







Title:Observation-Centric SORT:Rethinking SORT for Robust Multi-Object Tracking 以观察为中心的SORT:重新思考针对鲁棒的多目标跟踪的SORT
paper: OC-SORT: arxiv.org/pdf/2203.14360v2.pdf SORT: 1602.00763.pdf] (arxiv.org)
目录
Rethink the Limitations of SORT
2.Temporal Error Magnification
Abstract
问题:
1.基于Kalman filter (KF)的多目标跟踪(MOT)方法假设目标呈线性移动。虽然这种假设对于非常短的闭塞时间是可以接受的,但对长时间运动的线性估计可能是非常不准确的。
2.当没有测量值可以更新卡尔曼滤波参数时,标准的约定是信任先验状态估计来进行后验更新。这导致了在一段闭塞期间错误的积累。在实际应用中,该误差导致了显著的运动方向差异。
工作:
1.我们证明了一个基本的卡尔曼滤波器仍然可以获得最先进的跟踪性能,如果采取适当的注意来修复在遮挡期间积累的噪声。
2.我们不仅仅依赖于线性状态估计(即以估计为中心的方法),而是使用对象观测(即目标检测器的测量)来计算遮挡周期内的虚拟轨迹,以固定滤波器参数的误差积累。这允许更多的时间步长来纠正在遮挡期间积累的错误。
3.特点:Simple, Online, and Real-Time,提高了在遮挡和非线性运动时的鲁棒性。
4.给定现成的检测作为输入,OC-SORT在单个CPU上以700+ FPS运行。
5.数据集:MOT17、MOT20、KITTI、head tracking,特别是物体运动高度非线性的DanceTrack。
Introduction
目标:开发一种基于运动模型的多目标跟踪(MOT)方法,该方法对遮挡和非线性运动具有鲁棒性.
线性运动假设:跟踪目标在一个时间间隔内具有恒定的速度
motivated:从基于运动模型的跟踪方法的大多数误差发生在遮挡和非线性运动同时发生的时候。为了减轻所造成的不利影响,我们首先重新考虑当前的运动模型,并认识到一些局限性。然后我们提出解决它们的更鲁棒的跟踪性能,特别是在遮挡。
1.three limitations of SORT:
1.虽然高帧率是将物体运动近似为线性的关键,但它也放大了模型对状态估计噪声的敏感性
2.KF的状态估计噪声在KF的更新阶段,随着没有观测结果的时间而累积。
3.随着现代检测器的发展,通过检测得到的目标状态通常比滤波器中通过固定转移函数沿时间步长传播的状态估计的方差更小。SORT的设计目的是通过状态估计而不是观察来延长物体的轨迹。
2.two main innovations:
1.除了传统的预测和更新阶段外,我们还增加了一个重新更新的阶段来纠正累积的误差.
2.提出了一种以观察为中心的方法,将轨迹的方向一致性纳入关联的成本矩阵中,将其命名为观测中心动量(OCM).
OCO-SORT(简单,在线,实时,显著提高了对遮挡和非线性运动的鲁棒性)
3.contributions:
1.我们从分析和经验上认识到SORT的三个局限性,即对状态估计噪声的敏感性、随时间变化的误差积累以及以估计为中心;
2.通过修正SORT的局限性,我们提出了OC-SORT在遮挡和非线性运动下的跟踪方法。它以在线和实时的方式在多个数据集上实现了最先进的性能。
Ralated Works
1.Motion Models
许多现代的MOT算法都使用运动模型。通常,这些运动模型使用贝叶斯估计来通过最大化后验估计来预测下一个状态。作为最经典的运动模型之一,卡尔曼滤波器(KF)是一个递归贝叶斯滤波器,遵循一个典型的预测-更新周期。假设真实状态是一个未观察到的马尔可夫过程,测量是从一个隐藏的马尔可夫模型观察。鉴于线性运动假设限制了KF,提出了扩展KF 和无香味KF 等用一阶和三阶泰勒近似处理非线性运动的后续工作。然而,它们仍然依赖于KF假设的高斯先验,并需要运动模式假设。另一方面,粒子滤波器通过基于采样的后验估计来求解非线性运动,但需要指数级计算。因此,这些卡尔曼滤波和粒子滤波在视觉多目标跟踪中很少采用,大多数采用的运动模型仍然基于卡尔曼滤波。
2.Multi-object Tracking
视觉多目标跟踪作为一种经典的计算机视觉任务,传统上是从概率的角度来处理的,例如联合概率关联。现代视频目标跟踪通常是建立在现代目标探测器上。SORT [3]采用卡尔曼滤波器对深度探测器的观测结果进行基于运动的多目标跟踪。DeepSORT在SORT的框架下,进一步将深度视觉特征引入到对象关联中。从那时起,基于再识别的物体关联也变得流行起来,但当场景拥挤、物体表示粗糙(例如被边界框包围)或物体外观无法区分时,它就不够用了。最近,transformer被引入MOT,从视觉信息和物体轨迹中学习深度表示。然而,在准确性和时间效率方面,它们的性能在最先进的逐次跟踪检测方法之间仍然有显著的差距。
Rethink the Limitations of SORT
1.Preliminaries
1.Kalman filter (KF):卡尔曼滤波器(KF)是在时域离散的动力系统的线性估计器。KF只需要对上一个时间步长的状态估计和当前测量来估计下一个时间步长的目标状态。滤波器维护两个变量,后验状态估计x,和后验估计协方差矩阵P.对象跟踪的任务,我们描述KF过程与状态转换模型F,观测模型H,过程噪声Q和观察噪声R在每一步t,给定观察zt,KF工作在一个交替的预测和更新阶段:

