







文章目录
- AMTSS: An Adaptive Multi-Teacher Single-Student Knowledge Distillation Framework For Multilingual Language Inference
- Learning Accurate, Speedy, Lightweight CNNs via Instance-Specific Multi-Teacher Knowledge Distillation for Distracted Driver Posture Identification
- MTKDSR: Multi-Teacher Knowledge Distillation for Super Resolution Image Reconstruction
- Multi-Teacher Knowledge Distillation For Text Image Machine Translation
- Corrosion detection on aircraft fuselage with multi-teacher knowledge distillation
- Collaborative Multi-Teacher Knowledge Distillation for Learning Low Bit-width Deep Neural Networks
- Robust Semantic Segmentation With Multi-Teacher Knowledge Distillation
AMTSS: An Adaptive Multi-Teacher Single-Student Knowledge Distillation Framework For Multilingual Language Inference
AMTSS:一个适用于多语言推理的自适应多教师单学生知识提取框架
paper"https://arxiv.org/pdf/2305.07928v1.pdf
code:with no code
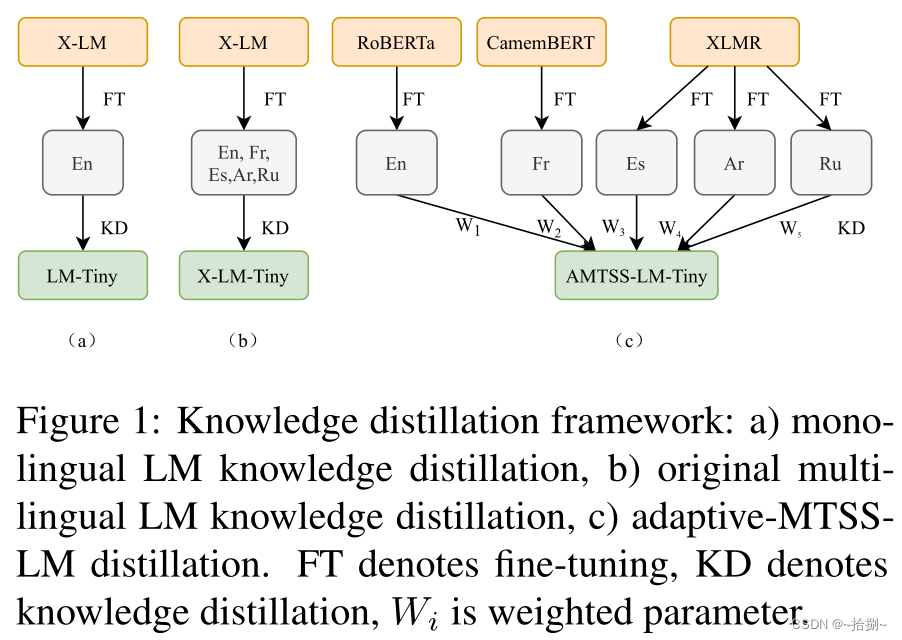
- 提出了一种自适应的多教师单学生知识提取框架,由具有不同投影层的共享学生编码器组成,以经济高效的方式支持多种语言
- 提出了一种基于权重的自适应学习策略,使学生模型能够有效地向具有重要性权重的最大边际教师学习,并轻松适应新出现的语言

具有最大裕度和重要性权重的自适应训练策略:
给定 n n n种语言,首先通过对相应的数据集 D 1 、 D 2 、 … 、 D n D1、D2、…、Dn D1、D2、…、Dn进行微调得到 n n n个教师 T 1 , T 2 … T n T1,T2…Tn T1,T2…Tn。通过向 n n n位重要性加权教师学习获得了学生模型 S S S(第4-6行),在 n n n个验证数据集上评估 S S S(第7-9行),并计算教师的topK最大裕度(第10行)。蒸馏过程将继续向所选的前 K K K个最大裕度教师学习(第11行),并且如果历元的数量超过 M M M或最大裕度小于某个阈值,则蒸馏过程将终止(第12-13行)。
Learning Accurate, Speedy, Lightweight CNNs via Instance-Specific Multi-Teacher Knowledge Distillation for Distracted Driver Posture Identification
通过实例特定的多教师知识提取学习准确、快速、轻量级的神经网络,用于分心驾驶员姿势识别
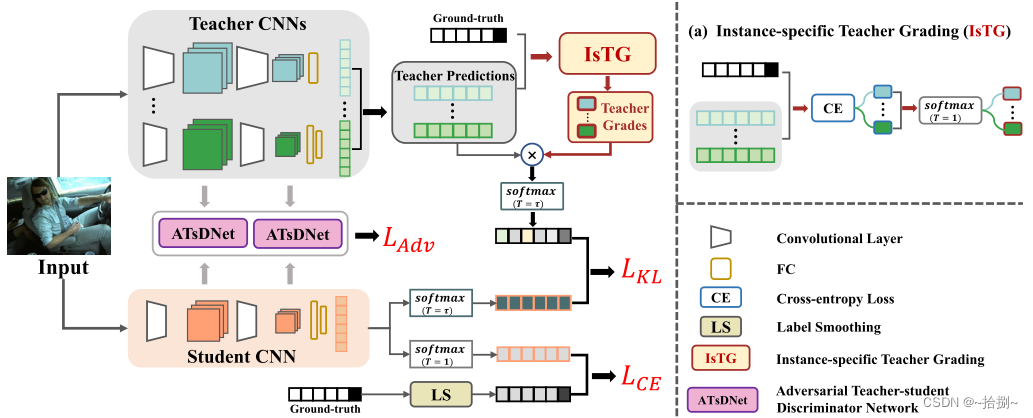
实例特定的多教师知识蒸馏(IsMt KD):对于训练集中的每个实例,表现最好的教师模型,即实现最低交叉熵损失的教师模型将被分配最大的分数。
MTKDSR: Multi-Teacher Knowledge Distillation for Super Resolution Image Reconstruction
MTKDSR:用于超分辨率图像重建的多教师知识提取
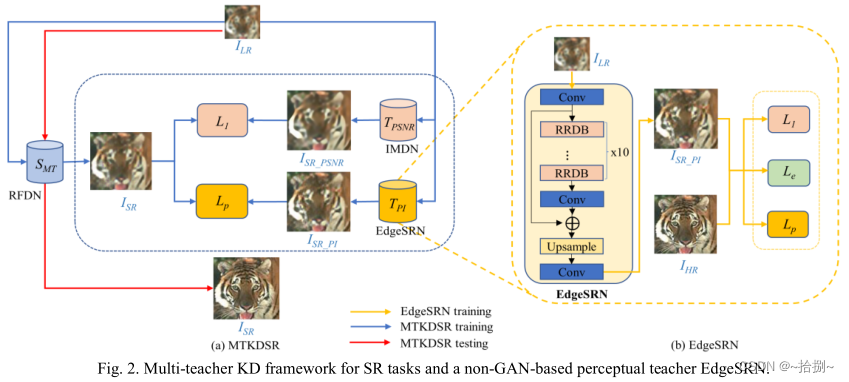
