






IJCV 2025 | 基于语义协同学习的水下感知级增强
题目: HUPE: Heuristic Underwater Perceptual Enhancement with Semantic Collaborative Learning
作者: Zengxi Zhang, Zhiying Jiang, Long Ma, Jinyuan Liu, Xin Fan, and Risheng Liu
源码: https://github.com/ZengxiZhang/HUPE
🔑 1. 论文创新点
- 提出了信息保持的归一化网络: 我们将其引入水下图像增强任务,实现了退化图像与清晰图像之间的可逆映射,确保增强过程无损关键场景信息。
- 将启发式先验嵌入数据驱动网络: 通过将启发式先验知识嵌入数据驱动映射过程,增强框架的可解释性,显著提升方法在复杂真实水下场景中的鲁棒性。
- 为后续感知应用设计语义协作学习模块: 提出特征级语义协作学习机制,在生成视觉友好的增强图像同时,协同提取高层语义信息,为下游感知任务提供可靠支持。
🌍 2. 摘要
水下图像常因光线折射与吸收导致能见度下降,影响后续应用。现有水下图像增强方法多聚焦于视觉质量提升,却忽视实际应用需求。为平衡视觉质量与应用适配性,我们提出一种启发式可逆水下感知增强网络(HUPE),该网络在提升视觉质量的同时,展现出处理下游任务的高度灵活性。具体而言,我们设计了嵌入傅里叶变换的信息保持可逆映射机制,建立水下图像与清晰图像间的双向转换关系,并通过引入启发式先验优化增强过程以更精准捕捉场景信息。为进一步弥合视觉增强图像与应用导向图像间的特征鸿沟,我们在视觉增强任务与下游任务的联合优化中采用语义协作学习模块,引导增强模型在生成高视觉质量图像的同时提取更具任务导向性的语义特征。大量定性与定量实验表明,HUPE在恢复精度与任务适配性上均显著优于现有前沿方法。
🛠 3. 方法
传统基于学习的增强网络往往在增强过程中丢失了关键细节以及语义结构,进而影响后续感知任务的准确性与可靠性。为解决这一问题,我们首次提出启发式可逆网络(HIN),通过构建水下图像与清晰图像间的可逆转换,确保增强过程中的信息完整性。该网络嵌入频率感知仿射耦合模块,同步刻画水下图像与清晰图像在频域和空间域的内在关联。针对数据驱动网络常忽视水下场景物理特性、导致复杂环境适应性不足的缺陷,我们进一步将物理模型相关的深度与梯度信息编码为启发式先验融入可逆网络,从而在降低对大规模训练数据依赖的同时,显著提升增强网络在多样化水下环境中的鲁棒性。
此外,当前水下增强方法通常仅关注视觉质量提升,却忽视感知特征的保留与强化。一个值得思考的问题是:能否缩小视觉增强任务与下游应用间的特征空间差异?为此,我们引入语义协作学习模块(SCL),通过增强网络与感知网络间的元特征嵌入,使提出的HUPE能够隐式挖掘图像深层语义信息,从而提升增强图像对下游感知任务的适配性。下文将详细阐述该模块的结构设计与训练策略。