预测的阶段是推导出下一个时间步t的状态估计。给定下一步t的目标状态的测量,更新阶段的目的是更新KF中的后验参数。由于测量来自于观测模型H,因此在许多情况下也被称为“观测”。
2.SORT:SORT是一个构建在KF基础上的多对象跟踪器。在SORT中,KF的状态x被定义为x = [u,v,s,r,˙u,˙v,˙s]⊤,其中(u,v)是图像中对象中心的二维坐标。s是边界框比例(面积),r是边界框高宽比。假设长宽比r是常数。其他三个变量˙u、˙v和˙s都是相应的时间导数。观测结果为边界框z = [u、v、w、h,c]⊤,分别具有物体中心位置(u,v)、物体宽度w、高度h和检测置信度c。SORT假设线性运动为过渡模型F,这导致状态估计为
![]()
为了利用SORT中的KF(Eq 1)进行视觉MOT,预测阶段对应于估计下一个视频帧上的目标位置。更新阶段的观察结果通常来自检测模型。更新阶段是更新卡尔曼滤波器的参数,而不直接编辑跟踪结果。
当过渡过程中两步之间的时间差恒定时,例如视频帧率恒定时,我们可以设置∆t=1。当视频帧率较高时,即使物体的运动是全局非线性的(如舞蹈、击剑、摔跤),SORT也能很好地工作,因为目标物体的运动可以在短时间间隔内很好地近似为线性。然而,在实践中,在一些时间步长上经常没有观测结果,例如目标对象在多目标跟踪中被遮挡。在这种情况下,我们不能像在等式中那样通过更新操作来更新KF参数1了。SORT直接使用先验估计作为后验估计。我们称之为“虚拟更新”
![]()
这种设计背后的哲学是,在没有观察结果来监督它们的情况下信任估计。因此,我们称遵循该方案的跟踪算法为“以估计为中心的”。然而,我们将看到,当非线性运动和遮挡同时发生时,这种以估计为中心的机制可能会造成麻烦。
2.Limitations of SORT
1.Sensitive to State Noise
现在我们证明了SORT对来自KF的状态估计的噪声是敏感的。首先,我们假设估计的物体中心位置遵循u∼N(µu,σ2u)和v∼N(µv,σ2v),其中(µu,µv)是潜在的真实位置。然后,如果我们假设状态噪声独立于不同的步骤,通过等式2,两个时间步长之间的对象速度,t→t+∆t,为

