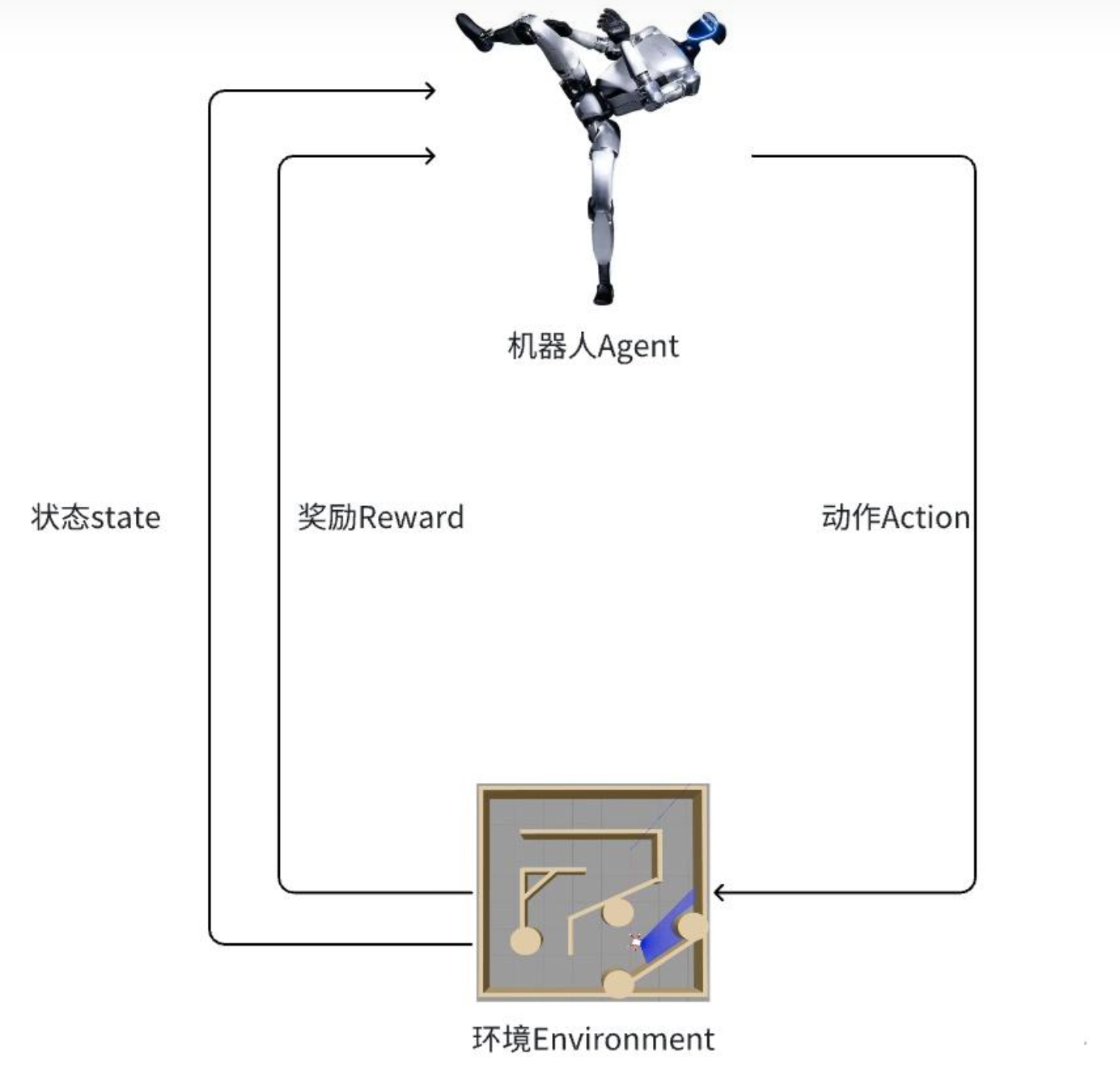
强化学习(Reinforcement Learning, RL)依靠智能体(agent)在与环境不断交互的过程中,通过奖惩反馈逐步优化行为策略,以达到长期收益最大化。其基本框架包括:
- 环境(Environment): 如今主流的机器人仿真平台包括英伟达的Isaac Gym(现升级为Isaac Lab)。
- 动作(Action): 机器人控制目标,通过传递给PD控制器实现关节位置或速度的精密调整。
奖励函数(Reward): 用于量化动作效果的代码模块,每个细分部分(如速度、角速度、加速度、碰撞等)都设置了相应惩罚或奖励。
在物理模拟与真实部署中,奖励函数及其各项指标至关重要。例如,以下部分代码展示了激励基准和惩罚项的计算过程:
| 函数名 | 功能描述 | 计算公式 |
|---|---|---|
_reward_lin_vel_z | 惩罚 z 轴的基础线性速度 | torch.square(self.base_lin_vel[:, 2]) |
_reward_ang_vel_xy | 惩罚 xy 轴的基础角速度 | torch.sum(torch.square(self.base_ang_vel[:, :2]), dim=1) |
_reward_orientation | 惩罚非水平的基础朝向 | torch.sum(torch.square(self.projected_gravity[:, :2]), dim=1) |
_reward_base_height | 惩罚基础高度偏离目标值 | torch.square(base_height - self.cfg.rewards.base_height_target)其中 base_height = self.root_states[:, 2] |
_reward_torques | 惩罚施加的扭矩 | torch.sum(torch.square(self.torques), dim=1) |
_reward_dof_vel | 惩罚关节自由度的速度 | torch.sum(torch.square(self.dof_vel), dim=1) |
_reward_dof_acc | 惩罚关节自由度的加速度 | torch.sum(torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1) |
_reward_action_rate | 惩罚动作的变化 | torch.sum(torch.square(self.last_actions - self.actions), dim=1) |
_reward_collision | 惩罚选定身体部位的碰撞 | torch.sum(1.*(torch.norm(self.contact_forces[:, self.penalised_contact_indices, :], dim=-1) > 0.1), dim=1) |
_reward_termination | 终端奖励 / 惩罚 | self.reset_buf * ~self.time_out_buf |
_reward_dof_pos_limits | 惩罚关节自由度位置接近极限值 | torch.sum(out_of_limits, dim=1)其中 out_of_limits = -(self.dof_pos - self.dof_pos_limits[:, 0]).clip(max=0.) + (self.dof_pos - self.dof_pos_limits[:, 1]).clip(min=0.) |
_reward_dof_vel_limits | 惩罚关节自由度速度接近极限值 | torch.sum((torch.abs(self.dof_vel) - self.dof_vel_limits * self.cfg.rewards.soft_dof_vel_limit).clip(min=0., max=1.), dim=1) |
_reward_torque_limits | 惩罚扭矩接近极限值 | torch.sum((torch.abs(self.torques) - self.torque_limits * self.cfg.rewards.soft_torque_limit).clip(min=0.), dim=1) |
_reward_tracking_lin_vel | 跟踪线性速度指令(xy 轴) | torch.exp(-lin_vel_error / self.cfg.rewards.tracking_sigma)其中 lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1) |