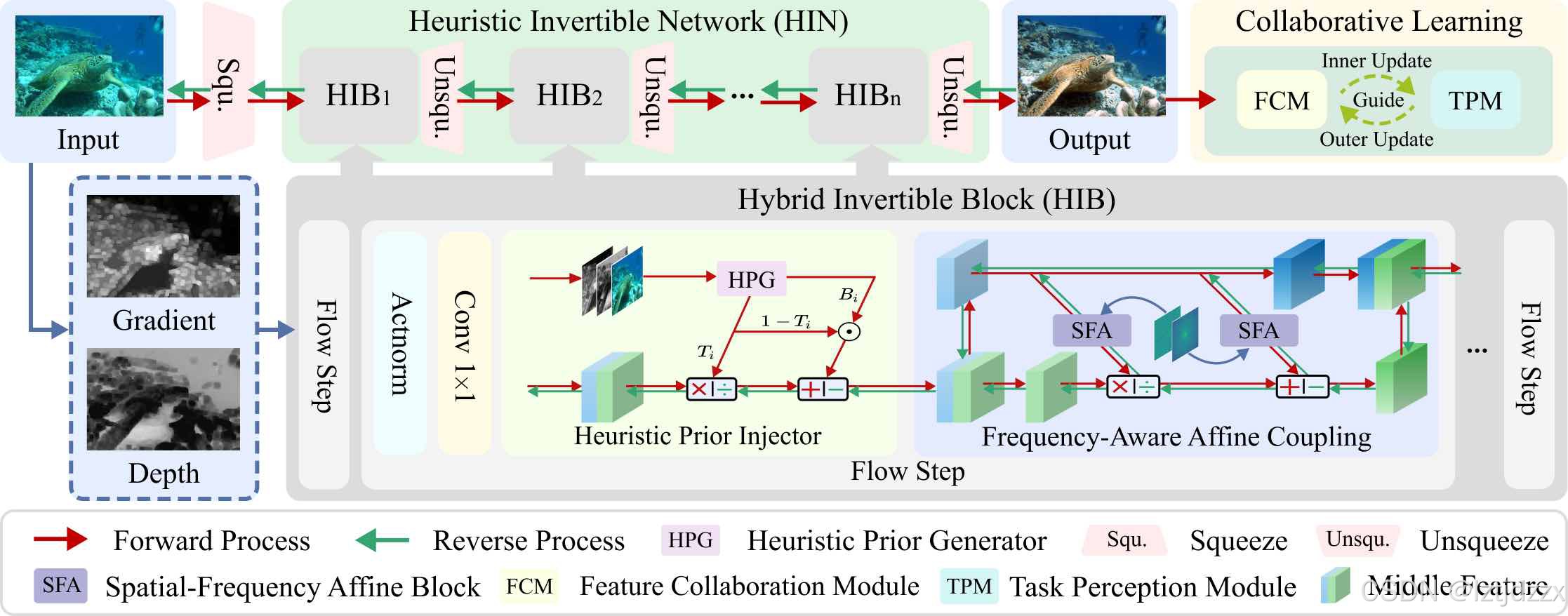
3.1 混合可逆块
上图展示了HUPE的工作流程。混合可逆块(HIB)是启发式可逆网络的核心组件,负责实现水下图像与清晰图像间的可逆转换,同时将启发式先验信息嵌入网络以增强其增强鲁棒性。正向过程中,水下图像通过由多个可逆块组成的网络转换为增强图像;反向过程中,清晰图像则通过可逆网络的逆操作重建退化图像。
HIB包含以下子模块:
Actnorm:使用逐通道的尺度与偏置参数进行仿射变换,初始基于首批数据归一化为零均值、单位方差。
可逆1×1卷积:作为通道排列操作的扩展,通过1×1卷积核改变输入通道数(保留空间维度),实现跨特征通道的线性组合。
启发式先验注入器:基于简化水下成像模型,通过物理成像参数指导网络学习水下场景特征。该物理成像模型可表述为:
J
c
(
x
)
=
1
t
(
x
)
I
c
(
x
)
+
1
t
(
x
)
B
c
(
t
(
x
)
−
1
)
,
c
∈
{
r
,
g
,
b
}
,
J^c(x) = \frac{1}{t(x)}I^c(x) + \frac{1}{t(x)}B^c(t(x)-1), c \in\{r, g, b\},
Jc(x)=t(x)1Ic(x)+t(x)1Bc(t(x)−1),c∈{r,g,b},
其中,
J
J
J表示位置
x
x
x处的增强图像,
I
I
I表示传感器捕获的水下图像。
c
c
c代表红、绿、蓝三色通道的颜色空间。𝐵表示环境光,𝑡代表介质传输系数,根据比尔-朗伯定律(Beer-Lambert Law),其可以表示为
t
(
x
)
=
e
β
d
(
x
)
t(x) = e^{\beta d(x)}
t(x)=eβd(x),其中
β
\beta
β为衰减系数,
d
(
x
)
d(x)
d(x)为场景深度。
考虑到梯度图通过估计小杂质对光散射的影响,帮助修正水下光散射引起的图像模糊。此外,深度图提供了估计水下大气光和光衰减的关键信息。我们之前通过暗通道先验的推广来估计梯度图
I
g
I_g
Ig和深度图
I
d
I_d
Id作为启发式信息。随后,我们将它们与退化图像
I
u
I_u
Iu进行拼接,并将其输入到启发式先验引导的编码器中,该编码器通过对退化图像的颜色、梯度和深度信息进行编码,逐步估计水下成像参数。编码过程可以表示为:
B
i
,
T
i
=
S
(
H
i
(
C
(
I
u
,
I
g
,
I
d
)
)
)
,
B_i,T_i =\mathcal{S}\left(\mathcal{H}_i\left(\mathcal{C}\left(I_u,I_g,I_d\right)\right)\right),
Bi,Ti=S(Hi(C(Iu,Ig,Id))),
其中,
H
\mathcal{H}
H 表示启发式先验引导的编码器。
C
\mathcal{C}
C 和
S
\mathcal{S}