使估计速度δ˙u∼N(0,2σ2u/(∆t)^2),δ˙v∼N(0,2σ2v/(∆t)^2)的噪声。因此,一个小的∆t会放大噪声。这表明SORT在高帧率视频中会受到速度估计的大噪声的影响。以上分析是从现实简化的。在实践中,速度不会由未来时间步长上的状态来决定。有关更严格的分析,请参见附录G。
此外,对于大多数多目标跟踪场景,目标对象位移在连续帧之间只有几个像素。例如,MOT17 [41]训练数据集沿图像宽度和高度的平均位移分别为1.93像素和0.65像素。在这种情况下,即使估计的位置只有一个像素的位移,它也会导致估计的速度的显著变化。一般来说,速度估计的方差可以与速度本身的大小相同,甚至更大。这不会产生巨大的影响,因为移动只有几个像素来自下一个时间步长的地面真像和观测值,其方差与时间无关,将能够在更新后验参数时修正噪声。然而,我们发现,在没有观察到KF更新时,被多个时间步长的误差累积放大,如此高的对状态噪声的高灵敏度在实践中带来了重要的问题。
2.Temporal Error Magnification
在等式4中进行上述分析,我们假设对象状态的噪声在不同的时间步长上是i.i.d的(这是一个简化的版本,在附录G中提供了更详细的分析)。这对于物体检测是合理的,但对于来自KF的估计则不是。这是因为KF的估计总是依赖于它对之前的时间步长的估计。这种影响通常很小,因为KF可以在更新中使用观察来防止后验状态估计和协方差,即ˆxt|t和Pt|t,偏离真实值太远。但是,当没有向KF提供观测数据时,它就不能使用观测数据来更新其参数。然后它必须跟随等式3.将估计的运动轨迹延长到下一个时间步长。考虑一个轨道在t和t + T之间的时间步长上被遮挡,速度估计的噪声遵循δ˙ut∼N(0,2σ 2 u),δ˙vt∼N(0,2σ 2 v)。在步骤t + T上,状态估计将为
![]()
其噪声遵循δut+T∼N(0,2T 2σ 2 u)和δvt+T∼N(0,2T 2σ 2 v)。因此,在没有观测的情况下,KF线性运动假设的估计导致了随时间的快速误差积累。假设σv和σu与连续帧之间的物体位移大小相同,最终物体位置的噪声(ut+T,vt+T)的大小与物体的大小相同。例如,在MOT17上,靠近摄像头的行人的大小约为50×300像素。因此,即使假设位置估计的方差只有1个像素,10帧的遮挡也可以在最终的位置估计中积累一个与物体大小一样大的位移。当场景拥挤时,这种错误放大会导致大量的错误积累。
3.Estimation-Centric
上述限制来自于SORT的一个基本属性,即它遵循KF是以估计为中心的。它允许在不存在观察结果的情况下进行更新,并且完全信任估计结果。状态估计和观测之间的一个关键区别是,我们可以假设每一帧中的物体探测器的观测都受到i.i.d.的影响噪声δz∼N(0,σ‘2),而状态估计中的噪声可以沿着马尔可夫过程累积。此外,现代的物体检测器使用了强大的物体视觉特征。这使得即使在一帧上,通常假设σ‘<σu和σ’<σv也是安全的,因为通过检测得到的目标定位比通过线性运动假设得到的状态估计更准确。结合前面提到的两个限制,以估计为中心会使SORT在有遮挡和物体运动不是完全线性时遭受严重的噪声。
4.Observation-Centric SORT
为了解决SORT的局限性,使用对象进入关联阶段的动量,并开发一个pipline对遮挡和非线性运动具有更小的噪声和鲁棒性。关键是要将跟踪器设计为以观察为中心,而不是以估计为中心。如果跟踪从未跟踪中恢复,我们将使用以观察为中心的重新更新(ORU)策略来抵消在未跟踪期间累积的错误。OCSORT还在关联成本中增加了一个观察中心动量(OCM)项。OC-SORT的伪代码参见附录中的算法1。
管道布置图:
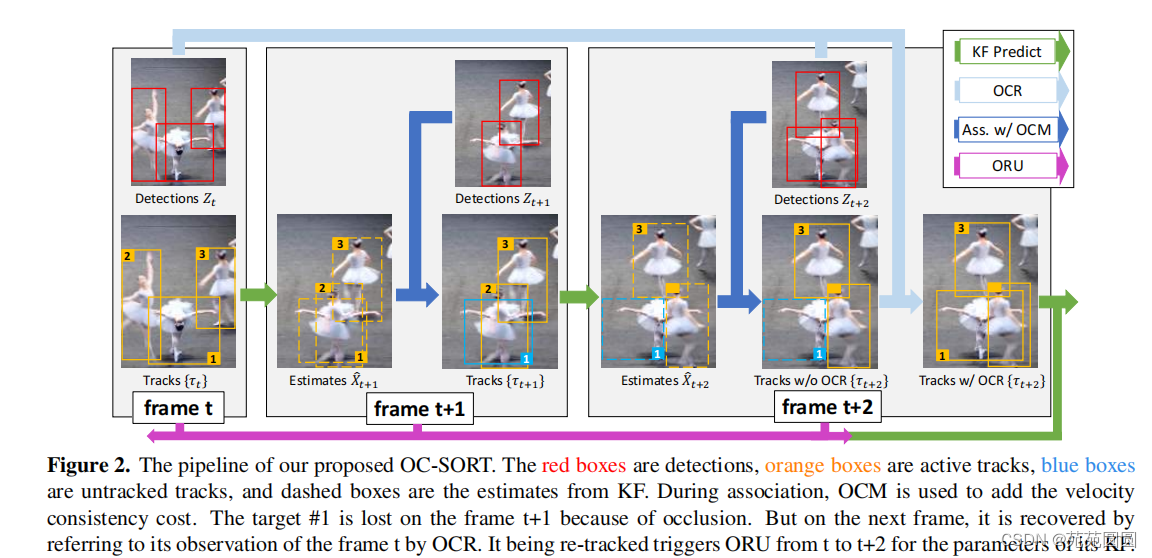
红色:检测,橙色:活动的轨道,蓝色:未跟踪的轨道,虚线框:来自KF的估计。
在关联过程中,OCM用于添加速度一致性成本。目标#1在帧t+1上丢失。但在下一帧中,通过OCR对帧t的观察来恢复。它被重新跟踪触发ORU从t到t+2的KF参数。
1.Observation-centric Re-Update (ORU)
In practice,即使一个对象在一段时间的未跟踪后再次被SORT关联,它也可能再次丢失,因为它的KF参数由于时间误差放大已经偏离了正确值。为了缓解这个问题,我们提出了以观测为中心的重新更新(ORU)来减少累积的误差。一旦轨迹在一段时间不跟踪(“重新激活”)后再次与观察相关联,我们就反向检查它丢失的周期,并重新更新KF的参数。这次重新更新是基于对虚拟轨迹的“观测”。虚拟轨迹是根据对开始和结束未跟踪周期的步骤的观察结果生成的。例如,将未跟踪之前的最后一次观测表示为zt1,将触发重新关联的观测表示为zt2,将虚拟轨迹表示为
![]()
然后,沿着˜zt(t1<t<t2)的轨迹,我们运行预测和重新更新的循环。重新更新操作为

