






水下摄影广泛用于海洋研究、水下探测、无人潜航器(ROV)等领域。然而,由于水环境的复杂性,水下图像往往存在色偏、弱光、模糊等问题,影响图像质量和后续的计算机视觉任务。本篇博客将介绍这些问题的成因,并分享一些常见的统计分析方法,结合 Python 代码进行实战演示。
本文仅仅是图像分析,并不涉及增强/优化操作,使用深度学习去增强图像操作,请参考本人的另一份博客——图像增强任务——基于CycleGAN与UNet分别实现与对比-CSDN博客
1、水下产生色偏、弱光、模糊的原因
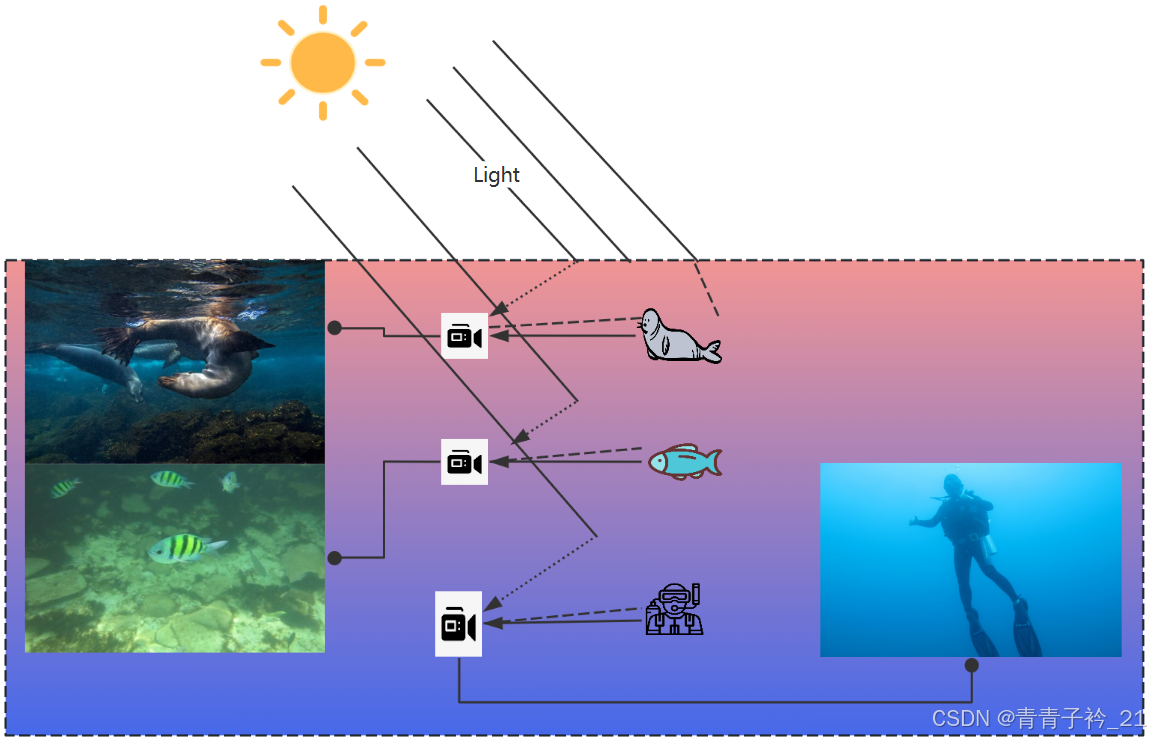
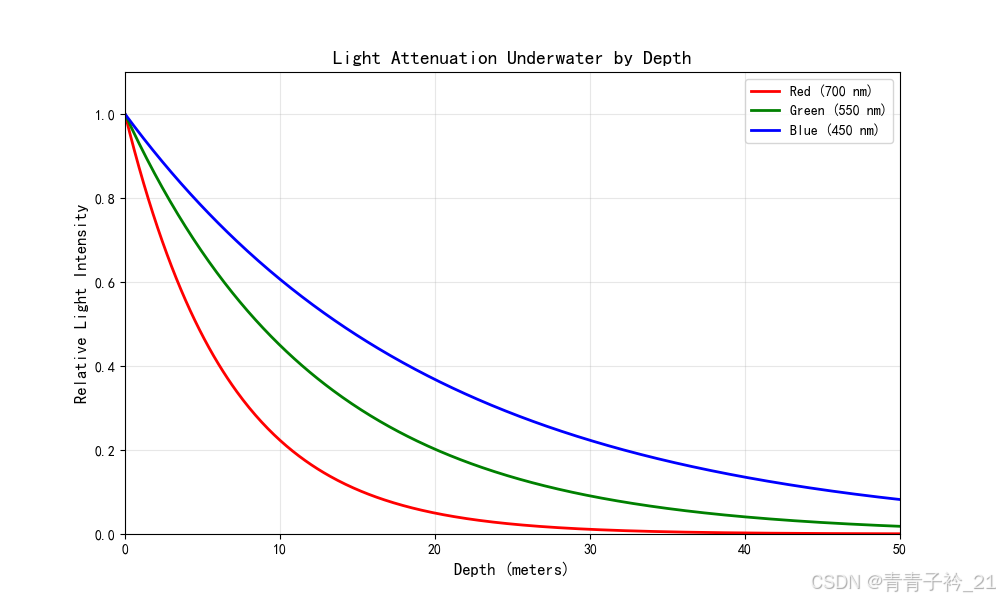
1.1 色偏(Color Cast)
- 水对不同波长的光吸收率不同,红光最先被吸收,导致图像偏蓝或偏绿。
- 由于光线折射,水下不同深度的色彩变化明显。
1.2 弱光(Low Light)
- 水下光线不足,导致图像整体较暗。
- 远距离拍摄时光线衰减,暗部细节缺失。
1.3 模糊(Blurriness)
- 水体中漂浮的微粒导致光散射,降低图像清晰度。
- 由于水流,拍摄时的相机抖动造成运动模糊。
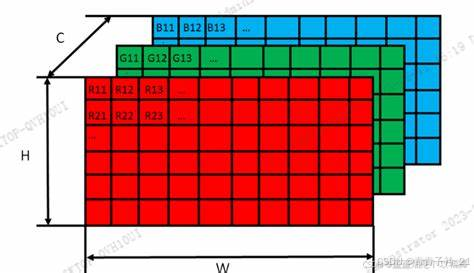
2、RGB通道分析
1. 什么是 RGB 通道?
RGB(Red, Green, Blue)是计算机视觉和数字图像处理中最常用的颜色模型。每张彩色图像由三个通道(R、G、B)组成:
- R(红色通道):代表图像中红色的强度。