S 分别表示通道级拼接和拆分操作。
T
T
T 是
t
t
t 的倒数,来自比尔-朗伯定律。在估计了
T
T
T 和
B
B
B 后,我们将它们作为启发式信息插入到HIB中。
将启发式先验嵌入到可逆网络后,所提出的方法能够更好地表征水下领域和空气领域之间的内在关系,并具有更强的泛化能力。
频率感知仿射耦合(FAAC):该方法旨在增强从输入到输出的单个流步骤的变换能力。具体操作将在第~\ref{FAAC}节中描述。
Unsqueeze/Squeeze:它可以实现可逆的特征扩展和压缩。Unsqueeze 设计用于将图像从
4
c
×
h
2
×
w
2
4c \times \frac{h}{2} \times \frac{w}{2}
4c×2h×2w 转换为
c
×
h
×
w
c \times h \times w
c×h×w。Squeeze 是 Unsqueeze 的反向操作。 在前向过程中,我们首先将输入图像从
c
×
h
×
w
c \times h \times w
c×h×w 转换为
2
N
c
×
h
2
N
×
w
2
N
2^N c \times \frac{h}{2^N} \times \frac{w}{2^N}
2Nc×2Nh×2Nw,其中
N
N
N 表示混合可逆块(Hybrid Invertible Block, HIB)的数量,然后通过 HIBs 将其逐渐转换回
c
×
h
×
w
c \times h \times w
c×h×w。反向过程是前向过程的相反操作。通过这些操作的集成,所提出的启发式可逆网络(HIN)可以实现水下图像与清晰图像之间的精确映射。
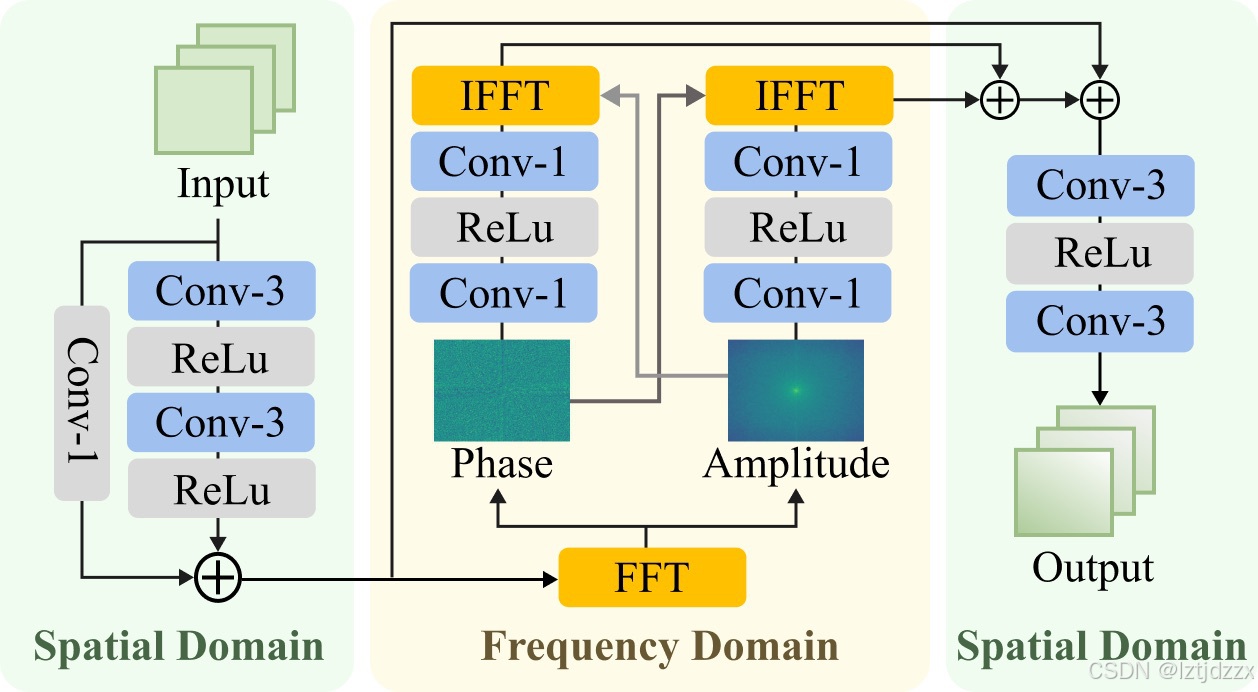
3.2 频率感知仿射耦合
仿射耦合层被用来在转换过程中进一步表达信息。与之前的仿射耦合层~\citep{li2021dehazeflow}不同,后者对频域信息的探索有限,我们应用傅里叶变换 F \mathcal{F} F 将输入从空间域转换为幅度和相位。其公式可以表示为:
u
i
+
1
1
=
u
i
1
,
\mathbf{u}^1_{i+1}=\mathbf{u}^1_i,
ui+11=ui1,
u
i
+
1
2
=
ϕ
i
(
u
i
1
,
F
)
⊙
u
i
2
+
ϕ
i
(
u
i
1
,
F
)
,
\mathbf{u}^2_{i+1}=\phi_i\left(\mathbf{u}^1_i,\mathcal{F}\right)\odot \mathbf{u}^2_i +\phi_i\left(\mathbf{u}^1_i, \mathcal{F}\right),
ui+12=ϕi(ui1,F)⊙ui2+ϕi(ui1,F),
其中,
u
i
+
1
=
C
(
u
i
+
1
1
,
u
i
+
1
2
)
\mathbf{u}{i+1} = \mathcal{C}(\mathbf{u}{i+1}^1, \mathbf{u}_{i+1}^2)
