







CodeRAG-Bench:RAG遇到了Coder,哪个模型在RAG的加持下最会写代码?
发布时间:2024 年 06 月 20 日
RAG
CodeRAG-Bench: Can Retrieval Augment Code Generation?
检索增强生成(RAG)在文本任务中已显成效,但在代码生成上的潜力却鲜为人知。本研究深入探讨:何时检索能助力代码生成?又面临哪些挑战?构建了 CodeRAG-Bench 评估基准,覆盖基础编程、开放领域及仓库级代码生成三大任务,并整合了来自竞赛、教程、文档、论坛及代码库的五类文档资源。测试了顶尖模型,通过提供单一或多元来源的检索上下文,发现高质量上下文的引入显著提升了代码质量,但仍存在改进空间:检索器在词汇重叠有限时难以获取有用信息,生成器在上下文受限或整合能力不足时表现不佳。我们期待 CodeRAG-Bench 成为推动高级代码生成 RAG 技术发展的有力平台。
https://arxiv.org/abs/2406.14497
1. CodeRAG-Bench是什么?
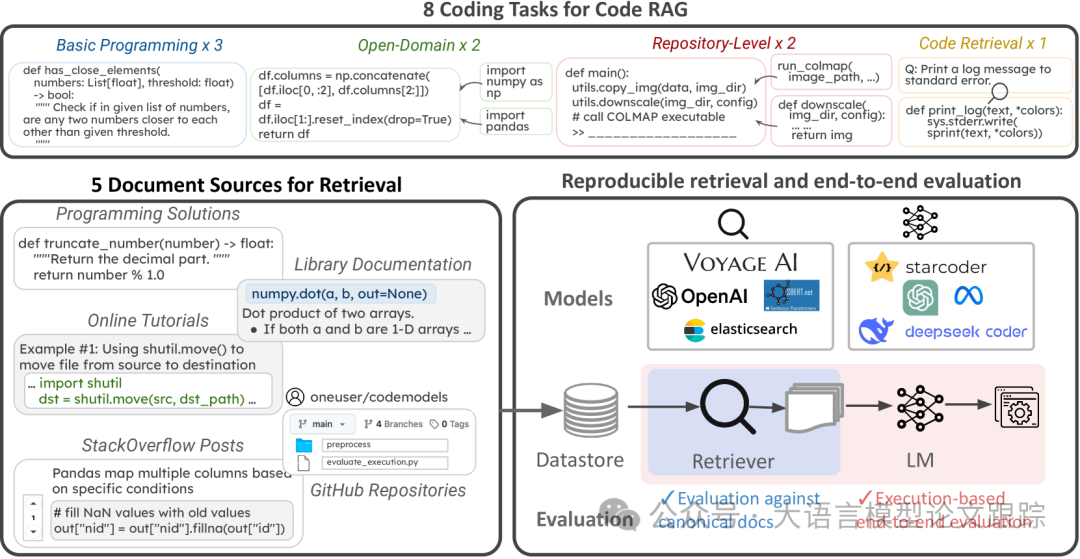
CodeRAG-Bench是本文作者为检索增强代码生成(Retrieval Augment Code Generation,RACG)任务设计的一个测试评估基准。构建理念来自三个核心要素:
-
• (i)任务多样性:代码生成任务覆盖了从代码行到函数再到整个代码库的不同层面,以及封闭与开放的不同领域。
-
• (ii)严谨且可复现的评估机制:提供了精确的文档标注,以支持检索评估。
-
• (iii)统一的接口设计:尽管现有数据集采用了多样化的处理流程,代码库提供了一个统一的接口,用于实现检索、增强生成及评估。
接下来的内容里,作者从CodeRAG-Bench的构建角度来向大家展示了CodeRAG-Bench的全貌:在本节中,我们将详细介绍CodeRAG-Bench的构建流程:编程问题分类、检索资料收集、标注标准文档以及设置评估流程。
2. 如何将编程任务进行分类
本文作者专注于Python编程任务,将Python编程任务和数据集归为四大类:代码检索、基础编程、开放域问题、仓库级代码问题。
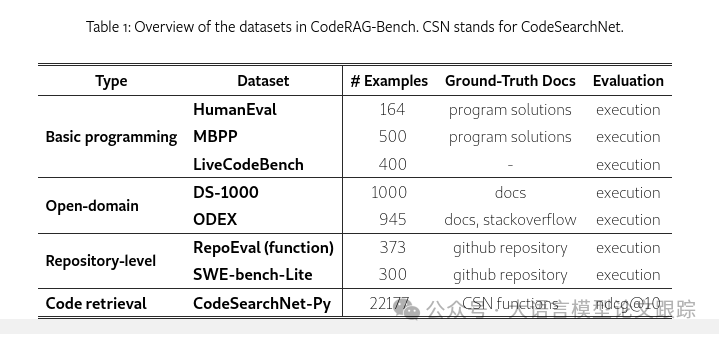
2.1.1 基础编程问题
这一类问题通常以面试题目的形式出现,主要依赖Python的内置功能来解决算法挑战。
选取了两个广泛使用的数据集:HumanEval 和 MBPP ,它们要求模型根据自然语言描述来补全函数。
然而,由于模型训练数据的公共信息有限,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











