









1,下载TIMIT语料库,解压,全部目录,文件变小写,按照NLTK要求,修改所有根目录下的.txt配置文件
2,安装必要python库:nltk, librosa,numpy,catboost
3, 实现训练过程,原理:TIMIT中wav格式并非标准RIFF格式,好在格式简单,每个文件头占1024字节,文本格式,剩下的是pcm raw data,录制格式是单声道,16bit 16KHz,按照数据格式直接填入numpy.array里面,然后交由librosa,提取MFCC以及MFCC delta特征,做为训练输入数据,同时分析同名的phn文件,生成对应的训练标签。
import nltk
from nltk.corpus import timit
import numpy as np
import librosa
import os
from catboost import CatBoostClassifier
def exactFeature(phones, item):
wavfile = "{}/{}.wav".format(timit._root, item)
"""
se_version -s3 1.0
utterance_id -s10 aks0_sx133
channel_count -i 1
sample_count -i 53044
sample_rate -i 16000
sample_min -i -3305
sample_max -i 3700
sample_n_bytes -i 2
sample_byte_format -s2 01
sample_sig_bits -i 16
end_head
"""
f = open(wavfile, "rb")
f.seek(1024, os.SEEK_SET)
d = np.fromfile(f, dtype=np.int16).astype(np.float32)
sr = 16000
mfccs = librosa.feature.mfcc(d, sr, n_mfcc=13, hop_length=int(0.010*sr), n_fft=int(0.025*sr))
mfccs[0] = librosa.feature.rmse(d, hop_length=int(0.010*sr), n_fft=int(0.025*sr))
deltas = librosa.feature.delta(mfccs)
mfccs_plus_deltas = np.vstack([mfccs, deltas])
dataset=np.flipud(np.rot90(mfccs_plus_deltas))
curpos=0
train_labels=[]
for v in timit.phone_times(item):
while v[2]>curpos:
train_labels.append(phones.index(v[0]))
curpos+=0.010*sr
train_labels.insert(0,train_labels[0])
for ind in xrange(len(train_labels),dataset.shape[0]):
train_labels.append(phones.index(v[0]))
train_labels = train_labels[:dataset.shape[0]]
return dataset,train_labels
phones=list(set(timit.phones()))
alldataset=np.array([])
alltrain_lab=[]
for item in timit.utteranceids():
dataset,train_labels=exactFeature(phones,item)
if alldataset.shape[0]==0:
alldataset = dataset
else:
alldataset=np.concatenate((alldataset, dataset))
alltrain_lab.extend(train_labels)
if alldataset.shape[0] != len(alltrain_lab):
print "feature no match!!!", dataset.shape, len(train_labels), alldataset.shape, len(alltrain_lab)
break
model = CatBoostClassifier(learning_rate=0.1, depth=12, loss_function='MultiClass')
fit_model = model.fit(alldataset, alltrain_lab)
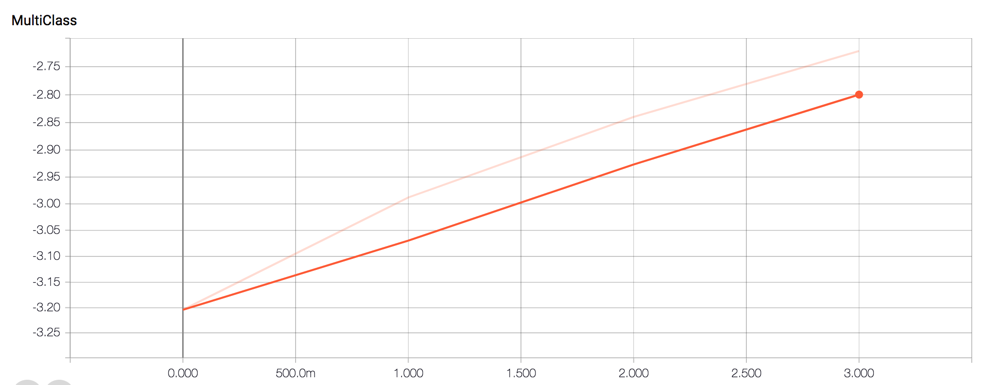
print fit_model.get_params()4, 样本数量:1941232,在单台centos虚拟机上,纯cpu训练过程不超过1小时,的确非常高效
训练过程如下:















 2636
2636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