ui+1=C(ui+11,ui+12),其中
C
\mathcal{C}
C 表示特征的拼接。
i
∈
1
,
.
.
.
,
n
−
1
i \in {1,...,n-1}
i∈1,...,n−1,表示流步骤的索引。
傅里叶变换
F
\mathcal{F}
F 可以表示如下:
F
(
x
)
(
i
,
j
)
=
∑
h
=
0
H
−
1
∑
w
=
0
W
−
1
x
(
h
,
w
)
e
−
k
2
π
(
h
H
i
+
w
W
j
)
.
\mathcal{F}\left(\mathbf{x}\right)(i, j)= \sum_{h=0}^{H-1} \sum_{w=0}^{W-1} \mathbf{x}(h, w) e^{-k 2 \pi\left(\frac{h}{H} i+\frac{w}{W} j\right)} .
F(x)(i,j)=h=0∑H−1w=0∑W−1x(h,w)e−k2π(Hhi+Wwj).
频域
F
(
x
)
=
R
(
x
)
+
k
I
(
x
)
\mathcal{F}(x) = \mathcal{R}(x) + k \mathcal{I}(x)
F(x)=R(x)+kI(x),其中
I
\mathcal{I}
I 和
R
\mathcal{R}
R 分别表示虚部和实部。
ϕ
i
\phi_i
ϕi 表示空间-频率仿射块(SFA)。空间-频率仿射块的工作流程如上图所示,包含空间域和频域。我们首先通过残差块处理空间域信息,然后通过快速傅里叶变换~\citep{brigham1967fast}(FFT)从输入
x
\mathbf{x}
x 中获取相位谱
P
(
x
)
\mathcal{P}(\mathbf{x})
P(x) 和幅度谱
A
(
x
)
\mathcal{A}(\mathbf{x})
A(x),其过程可以描述为:
A
(
x
)
(
i
,
j
)
=
R
2
(
x
)
(
i
,
j
)
+
I
2
(
x
)
(
i
,
j
)
,
\mathcal{A}\left(\mathbf{x}\right)(i, j)=\sqrt{\mathcal{R}^2\left(\mathbf{x}\right)(i, j)+\mathcal{I}^2\left(\mathbf{x}\right)(i, j)},
A(x)(i,j)=R2(x)(i,j)+I2(x)(i,j),
P
(
x
)
(
i
,
j
)
=
arctan
[
I
(
x
)
(
i
,
j
)
R
(
x
)
(
i
,
j
)
]
,
\mathcal{P}\left(\mathbf{x}\right)(i, j)=\arctan \left[\frac{\mathcal{I}\left(\mathbf{x}\right)(i, j)}{\mathcal{R}\left(\mathbf{x}\right)(i, j)}\right],