由于对虚拟轨迹的观测结果与最后看到的和最新的经过真实观察套索所锚定的运动模式相匹配,更新将不再受到通过虚拟更新累积的错误的影响。我们称之为以过程观察为中心的重新更新。它作为预测-更新循环之外的一个独立阶段,只有一个轨道从一个没有观察的时期被重新激活。
2.Observation-Centric Momentum (OCM)
在一个相当短的时间间隔内,我们可以将运动近似为线性的。而线性运动假设也要求有一致的运动方向。但噪音阻止了我们利用方向的一致性。准确地说,为了确定运动方向,我们需要两步时间差∆的物体状态。如果∆t很小,由于估计对状态噪声的敏感性,速度噪声会显著。当∆t较大时,由于时间误差放大和线性运动假设的失败,方向估计的噪声也会显著。由于状态观测没有状态估计所存在的时间误差放大问题,我们建议使用观测而不是估计来减少运动方向计算的噪声,并引入速度一致性项来帮助关联。
利用新项,给定N个现有轨迹和M个检测点,将关联成本矩阵表示为
![]()
其中,ˆX∈RN×7是目标状态估计的集合,Z∈RM×5是对新时间步长的观测集。λ是一个加权因子。Z包含了所有现有轨迹的观测轨迹。CIoU(·,·)计算负成对IoU(Union的交叉点),Cv(·,·)计算i)方向之间的一致性,连接现有轨道上的两个观测(θ轨迹)和ii)连接轨道的历史观测和新观测之间的一致性(θ意图)。Cv包含所有对∆θ=|θ跟踪−θ意图|。在我们的实现中,我们以弧度计算运动方向,即θ=arctan(v1−v2u1−u2),其中(u1,v1)和(u2,v2)是在两个不同时间步长上的观测值。该计算结果如图4所示。

