







局部归一化据说是没啥用,不过既然GNet里面有那还是要写的。
该层需要参数有:
norm_region: 选择对相邻通道间归一化还是通道内空间区域归一化,默认为ACROSS_CHANNELS,即通道间归一化;
local_size:两种表示(1)通道间归一化时表示求和的通道数;(2)通道内归一化时表示求和区间的边长;默认值为5;
alpha:缩放因子(详细见后面),默认值为1;
beta:指数项(详细见后面), 默认值为5;
在通道间归一化模式中,局部区域范围在相邻通道间,但没有空间扩展(即尺寸为 local_size x 1 x 1);
在通道内归一化模式中,局部区域在空间上扩展,但只针对独立通道进行(即尺寸为 1 x local_size x local_size);
每个输入值都除以

![]()
caffe的lrn.cpp文件中有将近200行代码,但是实际上我们用到的只有CrossChannelForward_cpu()这一个函数而已。Forward
意思是向前传播,也就是说还有backward反向传播,是用来算梯度的,我们现在用不上。
在这里将caffe的代码贴出来,一步一步拆解
- const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top) {
- const Dtype* bottom_data = bottom[0]->cpu_data();
- Dtype* top_data = (*top)[0]->mutable_cpu_data();
- Dtype* scale_data = scale_.mutable_cpu_data();//用指针获取每个Blob对象的内存地址,便于后面操作
- // start with the constant value
- for (int i = 0; i < scale_.count(); ++i) {//初始化值为1.0
- scale_data[i] = 1.;
- }
虽然没学过C++,但是我们已经知道了这层的功能,所以大概猜出来这段代码是干什么的并不难。bottom是输入,top是输出,scale用来存放中间数据
大小在这里找不出来,但是根据后面的代码可以算出来scale的大小就是整个输入的大小,初始化为1。下面紫色的立方体就代表输入,画出来的是长6宽6高5
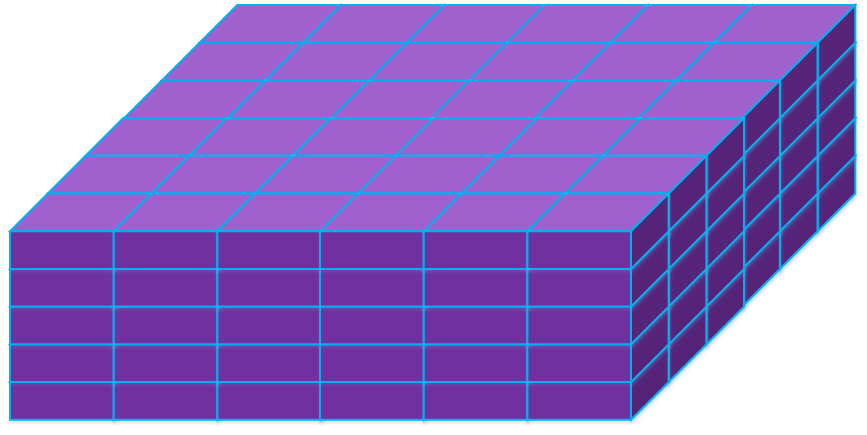
图1
- Blob<Dtype> padded_square(1, channels_ + size_ - 1, height_, width_);//补零后的Blob,第三维尺寸比bottom大了size_ - 1;
- Dtype* padded_square_data = padded_square.mutable_cpu_data();
- caffe_set(padded_square.count(), Dtype(0), padded_square_data);//先清零
padded_square
用来存储平方后的数据,高为
channels_ + size_ - 1,跟卷积时候添加的pad类似要上下各延伸一部分,
下图那些透明的部分始终为0,存放数据时候直接跳过。
最前面的1是长宽高以外的第四维度,我并不知道他是做什么的,但是并不影响,我们继续看。
- Dtype alpha_over_size = alpha_ / size_;//预先计算公式中的alpha/n
- // go through the images
- for (int n = 0; n < num_; ++n) {//bottom的第四维尺寸num_,需要分解为单个来做归一化
- // compute the padded square
- caffe_sqr(channels_ * height_ * width_,
- bottom_data + bottom[0]->offset(n),
- padded_square_data + padded_square.offset(0, pre_pad_));//计算bottom的平方,放入padded_square矩阵中,前pre_pad_个位置依旧0
for循环不用看,因为在这里num=1。难点在于理解caffe_sqr:在caffe下面的math_function.cpp文件里我们可以找到caffe_sqr的定义
caffe_sqr(int len,float* a,float* b) ,意思就是b[i]=a[i]*a[i],执行len次。关于offset(n),可以回想在卷积层我们每次执行计算都要找到现在计算的点
是所有输入中的第几个,在这里offset就是起到这个作用。offset(int num,int channel,int hight,int width)输入当前所在位置就可以得到当前算的点是第几个,放进什么地方。C++中如果传入参数数目可以小于声明时所定义的数目时取默认值。
那么这一段的意思就很好理解了,输入的每一个数都平方放进padded_Square中对应位置,比如in[0]放进padded_square第pad层的第一个位置,因为上下各延伸了pad层。在这里就是图1算完放进图2紫色的部分。