- G(绿色通道):代表图像中绿色的强度。
- B(蓝色通道):代表图像中蓝色的强度。
每个通道的像素值范围通常为 0-255(8-bit),三通道的组合决定了最终的颜色。例如:
- (255, 0, 0) 代表 纯红色
- (0, 255, 0) 代表 纯绿色
- (0, 0, 255) 代表 纯蓝色
- (255, 255, 255) 代表 白色
- (0, 0, 0) 代表 黑色
简单来说,你电脑屏幕上每一个像素点,都有三个颜色的电子管,这三个电子管不同的强弱组合,就组成了缤纷多彩的颜色,每一个像素点都是(x,y,z)的三个数值表示,这就是RGB通道。
而 屏幕上/图像 有很多像素点,即如下的三维矩阵即可以 展示画面/表示图像,因此RGB通道对基础分析图像,计算机视觉任务很基础。
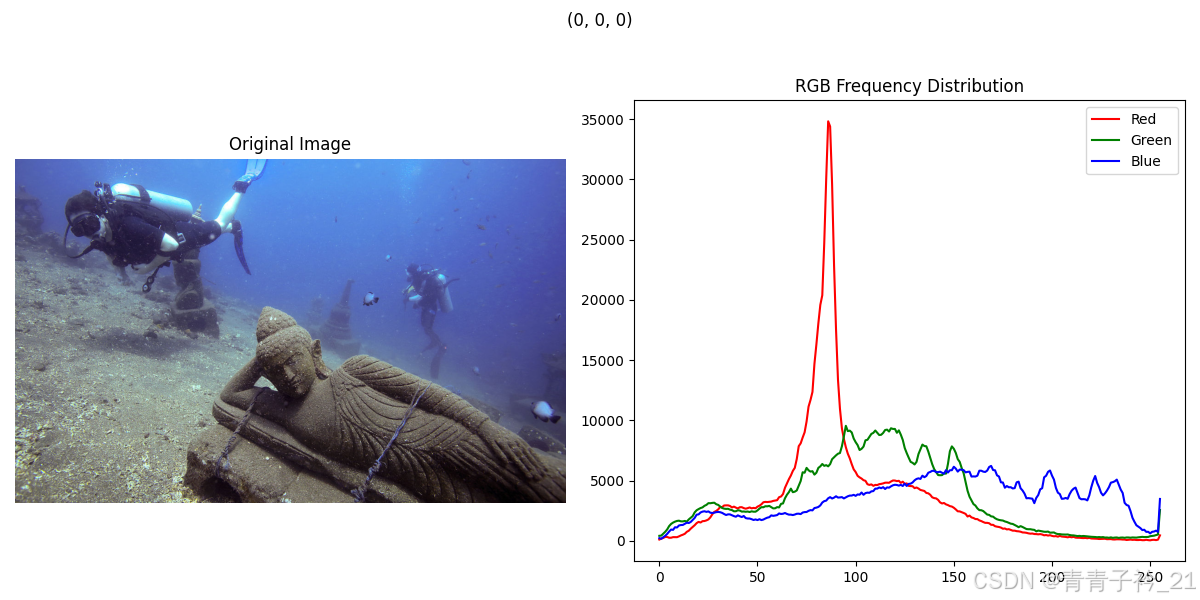
2.样例展示
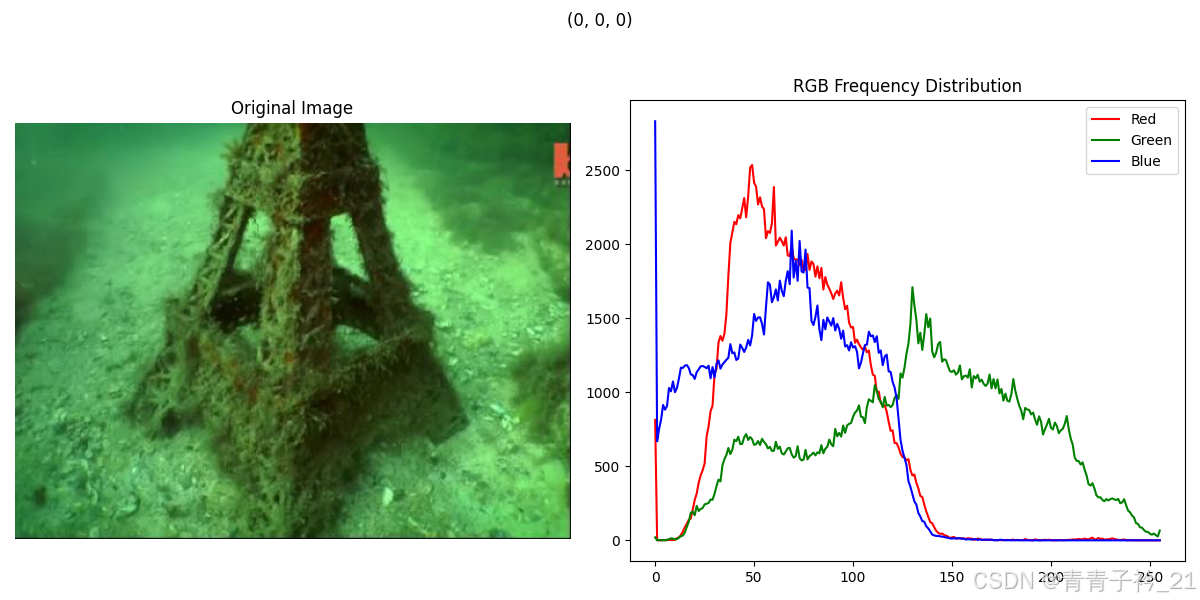
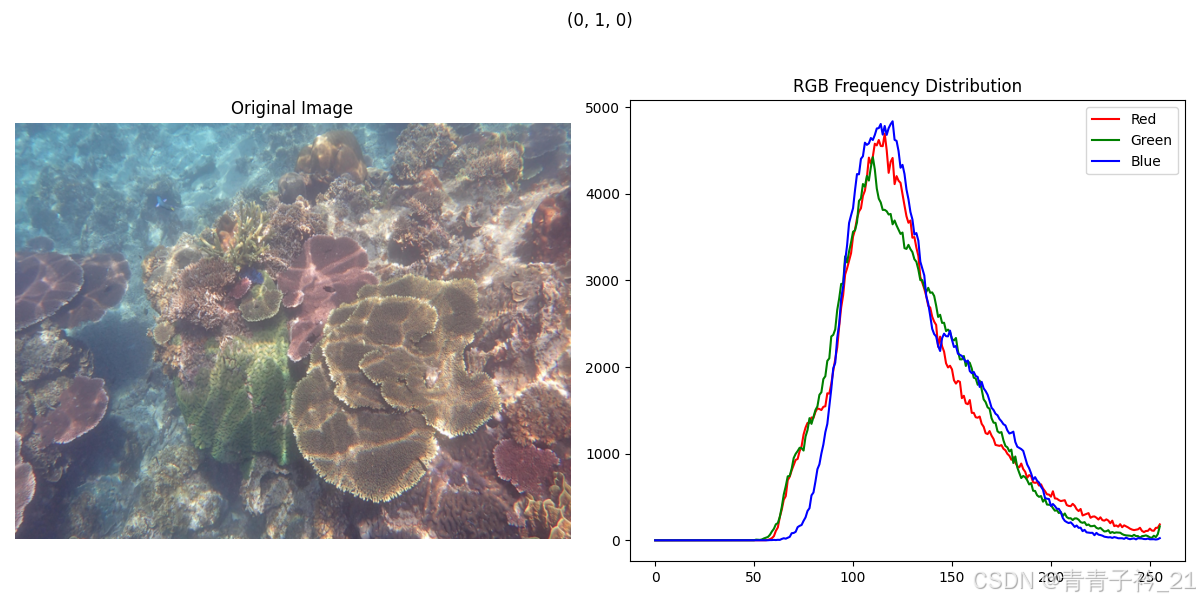
3.代码实现
此Part提供单一图片RGB分析,并提供对文件夹的批量RGB分析共两份代码,其中第二份代码,附加各个图片的统计分析,以csv文件输出
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取图片
image_path = "img_.png" # 替换为你的图片路径
image = cv2.imread(image_path)