- 两个教师网络来训练一个轻量级的学生网络。一个教师网络以更高的重建精度恢复图像PSNR,另一个网络产生具有更好感知质量的输出PI。 I L R I_{LR} ILR输入得到三个重建SR图,计算 I S R I_{SR} ISR和 I S R _ P S N R I_{SR\_PSNR} ISR_PSNR的逐像素距离损失 L I L_I LI,计算 I S R I_{SR} ISR和 I S R _ P I I_{SR\_PI} ISR_PI的感知损失 L p L_p Lp。
- 为了生成真实和可学习的边缘并降低计算成本,提出EdgeSRN作为一种使用边缘损失引导的感知教师网络,将ESRGAN生成器中的RRDB块的数量从23个减少到10个,并删除了鉴别器。将EdgeSRN的输出的边缘图与原始HR图像的边缘图进行比较来计算被称为 L e L_e Le的边缘损失。拉普拉斯算子用于边缘提取。EdgeSRN是通过最小化总损失来训练的,总损失包括感知、MAE和边缘损失,以生成更逼真的纹理和更少的假边缘,从而确保在KD过程中从教师传递给学生的知识的真实性。
Multi-Teacher Knowledge Distillation For Text Image Machine Translation
文本图像机器翻译的多师知识提炼
paper:https://arxiv.org/pdf/2305.05226v2.pdf
code:with no code
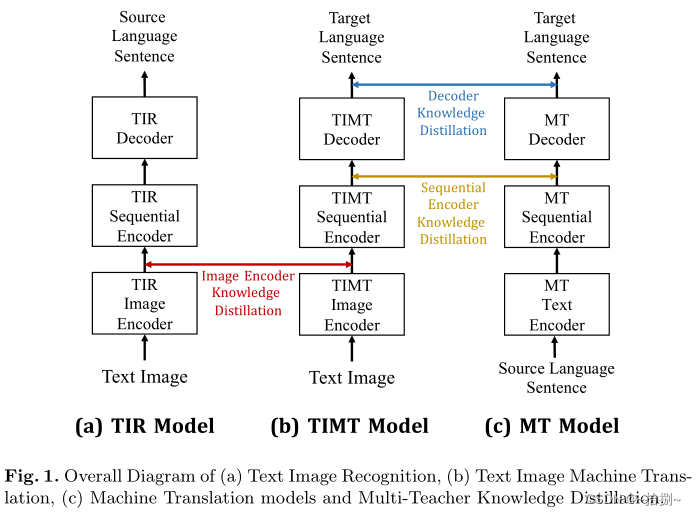
- 端到端TIMT模型中不同的子模块发挥着截然不同的功能,需要不同的知识指导。图像编码器用于从输入文本图像中提取局部视觉特征,顺序编码器进一步从局部视觉特征中编码上下文语义信息,解码器来生成给定序列特征的翻译结果。
- 利用三个教师模型分别指导图像编码器、顺序编码器和解码器的优化:从TIR编码器传递提取文本图像特征的知识;MT顺序编码器提供上下文语义特征学习的指导;MT解码器将目标语言生成知识提取到TIMT解码器中。
Corrosion detection on aircraft fuselage with multi-teacher knowledge distillation