- for (int c = 0; c < size_; ++c) {//对n个通道平方求和并乘以预先算好的(alpha/n),累加至scale_中(实现计算 1 + sum_under_i(x_i^2))
- caffe_axpy<Dtype>(height_ * width_, alpha_over_size,
- padded_square_data + padded_square.offset(0, c),
- scale_data + scale_.offset(n, 0));
- }
找到caffe_axpy()的定义:caffe_axpy(int len,float alpha,float* x,float* y){for(int i=0;i<len;i++)y[i]=alpha*x+y;}
在这里,len=
height * width,意思就是每调用一次caffe_axpy这个函数算一层。所以下面以层为单位讲述,scale(0)表示
当c=0时,这段函数执行的是将scale(0)=alpha_over_size*padded_square(0),for循环执行完scale(0)=1+
alpha_over_size*[padded_square(0)+
padded_square(1)+
padded_square(2)+
padded_square(3)+
padded_square(4)]如图所示。到这儿你可能就看明白为什么scale要全部赋值为1了
到这里,
![]() 除了最后的指数项已经全部完成了。但是这只算完了scale(0),还剩下channel-1个没算呢
除了最后的指数项已经全部完成了。但是这只算完了scale(0),还剩下channel-1个没算呢
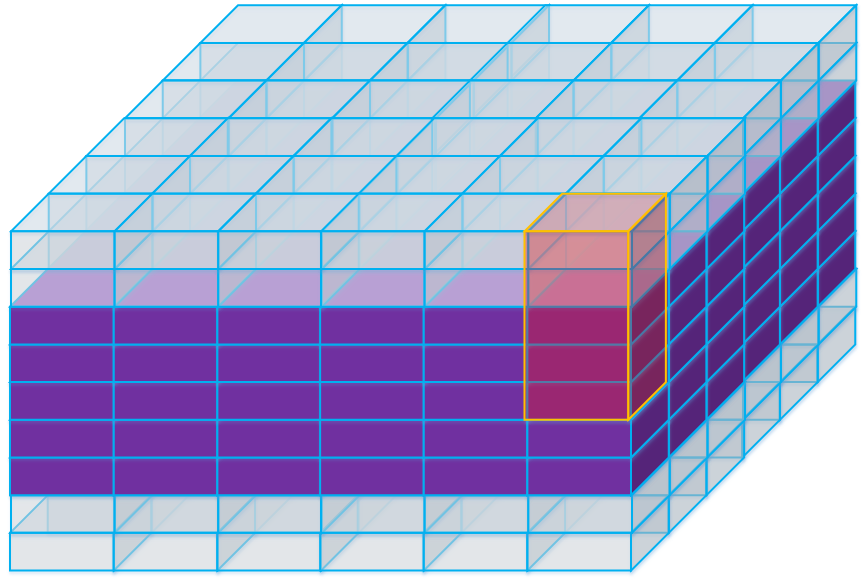
图3
- for (int c = 1; c < channels_; ++c) {//这里使用了类似FIFO的形式计算其余scale_参数,每次向后移动一个单位,加头去尾,避免重复计算求和
- // copy previous scale
- caffe_copy<Dtype>(height_ * width_,
- scale_data + scale_.offset(n, c - 1),
- scale_data + scale_.offset(n, c));
- // add head
- caffe_axpy<Dtype>(height_ * width_, alpha_over_size,
- padded_square_data + padded_square.offset(0, c + size_ - 1),
- scale_data + scale_.offset(n, c));
- // subtract tail
- caffe_axpy<Dtype>(height_ * width_, -alpha_over_size,
- padded_square_data + padded_square.offset(0, c - 1),
- scale_data + scale_.offset(n, c));
- }
- }
现在开始计算后面那些层:
首先scale(1)=scale(0)=
scale(0)=1+
alpha_over_size*[padded_square(0)+
padded_square(1)+
padded_square(2)+
padded_square(3)+
padded_square(4)]
然后scale(1)=scale(1)+pad(5)=
1+
alpha_over_size*[pad(0)+
pad(1)+
pad(2)+
pad(3)+
pad(4)+pad(5)]
如图4所展示

图4
最后要把scale(1)多算的那一层pad(0)给去掉,scale(1)=
1+
alpha_over_size*[
pad(1)+
pad(2)+
pad(3)+
pad(4)+pad(5)]
------------------------------------------------------------------------------------------------------------------------------------------
- caffe_powx<Dtype>(scale_.count(), scale_data, -beta_, top_data);//计算求指数,将除法转换为乘法,故指数变负
- caffe_mul<Dtype>(scale_.count(), top_data, bottom_data, top_data);//bottom .* scale_-> top最后输出结果















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