# 转换为RGB格式(OpenCV默认是BGR格式)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 初始化颜色通道
colors = ['Red', 'Green', 'Blue']
rgb_channels = ['r', 'g', 'b']
# 创建直方图
plt.figure(figsize=(10, 6))
for i, color in enumerate(colors):
hist = cv2.calcHist([image_rgb], [i], None, [256], [0, 256]) # 计算直方图
plt.plot(hist, color=rgb_channels[i], label=f"{color} Channel") # 绘制折线图
# 图表设置
plt.title("RGB Channel Distribution", fontsize=16)
plt.xlabel("Pixel Value", fontsize=12)
plt.ylabel("Frequency", fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
# 显示结果
# plt.savefig('这里替换为你的路径')
plt.show()import os
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def generate_rgb_histograms(csv_path, image_folder, output_folder):
"""
根据 CSV 文件中的信息,为每张图片生成左图(原图)+右图(RGB分布图)的组合图片。
保存到指定的输出文件夹。
参数:
- csv_path: str,CSV 文件路径。
- image_folder: str,图片文件夹路径。
- output_folder: str,输出文件夹路径。
"""
# 读取 CSV 文件
df = pd.read_csv(csv_path)
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
for idx, row in df.iterrows():
file_name = row["File Name"]
is_color_cast = row["Is_Color_Cast"]
is_low_light = row["Is_Low_Light"]
is_blurry = row["Is_Blurry"]
title = f"({is_color_cast}, {is_low_light}, {is_blurry})"
# 构造图片路径
image_path = os.path.join(image_folder, file_name)
# 检查图片是否存在
if not os.path.exists(image_path):
print(f"Image not found: {file_name}, skipping.")