P(x)(i,j)=arctan[R(x)(i,j)I(x)(i,j)],
根据傅里叶理论~\citep{xu2021fourier},相位分量
P
\mathcal{P}
P 传递图像的语义信息,而幅度分量
A
\mathcal{A}
A 显示频域中的风格信息。
为了使网络能够自适应地分别学习相位特征和幅度特征,我们将获得的两个谱输入到卷积层,并与另一个原始谱进行反向映射,转换回空间域。最后,我们将空间域的特征与三个卷积层结合,以获得输出特征。
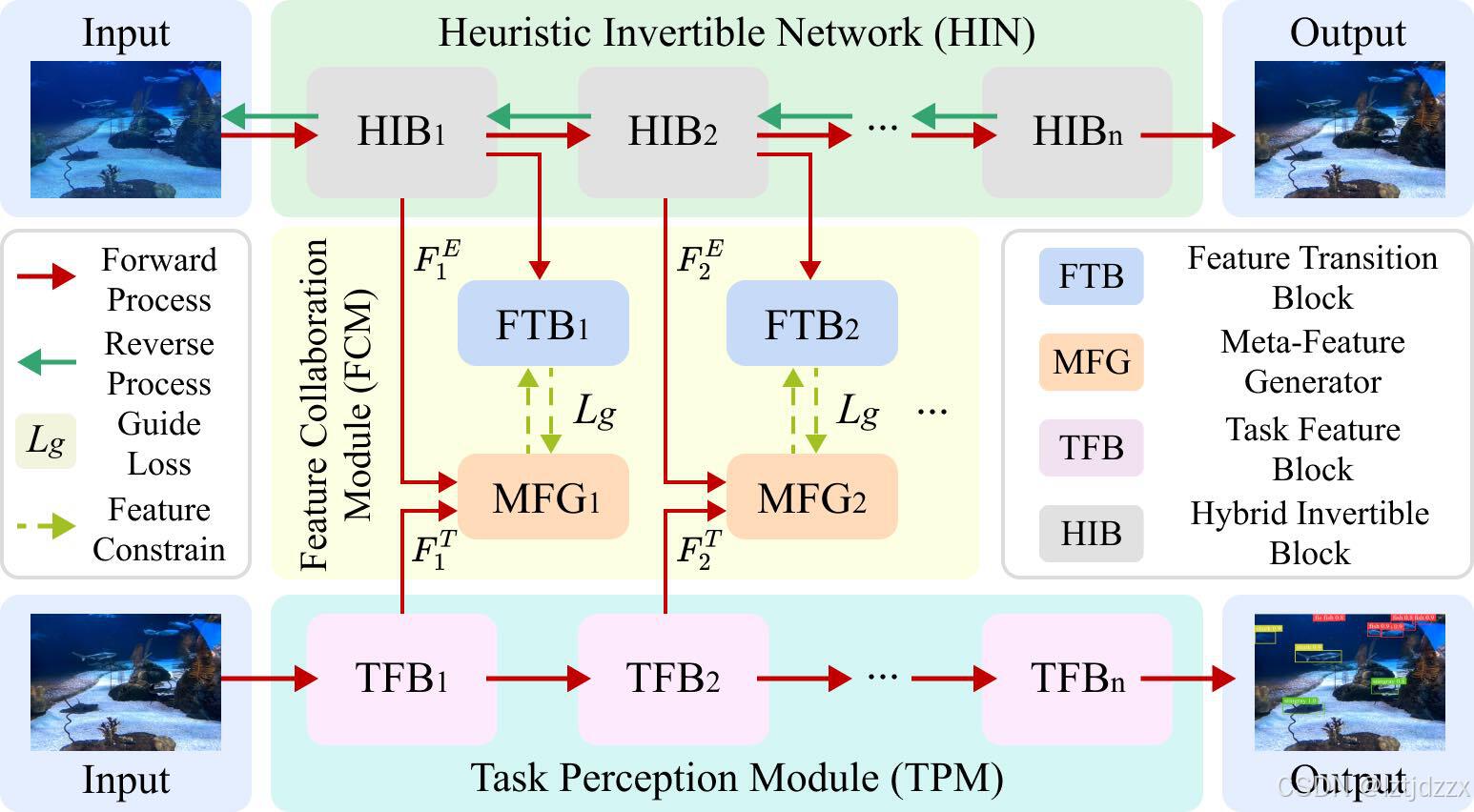
3.3 语义协同感知学习
所提出的学习模块如上图所示,包括所提出的增强网络、任务感知模块(TPM)和特征协同模块(FCM)。FCM 包括元特征生成器(MFG)和特征变换块(FTB)。MFG 根据增强网络提取语义特征的能力,从任务感知特征 F i T F^{T}_{i} FiT和增强特征 F i E F^{E}_{i} FiE中生成元特征 F i M F G F^{MFG}_{i} FiMFG。其公式可以表示为 F i M F G = M F G ( F i T , F i E ) F^{MFG}_{i}=MFG\left(F^{T}_{i}, F^{E}_{i}\right) FiMFG=MFG(FiT,FiE),其中 i i i是中间特征的索引。FTB通过特征桥接 F i F T B F^{FTB}_{i} FiFTB将元特征 F i M F G F^{MFG}_{i} FiMFG转换为增强特征 F i E F^{E}_{i} FiE。
具体来说,语义协同学习分为内部更新阶段和外部更新阶段。值得注意的是,在 FCM 的优化策略之前,增强网络和任务感知模块分别通过增强损失
L
e
\mathcal{L}_\mathrm{e}
Le
和任务损失
L
t
\mathcal{L}_\mathrm{t}
Lt进行了预训练。在内部更新阶段,我们首先通过引导损失
L
g
\mathcal{L}_\mathrm{g}
Lg
单独优化预训练的启发式可逆网络(HIN)。然后,我们使用初步优化的 HIN 计算增强损失
L
e
\mathcal{L}_\mathrm{e}
Le以更新 MFG 和 FTB 的参数。这里,
L
e
\mathcal{L}_\mathrm{e}
Le可以衡量使用元特征引导 HIN 的效果。通过联合优化 FTB 和 MFG,元特征对增强网络的引导效果得到增强。在外部更新阶段,我们进一步通过
L
g
\mathcal{L}_\mathrm{g}
Lg和
L
e
\mathcal{L}_\mathrm{e}
Le优化增强网络。
通过内部和外部阶段的交替优化,增强网络能够在生成视觉上令人满意的图像的同时,提取更多的语义特征,使其更适合后续的感知任务。
3.3 损失函数设计