_reward_tracking_ang_vel | 跟踪角速度指令(偏航) | torch.exp(-ang_vel_error / self.cfg.rewards.tracking_sigma)其中 ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2]) |
_reward_feet_air_time | 奖励长步幅 | 一系列逻辑处理后得到 rew_airTime,逻辑见原代码 |
_reward_stumble | 惩罚脚撞到垂直表面 | torch.any(torch.norm(self.contact_forces[:, self.feet_indices, :2], dim=2) > 5 * torch.abs(self.contact_forces[:, self.feet_indices, 2]), dim=1) |
_reward_stand_still | 惩罚零指令下的运动 | torch.sum(torch.abs(self.dof_pos - self.default_dof_pos), dim=1) * (torch.norm(self.commands[:, :2], dim=1) < 0.1) |
_reward_feet_contact_forces | 惩罚脚部的高接触力 | torch.sum((torch.norm(self.contact_forces[:, self.feet_indices, :], dim=-1) - self.cfg.rewards.max_contact_force).clip(min=0.), dim=1) |
注意:这是标准的奖励函数,每个机器人都有一些微调的奖励函数,这里就不一一整理了。
4.2 观测和动作通道
观测信息由多个部分拼接而成,包括:
-
机器人的线速度 (
base_lin_vel)
通过obs_scales.lin_vel进行缩放。 -
机器人的角速度 (
base_ang_vel)
通过obs_scales.ang_vel进行缩放。 -
投影重力 (
projected_gravity) -
控制命令的前三个维度
包括 x 速度、y 速度和偏航速度,通过commands_scale进行缩放。 -
关节位置相对于默认位置的偏差
计算方式为self.dof_pos - self.default_dof_pos,并通过obs_scales.dof_pos进行缩放。 -
关节速度 (
dof_vel)
通过obs_scales.dof_vel进行缩放。 -
上一步的动作 (
actions)
4.3 动作 (Action)
在代码实现中,动作可以被看作是传递给比例-微分控制器(PD 控制器)的位置或速度目标。PD 控制器是机器人控制中常用的方法,它根据当前状态和目标状态(由动作表示)计算需要施加的扭矩,从而使机器人的关节移动到期望的位置或达到期望的速度。
注意: 计算得到的扭矩维度必须与机器人的自由度(DOFs,Degrees of Freedom)数量一致。即使某些自由度没有被驱动(没有对应的执行器控制这些自由度的运动),也必须满足该要求。这是为了确保扭矩向量能够与机器人的每个关节正确对应,以便于后续的控制操作。
在 _compute_torques 方法中,根据配置文件中 control_type 的不同取值,代码对动作进行了不同方式的处理。
5. 模仿学习 (Imitation Learning)
5.1 工作原理与技术基础
模仿学习是一种通过观察和复制人类或其他专家示范的动作来学习行为的技术。在机器人领域,这种方法极为重要,尤其在复杂动作学习中发挥关键作用。其核心思想可以概括为"看和做"(watch-and-learn):机器人观察人类的运动示范,然后生成相似的运动轨迹。
5.1.1 算法框架:Motion Matching
传统的Motion Matching最早源于游戏行业,它通过查找动作库中最匹配当前状态的下一个动作来生成连贯动作。而Learned Motion Matching则是其深度学习版本,通常包含三大核心组件:
- Decompressor(解压器)
功能:将高维关节状态无损地转换为低维潜在向量表示
技术实现:通常采用变分自编码器(VAE)或其变体
数学表示:
f d e c : R j → R d f_{dec}:R_j \rightarrow R_d fdec:Rj→Rd,其中 j j j是关节空间维度, d d d是潜在空间维度,通常 d ≪ j d \ll j d≪j


















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