continue
# 读取图片
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 计算 RGB 频率分布
hist_r = cv2.calcHist([image_rgb], [0], None, [256], [0, 256]).flatten()
hist_g = cv2.calcHist([image_rgb], [1], None, [256], [0, 256]).flatten()
hist_b = cv2.calcHist([image_rgb], [2], None, [256], [0, 256]).flatten()
# 创建组合图
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 左侧:原始图片
axes[0].imshow(image_rgb)
axes[0].axis("off")
axes[0].set_title("Original Image")
# 右侧:RGB 频率分布图
axes[1].plot(hist_r, color='red', label='Red')
axes[1].plot(hist_g, color='green', label='Green')
axes[1].plot(hist_b, color='blue', label='Blue')
axes[1].set_title("RGB Frequency Distribution")
axes[1].legend()
# 设置整体标题
plt.suptitle(title)
# 保存组合图
output_path = os.path.join(output_folder, f"{os.path.splitext(file_name)[0]}_histogram.png")
plt.tight_layout(rect=[0, 0, 1, 0.95]) # 调整布局
plt.savefig(output_path)
plt.close(fig)
print(f"Saved: {output_path}")
# 示例用法
csv_path = "替换为你的 CSV 文件路径" # 替换为你的 CSV 文件路径
image_folder = "替换为图片文件夹路径" # 替换为图片文件夹路径
output_folder = "输出文件夹路径" # 输出文件夹路径
generate_rgb_histograms(csv_path, image_folder, output_folder)
3、图像专项分析
RGB通道仅仅能提供最基础的分析,但针对色偏、弱光、模糊这三类问题,正常人很难肉眼通过直接分辨(记住,人眼是主观的,数据是客观的,比如模糊,人眼认为模糊不一定真正模糊;但也同时应记住,评价指标是主观的而非客观的)
3.1.色偏分析
3.1.1 RGB 均值计算
mean_r = np.mean(image_rgb[:, :, 0])
mean_g = np.mean(image_rgb[:, :, 1])
mean_b = np.mean(image_rgb[:, :, 2])
overall_mean = np.mean(image_rgb)
mean_r、mean_g、mean_b分别是图像 红色、绿色、蓝色通道的均值,代表该通道的平均亮度。overall_mean计算整个图像所有像素的均值,表示整个图像的平均亮度。
这些均值可以用来判断某个颜色是否比其他颜色更突出,比如:
- 如果红色均值明显低于蓝色和绿色,可能意味着图像偏蓝或偏绿。
3.1.2 色偏度(Color Cast)
color_cast = max(abs(mean_r - mean_g), abs(mean_r - mean_b), abs(mean_g - mean_b))
色偏度衡量了不同颜色通道之间的最大偏差:
- 值越大,说明色偏越严重。
- 理想情况下,RGB 三个通道的均值应当接近,表示颜色平衡。
示例解释:
mean_r = 120, mean_g = 100, mean_b = 180
→color_cast = max(|120 - 100|, |120 - 180|, |100 - 180|) = 80
→ 说明色彩不均衡,蓝色偏强。
3.1.3 RGB 均值与整体亮度的偏离
deviation_r = abs(mean_r - overall_mean)
deviation_g = abs(mean_g - overall_mean)
deviation_b = abs(mean_b - overall_mean)
- 计算每个通道的均值与整个图像亮度均值 (
overall_mean) 的偏差。 - 偏差值越大,表示该颜色的影响越大。
示例:
mean_r = 120, mean_g = 100, mean_b = 180, overall_mean = 133deviation_r = |120 - 133| = 13deviation_g = |100 - 133| = 33deviation_b = |180 - 133| = 47- → 蓝色偏差最大,说明蓝色在图像中占主导。
3.1.4 标准差差异(Std_Diff)
std_r = np.std(image_rgb[:, :, 0])
std_g = np.std(image_rgb[:, :, 1])
std_b = np.std(image_rgb[:, :, 2])
std_diff = max(std_r, std_g, std_b) - min(std_r, std_g, std_b)
- 计算 RGB 三个通道的标准差,然后求其最大值与最小值的差值。
- 标准差表示颜色的分布范围,值越大说明该通道的颜色变化越剧烈。
示例:
std_r = 50, std_g = 30, std_b = 70std_diff = 70 - 30 = 40- 说明蓝色通道的颜色变化最大,绿色最稳定。
3.1.5 灰度世界偏差(Gray_World_Bias)
gray_world_bias = np.sqrt((mean_r - mean_g) ** 2 + (mean_r - mean_b) ** 2 + (mean_g - mean_b) ** 2)
- 这个指标衡量 RGB 三个通道的偏差。
- 在 灰度世界假设(Gray World Assumption)下,RGB 三个通道的均值应该相等(白平衡状态)。
- 值越大,说明图像偏色越严重。
3.1.6 代码整合
import cv2
import numpy as np
def analyze_color_cast(image_path):
"""
分析图像的色偏相关指标。
参数:
image_path (str): 图像文件路径。
返回:
dict: 包含色偏统计指标的字典。
"""
# 读取图片并转换为 RGB
image = cv2.imread(image_path)
if image is None:
raise FileNotFoundError(f"图像路径无效:{image_path}")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 计算RGB三通道均值
mean_r = np.mean(image_rgb[:, :, 0])
mean_g = np.mean(image_rgb[:, :, 1])
mean_b = np.mean(image_rgb[:, :, 2])
overall_mean = np.mean(image_rgb)
# 1. 通道均值差异 (Color_Cast)
color_cast = max(abs(mean_r - mean_g), abs(mean_r - mean_b), abs(mean_g - mean_b))
# 2. RGB均值与灰度均值的偏离
deviation_r = abs(mean_r - overall_mean)
deviation_g = abs(mean_g - overall_mean)
deviation_b = abs(mean_b - overall_mean)
# 3. 标准差差异 (Std_Diff)
std_r = np.std(image_rgb[:, :, 0])
std_g = np.std(image_rgb[:, :, 1])
std_b = np.std(image_rgb[:, :, 2])
std_diff = max(std_r, std_g, std_b) - min(std_r, std_g, std_b)
# 4. 灰度世界偏差 (Gray_World_Bias)
gray_world_bias = np.sqrt((mean_r - mean_g) ** 2 + (mean_r - mean_b) ** 2 + (mean_g - mean_b) ** 2)
# 5. 白点距离 (White_Point_Distance)
white_point_distance = np.sqrt((255 - mean_r) ** 2 + (255 - mean_g) ** 2 + (255 - mean_b) ** 2)
# 结果存储为字典
results = {
"Color_Cast": color_cast,
"Deviation (R)": deviation_r,
"Deviation (G)": deviation_g,
"Deviation (B)": deviation_b,
"Std_Diff": std_diff,
"Gray_World_Bias": gray_world_bias,
"White_Point_Distance": white_point_distance
}
return results
# 示例使用
if __name__ == '__main__':
image_path = 'img_.png' # 替换为实际路径
results = analyze_color_cast(image_path)
# 打印结果
for metric, value in results.items():
print(f"{metric}: {value}")
3.2 弱光分析
3.2.1 平均亮度(Mean Brightness)
mean_brightness = np.mean(gray_image)- 定义:图像的平均亮度,即所有像素值的平均值。
- 计算方法:将灰度图像(每个像素的亮度值)中的所有值加总后求平均。
- 含义:平均亮度值越高,表示图像越亮;值越低,表示图像较暗。
3.2.2 亮度分布的偏移(Skewness)
skewness = skew(gray_image.flatten())
- 定义:亮度分布的偏态度(skewness),衡量亮度分布的不对称程度。
- 计算方法:使用 SciPy 库中的
skew()函数计算灰度值的一阶统计量,即图像亮度分布的偏斜程度。- 如果偏度为正,说明亮度偏向于低值(图像较暗)。
- 如果偏度为负,说明亮度偏向于高值(图像较亮)。
- 如果偏度为零,说明亮度分布对称。
3.2.3 低亮度像素占比(Low Brightness Ratio)
low_brightness_threshold = 50
low_brightness_ratio = np.sum(gray_image < low_brightness_threshold) / gray_image.size
- 定义:图像中亮度小于指定阈值的像素所占的比例。