在训练过程中使用了引导损失 L g \mathcal{L}_\mathrm{g} Lg、增强损失 L e \mathcal{L}_\mathrm{e} Le和任务损失约束 L t \mathcal{L}_\mathrm{t} Lt。引导损失 L g \mathcal{L}_\mathrm{g} Lg计算 F M F G F^{\mathrm{MFG}} FMFG和 F F T B F^{\mathrm{FTB}} FFTB的L2距离,这使得通过感知特征引导的增强网络能够更好地适应后续的感知任务。
我们根据过去的经验在
L
e
\mathcal{L}_\mathrm{e}
Le中应用了多种损失函数,以使增强图像更加接近空气图像。首先,在增强过程中加入了对比学习作为保真度项,以激励模型学习判别特征,最终提高其提取语义信息的能力。我们使用退化的水下捕获图像作为负样本,使用从地面场景分布中采样的增强参考图像作为正样本。对比损失函数
L
c
\mathcal{L}_\mathrm{c}
Lc可以表示为:
L
c
=
∑
i
=
1
N
ρ
i
⋅
∥
V
G
G
i
(
I
r
)
−
V
G
G
i
(
G
E
(
I
u
)
)
∥
1
∥
V
G
G
i
(
I
u
)
−
V
G
G
i
(
G
E
(
I
u
)
)
∥
1
,
\mathcal{L}_{\mathrm{c}}=\sum_{i=1}^N \rho_i \cdot \frac{\left\|\mathcal{VGG}_i(I_r)-\mathcal{VGG}_i\left(G_E(I_u)\right)\right\|_1} {\left\|\mathcal{VGG}_i(I_u)-\mathcal{VGG}_i\left(G_E(I_u)\right)\right\|_1},
Lc=i=1∑Nρi⋅∥VGGi(Iu)−VGGi(GE(Iu))∥1∥VGGi(Ir)−VGGi(GE(Iu))∥1,
其中, G E G_E GE表示所提可逆网络的正向过程, I r I_r Ir与 I u I_u Iu分别代表参考图像与水下图像。我们采用预训练的VGG19模型提取图像特征, i ∈ { 1 , 3 , 5 , 9 , 13 } i \in \{ 1, 3, 5, 9, 13\} i∈{1,3,5,9,13}表示 VGG19 的第 i 层, ρ i ∈ { 1 32 , 1 16 , 1 8 , 1 4 , 1 } \rho_i \in \{\frac{1}{32}, \frac{1}{16}, \frac{1}{8}, \frac{1}{4}, 1\} ρi∈{321,161,81,41,1} 为其对应层权重系数。
此外,我们引入频率损失
L
f
\mathcal{L}_\mathrm{f}
Lf ,通过傅里叶变换
F
\mathcal{F}
F约束增强图像的频域分布逼近参考图像。其表达式为:
L
f
=
∥
(
F
(
G
E
(
I
u
)
)
)
−
(
F
(
I
r
)
)
∥
1
.