基于多教师知识提取的飞机机身腐蚀检测
paper:https://iccs-meeting.org/archive/iccs2021/papers/127470308.pdf
code:https://github.com/ZuchniakK/DAISCorrosionDetection
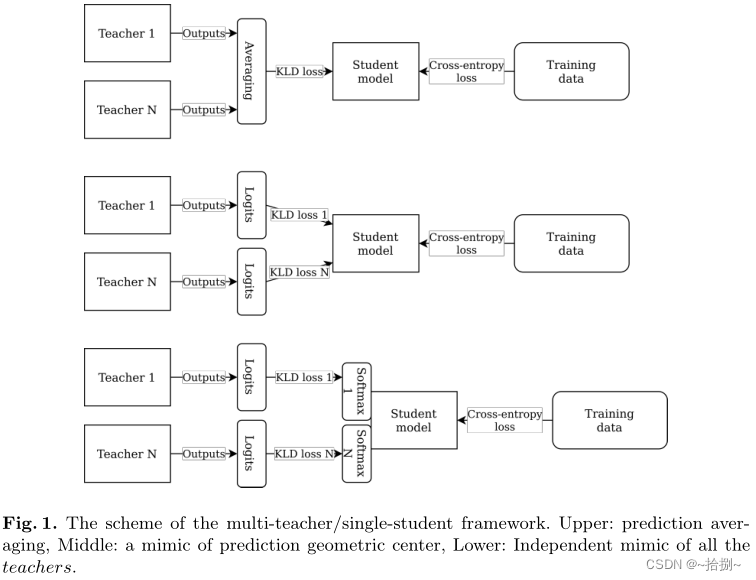
- 预测平均:在教师输出被包括在学生损失函数中之前对集合预测进行平均。学生模型学习模仿多教师集成的平均响应(图1上部)
- 预测几何中心的模拟:在训练过程中,将学生模型的输出与所有 N N N位教师的预测进行单独比较。学生模型学习同时模仿几个老师的预测。由于将预测与单个教师输出过于接近会增加负责模仿其他教师的损失函数的一部分,因此学生模型输出位于所有教师预测的几何中心(图1中间)。
- 对所有 N N N名教师的独立模拟:学生模型的最后一层(或最后几层)被复制 N N N次(每个层都有一组独立的可训练权重,见图1下部)。损失函数是个体输出的一个组成部分,其特定损失定义了基本事实标签相似性和模仿集合中的特定教师。这种方法迫使所有教师转移知识,而不仅仅是从他们的平均水平转移知识。在推理阶段,以这种方式创建的学生模型有最后一个额外的平均层,由 N N N个独立的输出组成,代表单个教师隐喻。
Collaborative Multi-Teacher Knowledge Distillation for Learning Low Bit-width Deep Neural Networks
用于学习低位宽深度神经网络的多教师协作知识提取
paper:https://arxiv.org/pdf/2210.16103v1.pdf
code:with no code
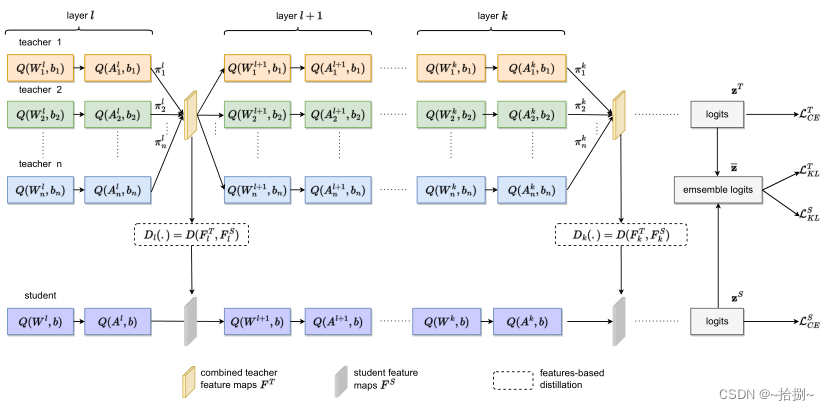
协作式多教师知识提取(CMT-KD):鼓励教师之间的协作学习和教师与学生之间的相互学习。