- 计算方法:将亮度小于 50 的像素计算出来,然后除以总像素数,得到低亮度像素占比。
- 该阈值 50 是一个经验值,可以根据需要进行调整。
- 含义:这个指标用于评估图像中有多少像素属于较暗区域。如果比率较高,说明图像有较多的暗区域。
3.2.4 亮度标准差(Brightness Std)
brightness_std = np.std(gray_image)
- 定义:亮度的标准差,衡量图像亮度的波动性或分布的宽度。
- 计算方法:计算灰度图像中所有像素值的标准差。
- 标准差越大,表示图像亮度的差异越大(对比度高)。
- 标准差越小,表示图像亮度分布较为均匀。
3.2.5 暗通道均值(Mean Dark Channel)
dark_channel = np.min(image, axis=2)
mean_dark_channel = np.mean(dark_channel)
- 定义:暗通道(dark channel)是图像中每个像素点在 RGB 通道中的最小值,通常用于评估图像中的暗区。
- 计算方法:对于每个像素,选取其在 RGB 三个通道中的最小值,形成一个新的灰度图像(暗通道)。然后计算该图像的均值。
- 含义:如果图像的暗通道均值较低,说明图像包含较多的暗区域,通常会出现在低光环境下的图像中。
3.2.6 最大亮度(Max Brightness)
max_brightness = np.max(gray_image)
- 定义:图像中最亮的像素值。
- 计算方法:求取灰度图像中的最大亮度值。
- 含义:此值越高,表示图像中的亮区越亮。如果最大亮度接近 255,图像的亮区较为明显。
3.2.7 对比度(Contrast)
contrast = np.max(gray_image) - np.min(gray_image)- 定义:图像的对比度,计算最大亮度和最小亮度之间的差值。
- 计算方法:计算灰度图像的最大值与最小值之差。
- 含义:
- 对比度越大,说明图像亮度差异越大,图像细节更加清晰。
- 对比度越小,说明图像亮度差异较小,可能存在较为单一的色调。
3.2.8 代码整合
import cv2
import numpy as np
from scipy.stats import skew
def analyze_image_brightness(image_path):
"""
分析图像亮度相关指标。
参数:
image_path (str): 图像文件路径。
返回:
dict: 包含亮度相关统计指标的字典。
"""
# 读取图片并转换为灰度
image = cv2.imread(image_path)
if image is None:
raise FileNotFoundError(f"图像路径无效:{image_path}")
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 1. 平均亮度
mean_brightness = np.mean(gray_image)
# 2. 亮度分布的偏移(直方图偏态)
skewness = skew(gray_image.flatten())
# 3. 低亮度像素占比
low_brightness_threshold = 50
low_brightness_ratio = np.sum(gray_image < low_brightness_threshold) / gray_image.size
# 4. 亮度标准差
brightness_std = np.std(gray_image)
# 5. 暗通道均值
dark_channel = np.min(image, axis=2)
mean_dark_channel = np.mean(dark_channel)
# 6. 最大亮度
max_brightness = np.max(gray_image)
# 7. 对比度
contrast = np.max(gray_image) - np.min(gray_image)
# 结果存储为字典
results = {
"Mean Brightness": mean_brightness,
"Skewness": skewness,
"Low Brightness Ratio": low_brightness_ratio,
"Brightness Std": brightness_std,
"Mean Dark Channel": mean_dark_channel,
"Max Brightness": max_brightness,
"Contrast": contrast
}
return results
# 示例使用
if __name__ == '__main__':
image_path = 'ori_picture/4_img_.png' # 替换为实际路径
results = analyze_image_brightness(image_path)
# 打印结果
for metric, value in results.items():
print(f"{metric}: {value}")
3.3 模糊分析
3.3.1 拉普拉斯方差(Variance of Laplacian)
laplacian = cv2.Laplacian(image, cv2.CV_64F)
laplacian_var = laplacian.var()
- 定义:拉普拉斯方差用于衡量图像的细节程度和清晰度。拉普拉斯算子是一个二阶导数滤波器,能够突出显示图像中的边缘和细节信息。
- 计算方法:先对图像进行拉普拉斯滤波,得到图像的二阶导数图像,再计算该图像的方差。
- 含义:如果图像非常清晰,拉普拉斯滤波后的结果会有较大的变化,方差也会较大。模糊图像的拉普拉斯方差通常较小。
- 方差越大,表示图像越清晰。