\mathcal{L}_\mathrm{f}= \left\|\left(\mathcal{F}\left(G_E(I_u)\right)\right)-\left(\mathcal{F}\left(I_r\right)\right)\right\|_1.
Lf=∥(F(GE(Iu)))−(F(Ir))∥1.
在实际应用中,对反向过程施加约束可以确保水下图像增强的可逆性,从而提高后续感知任务的可靠性。L1 范数作为双向约束,用于将所提网络的正向和反向输出与参考图像和水下图像更接近。双向损失 L b \mathcal{L}_{\mathrm{b}} Lb表示为:
L b = ∥ G E ( I u ) − I r ∥ 2 + ∥ G E − 1 ( I r ) − I u ∥ 2 . \mathcal{L}_{\mathrm{b}}=\left\|G_E(I_u) - I_r\right\|_2 + \left\|G_E^{-1}(I_r) - I_u\right\|_2. Lb=∥GE(Iu)−Ir∥2+ GE−1(Ir)−Iu 2.
因此,最终的
L
e
\mathcal{L}_{\mathrm{e}}
Le可以表示为:
L
e
=
λ
1
L
c
+
λ
2
L
f
+
λ
3
L
b
.
\mathcal{L}_\mathrm{e}=\lambda_1\mathcal{L}_\mathrm{c}+\lambda_2\mathcal{L}_\mathrm{f}+\lambda_3 \mathcal{L}_\mathrm{b}.
Le=λ1Lc+λ2Lf+λ3Lb.
任务损失 L t \mathcal{L}_{\mathrm{t}} Lt旨在通过对特定感知任务的约束来提高任务特定网络的性能。在本研究中,我们分别对水下物体检测任务和语义分割任务施加了相应的约束。对于检测任务,引入的任务依赖损失 L t d e t \mathcal{L}_{\mathrm{t}}^{det} Ltdet可以表示为:
L t d e t = L c l a + L l o c , \mathcal{L}_{\mathrm{t}}^{det} = \mathcal{L}_{\mathrm{cla}}+\mathcal{L}_{\mathrm{loc}}, Ltdet=Lcla+Lloc,
其中, L l o c \mathcal{L}_{\mathrm{loc}} Lloc 表示定位损失,用于减少真实标签与预测标签之间的差异。 L cla \mathcal{L}{\text{cla}} Lcla 表示分类损失,旨在最小化真实框和预测框之间的位置差异。在本研究中,采用了焦点损失和GIoU损失,分别作为分类损失和定位损失。至于分割任务,和之前的工作一致, L t s e g \mathcal{L}_{\mathrm{t}}^{seg} Ltseg 被定义为:
L t s e g = − ∑ class s ∗ log ( s ) \mathcal{L}_{\mathrm{t}}^{seg}=-\sum_{\text {class }} \mathbf{s}^* \log (\mathbf{s}) Ltseg=−class ∑s∗log(s)
其中 s ∗ \mathbf{s}^* s∗表示分割标签。
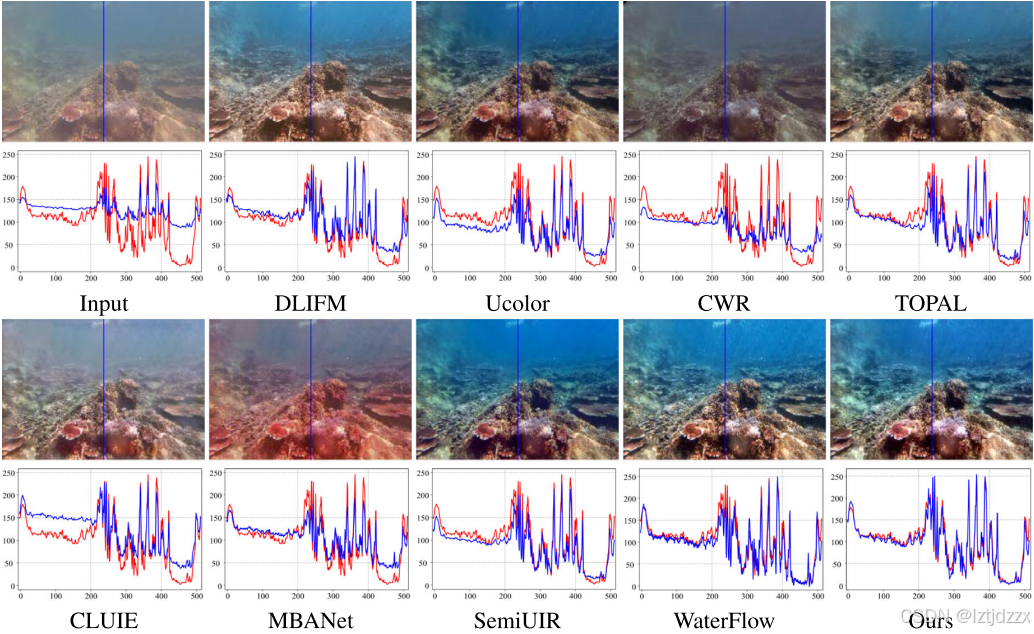
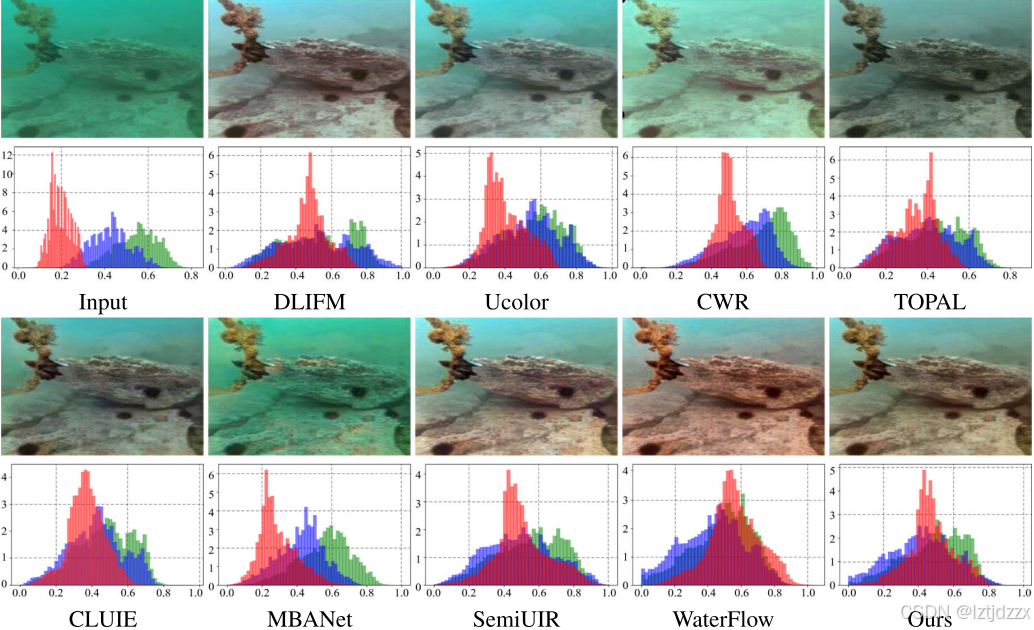
📊 4. 实验

















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









