






相关工作
reflective loss层来检测网络CNN网络性能优劣
新网络来代替WTA
1.新网络结构, 多层多尺度控制网络的接受域
2.通过hybrid loss来训练网络获得更好的网络结构性能
3.通过CNN得到视差图而不是先前的WTA,
4.通过reflective来测量CNN输出准确性
5.如何利用confidence score更好的检测异常点并且进行修正
6.性能和速度有了很大的进步
第一,引入了很牛逼的lamda系数。使得网络适应了添加的链接。
第二,添加尺度层控制网络的接受域。
第三,添加常数skip链接
1.本文不光得到准确的视差图还得到置信度得分
2.以reflective loss不光取决于ground truth,而且还基于训练时候预测的标签
3.在SGM步骤中使用confidence步骤可以提升SGM的性能,也可以在视差图修正过程中引入该策略
4.本文方法不限制于立体匹配。
residual networks (ResNets)是以skip connections链接的神经网络。是Highway Networks的特例。resnet代表着共享权值集合的力量。有了skip connections它能够训练非常深的网络。
3.计算匹配成本
第一步就是在每个位置上都进行匹配成本计算。从左右两图开始,左图中的每个位置p和视差d,都计算左右两图的匹配成本。成本在3D位置中心上更小。
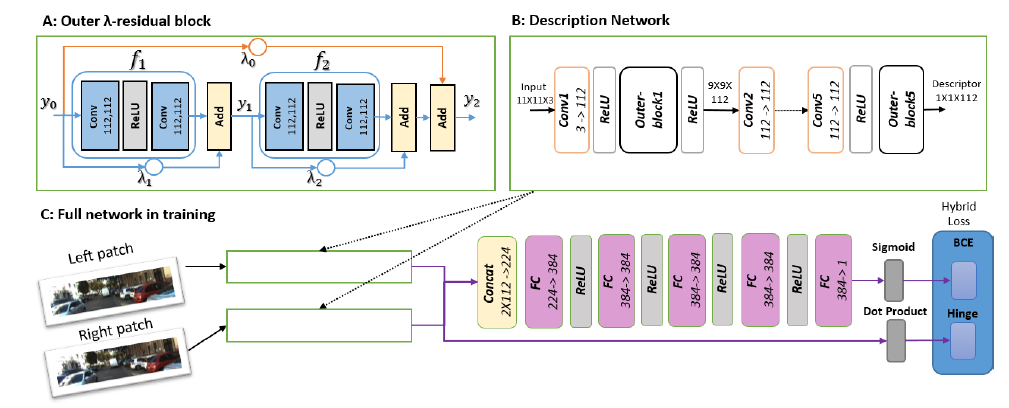
网络由如下几个部分组成:outer lamda-residual block,这个快后面详细介绍, 两个inner lambda residual blocks组成了一个outer lambda-residual block。 description networks即五个scaling层间隔outer blocks块, 输出有两部分,第一部分是两代表统一成单向量,以cross-entropy loss来训练,第二部分直接表示两个代表输出点乘的hinge loss。 匹配成本C(p,d)可由决策子网络中传输的UL和UR来计算。有的网络通过full decision网络或者通过点乘相似性得分得到最终结果,本文将会结合二者。
3.1 inner-outer residual blocks
研究称五六层的网络比四层的结构好,因此通过添加skip connections和residual blocks来加深网络层数,
堆叠residual blocks将会对网络收敛造成困难同时也不利于预测,因此,通过引入skip connections和连接两个inner residual blocks的方式来加深网络,skipconnection是有利于网络收敛的。池化层和BN层降低分辨率对匹配网络无益因此舍去。
这种相加能力即提速又提质量。对卷积结构带来了独特的视野,它可以更好的处理颜色信息(supplementary)?
3.2 constant highway skip connection
这个就是连接residual blocks的方式。lambda权衡控制各自的输出,residual 网络的输出就是各种可能的路径加权集合。至于高层权重小,这样有利于减小网络偏差(supplementary有介绍)
3.3 hybrid loss
为了进一步提升descriptor网络区分块匹配与否的能力。同时使得descriptor不至于那么繁琐,因此结合两个loss:一个是点乘的hinge loss 还有一个是decision网络输出的cross-entropy loss。以alpha来权衡两个损失。点乘表示一种相似性得分。
4.计算视差图像
匹配成本的计算引入映射C(p,d),这个映射尺寸大小为H×W×disparity_max。每个位置都对可能产生的视差进行计算,下一步输出大小H×W的视差图D(p)。
现在的立体匹配算法使用较少的后处理步骤,“Winner takes all”(WTA)D(p)=argmindC(p,d)。后处理还是需要的,因为一个匹配算法,想要具有竞争力,就需要整合领域像素的信息而非简简单单的最大化。cross-based cost aggregation(CBCA)方法应运而生,结合领域像素的信息,平均它们的成本,这样有效抑制了深度断裂,接着semi global matching(SGM)强制平滑视差图,也让成本聚合的迭代次数更少。
虽然CBCA和SGM很牛叉,但是它们对于透明,反射,高亮区域束手无策。比如对于车玻璃这些方法就歇菜。
为了克服这样的挑战,object-category 视差方法站了出来,这需要充分利用物体的先验知识以及图像语义分割,两个原因取消这个:引入了计算复杂度和特殊物体形状所带来的损失。然而,我们采用全局视差卷积神经网络来代替WTA方法。前向传播这个整个matching cost map,得到每个位置的视差输出。这个网络以新颖的reflective loss来训练,并且在网络视差预测的同时产生一个置信度的测量,为之后的refinement过程埋下了伏笔。