- 在训练过程中,一组量化教师之间的协作学习通过重要性参数( π π π)在某些层次上形成有用的共享知识,这些知识被提炼到学生网络中的相应层次。 L K L T L^T_{KL} LKLT和 L K L S L^S_{KL} LKLS用于教师和学生之间,通过集成logits z ˉ \bar{z} zˉ进行相互学习,其中 z ˉ \bar{z} zˉ根据教师logits z T z^T zT和学生logits z S z^S zS计算得到。 D ( ⋅ ) D(\cdot) D(⋅)表示基于中间特征的蒸馏的损失(注意力损失或FitNet损失)。
- 来自教师的相应层的知识将被融合以形成共享知识,该共享知识随后将被用作下一层教师的输入。这就形成了教师之间的协作学习。
- 对于每位教师来说,还将学习一个重要因素 π π π,该因素控制教师将为共享知识贡献多少知识。重要因素的学习将鼓励教师之间的合作学习,以产生学生可以有效模仿的合适的共享知识。
Robust Semantic Segmentation With Multi-Teacher Knowledge Distillation
基于多教师知识提取的鲁棒语义分割
paper:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9522137
code:with no code
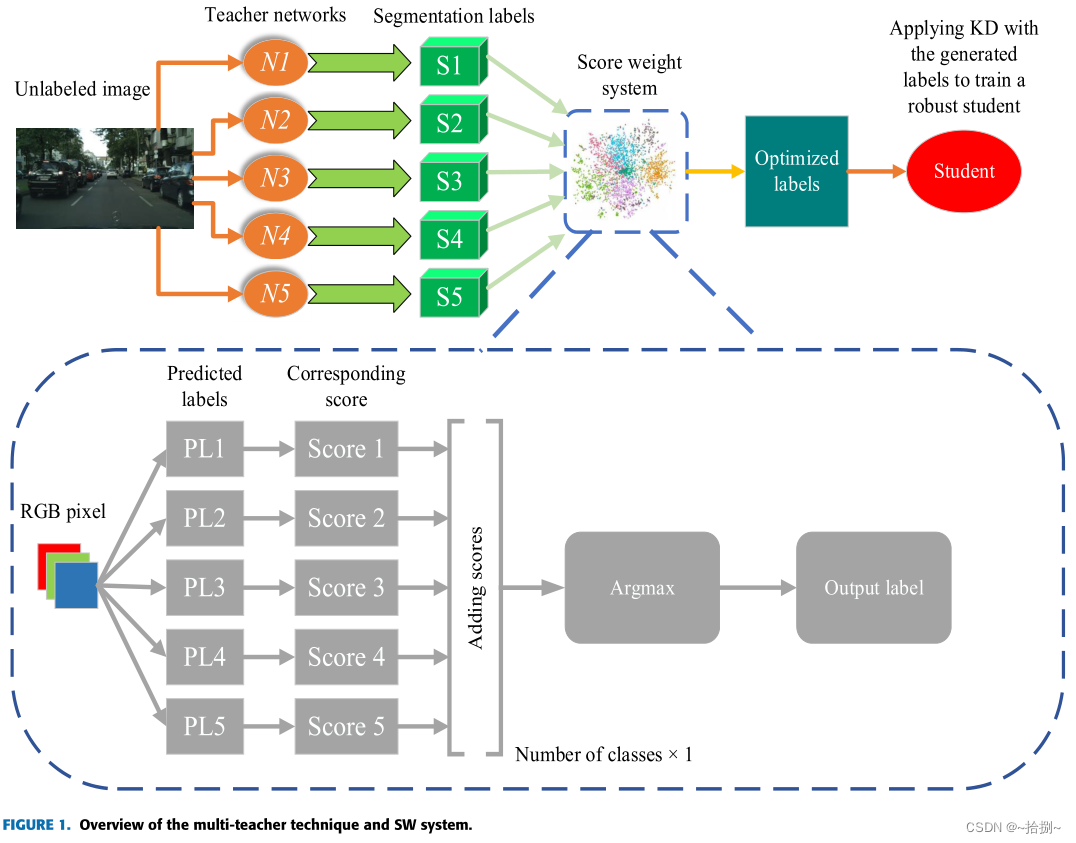
- 通过混合数据集预先训练得到五个教师,这些教师将被用来分割未标记的数据,利用SW分数权重系统,将为未标记的数据集生成优化的标签,并用于学生网络的训练。
- 使用各种合成图像得到损坏图像,每个类在每个网络中都会根据其对干净和损坏数据的分割精度获得一个SW(mIoU作为精度度量)。SW系统选择分数图向量的最大自变量作为标签输出。
- 所有教师网络都是在干净和损坏的数据上进行评估的,以确定哪种场景最能增强模型的稳定性。重复相同的程序来确定每个场景对训练学生模型稳定性的影响。为每个场景组装了一个SW矩阵,通过它在未标记的数据上训练学生。















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