在OCM中,运动方向差的计算。绿线表示现有的轨道,点是它上面的观测结果。红点是需要相关的新观测结果。蓝色链接和黄色链接分别构成了θ轨道和θ意图的方向。夹角为方向∆θ的差值。
根据前面提到的噪声分布假设,我们可以推导出方向估计中噪声分布的封闭概率密度函数。通过分析该分布的性质,我们得出结论,在线性运动模型下,方向估计值的噪声尺度与两个观测点之间的时间差呈负相关,即∆t。这表明通过增加∆t来实现θ的低噪声估计。然而,线性运动的假设通常只适用于∆t足够小的情况。因此,选择∆t需要一个权衡。
除了ORU和OCM,我们还发现,检查一个轨道的最后存在以恢复它从丢失。因此,我们应用了一种启发式的Observation-Centric Recovery (OCR)technique。OCR将开始第二次尝试,将通常关联阶段后的最后一次观测与未匹配的观测进行关联。它可以处理一个物体停止或被短时间间隔阻塞的情况。
Experiments
1.Expeimental Setup实验装置
(1)Datasets(数据集):MOT17 、MOT20 、KITTI 、DanceTrack 和CroHD
(2)Implementations(实现):应用现有基线中的对象检测
(3)Metrics(指标):HOTA(主要指标)、AssA(关联性能)、IDF1(关联性能)、MOTA(检测性能)
MOTA(↑): 多目标跟踪精度
MOTP(↑): 多目标跟踪精度
FAF(↓):每帧的误报数。
MT(↑):大部分跟踪轨迹的数量。也就是说,目标至少80%的寿命具有相同的标签。
ML(↓):大部分丢失的轨迹的数量。也就是说,目标至少有20%的寿命没有被跟踪。
FP(↓):错误检测的次数。
FN(↓):漏检检测次数。
IDsw(↓):一个ID切换到之前跟踪的不同对象的次数。
Frag(↓):轨道被错过检测中断的碎片数
使用(↑)进行评价时,得分越高表示表现越好;而对于使用(↓)的评价指标,得分越低表示表现越好。真阳性被认为与相应的地面真实边界框至少有50%的重叠。
2.Benchmark Results

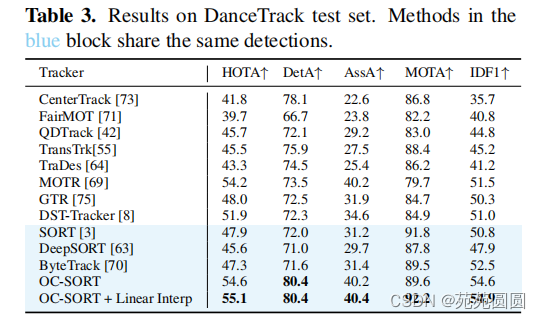

3.Ablation Study(消融实验)

1.Component Ablation:ORU在MOT17和DanceTrack两个数据集上的性能提高都是显著的,但OCM仅在物体运动更复杂、遮挡更严重的舞蹈跟踪数据集上有显著的帮助。消融研究证明了我们提出的方法在提高遮挡和非线性运动的跟踪鲁棒性方面的有效性
2.Virtual Trajectory in ORU:线性回归(LR)或高斯过程回归(GPR)和近恒定加速度模型(NCAM)
3.∆t in OCM:在OCM中选择时差∆t时,有一个权衡。一个较大的∆t降低了速度估计的噪声。但也可能会阻止将物体运动近似为线性运动。从∆t=1中增加∆t可以提高性能。但是增加∆t高于最佳实践值,反而会影响性能,因为很难保持线性运动的近似值。
















 7377
7377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