4.1 global disparity network
用来训练视差网络的数据由经过匹配成本网络训练处理的图像组成。对于每个左右图像对,在每个可能的视差距离上都进行全图大小的匹配成本计算。接着采用CBCA和SGM。记住了,匹配网络只反馈出单独可能的估计,如果仅用CBCA和SGM,输出的值可能为负,同时没有限定在一定范围之内。因此采用Tanh使得值在固定的【-1,1】范围之内。每个匹配成本块的目标(ground truth)值是它中心像素的视差值。
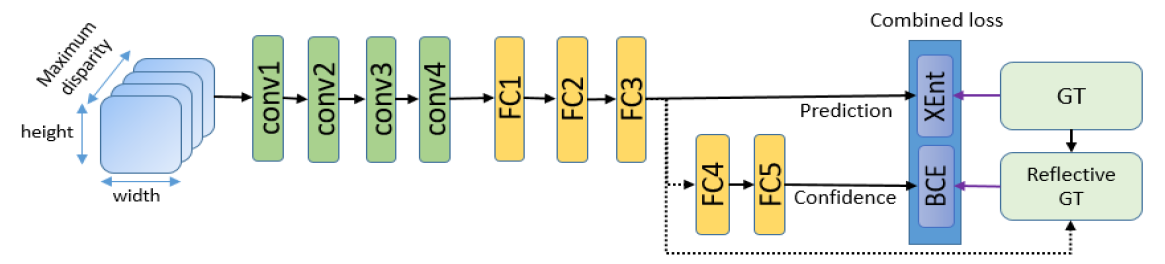
输入global disparity network(GDN)的块如上图所描述。两个输出层:FC3输出向量y是每个视差d的得分。FC5表示某个预测的置信度c。FC3的loss函数是带权重的cross-entropy loss 。所以这一部分输出是一个视差的得分而不是只输出视差。其实这个输出就是类似于softmax输出。
4.2 reflective confidence
为了从disparity网络中得到置信度测量,同时通过二分类cross-entropy loss训练一个二元分类器。该分类器由两个全连接网络构成。loss的训练标签反应出得分向量y的正确率。同时作为分类器的输入,每个前向传输过后,argmaxi yi与ground truth的视差yGT做比较,如果预测正确,即比如与真值相差小于1个像素,那么这个例子可以看成正样本,否则是负样本。
损失是非常规的,因为这个不光与真值有关,还与网络的激励有关。样本标签在训练的过程中是动态改变的。
5.disparity refinement
全局视差网络已经对预测视差图做了极大的贡献,仍存在深度缺损和异常像素预测等一系列的问题。最后这部分就是对于最终的预测输出做出refine修正。修正三步骤就是:1)左右一致性确认结合置信度得分在异常点上。2)为了增加图像分辨率进行亚像素增强,3)加入中值滤波和双边滤波来平滑视差图。
读后感:
1.不知这种lambda-residual block作为description网络的组成部分有何特殊之处,引入了skipconnection,这样的结构是否比传统的方法在提取特征上面更加有效?
2.flonet当中的matching cost直接是两个特征图进行卷积得到的。本文又是如何得到的?通过网络哦。
3.FC3输出就时类似于softmax。输出各种视差位置的可能得分。
4.FC5就是SVM,看上面的预测是否正确。预测与真值的差异大否形成了正负样本,两个全连接层搭建了SVM。
5.说了半天,这个网络还是得要refinement啊。达不到end-to-end的标准啊。
代码如下
https://github.com/amitshaked/resmatch
lua语言写的,torch。训练机在跑caffe,最近试不了。















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