- 方差越小,表示图像越模糊。
3.3.2 梯度幅值统计(Sobel Gradient)
sobel_x = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(image, cv2.CV_64F, 0, 1, ksize=3)
gradient_magnitude = np.sqrt(sobel_x ** 2 + sobel_y ** 2)
gradient_mean = gradient_magnitude.mean()
gradient_std = gradient_magnitude.std()
- 定义:图像的梯度表示像素强度的变化,常用于边缘检测。Sobel算子用于计算图像在x轴和y轴方向的梯度,进而计算图像的梯度幅值。
- 计算方法:
- 使用 Sobel 算子 计算 x 轴和 y 轴的梯度(sobel_x 和 sobel_y)。
- 计算每个像素点的梯度幅值(gradient_magnitude)。
- 计算梯度幅值的 均值(gradient_mean) 和 标准差(gradient_std)。
- 含义:
- 均值(mean):表示图像的平均梯度强度,较高的均值通常代表图像较清晰,边缘较多。
- 标准差(std):表示图像梯度的变化程度,较高的标准差表示图像的边缘较为分明,较低的标准差可能表示图像模糊。
3.3.3 高频成分能量(High Frequency Energy)
fft = fft2(image)
fft_shifted = fftshift(fft)
magnitude_spectrum = np.abs(fft_shifted)
rows, cols = magnitude_spectrum.shape
crow, ccol = rows // 2, cols // 2
high_freq = magnitude_spectrum[crow - 30:crow + 30, ccol - 30:ccol + 30]
high_freq_energy = np.sum(high_freq)- 定义:通过快速傅里叶变换(FFT)分析图像的频率成分。高频成分通常对应图像中的细节和边缘信息。
- 计算方法:
- 对图像进行 傅里叶变换(FFT),得到图像的频谱。
- 使用 fftshift() 函数将低频部分移到频谱中心。
- 提取频谱中去除低频部分的 高频区域(中心附近的频率通常代表低频)。
- 计算高频区域的总能量(high_freq_energy),即所有高频成分的总和。
- 含义:
- 高频成分能量较高时,表示图像有更多的细节和边缘信息,通常图像较清晰。
- 高频能量较低时,可能表示图像较模糊。
3.3.4 图像对比度(Local Contrast)
contrast = (np.max(image) - np.min(image)) / (np.max(image) + np.min(image))
- 定义:图像的对比度,用于衡量图像中最亮和最暗部分之间的差异。
- 计算方法:计算图像的最大亮度值和最小亮度值之间的差异,然后归一化。
- 含义:
- 对比度越高,图像细节更加明显,通常表示图像清晰。
- 对比度较低,图像可能较为平坦,细节不清晰,可能是模糊图像。
3.3.5 边缘像素占比(Edge Ratio)
edges = cv2.Canny(image, 100, 200)
edge_ratio = np.sum(edges > 0) / edges.size- 定义:边缘检测通过 Canny 算法提取图像中的边缘像素,并计算边缘像素在图像中的占比。
- 计算方法:
- 使用 Canny 算法 提取图像的边缘,得到一个二值图像(边缘为白色,其他部分为黑色)。
- 计算边缘像素占图像总像素的比例。
- 含义:
- 边缘占比越大,图像通常越清晰,细节更多。
- 边缘占比较小,可能表示图像较为模糊,缺少明显的细节。
3.3.6 代码整合
import cv2
import numpy as np
from scipy.fftpack import fft2, fftshift
def analyze_image_blurriness(image_path):
"""
分析图像的模糊度相关指标。
参数:
image_path (str): 图像文件路径。
返回:
dict: 包含模糊度统计指标的字典。
"""
# 读取图像(灰度图)
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if image is None:
raise FileNotFoundError(f"图像路径无效:{image_path}")
# 1. 拉普拉斯方差 (Variance of Laplacian)
laplacian = cv2.Laplacian(image, cv2.CV_64F)
laplacian_var = laplacian.var()
# 2. 梯度幅值统计 (Sobel Gradient)
sobel_x = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(image, cv2.CV_64F, 0, 1, ksize=3)
gradient_magnitude = np.sqrt(sobel_x ** 2 + sobel_y ** 2)
gradient_mean = gradient_magnitude.mean()
gradient_std = gradient_magnitude.std()
# 3. 高频成分能量 (High Frequency Energy)
fft = fft2(image)
fft_shifted = fftshift(fft)
magnitude_spectrum = np.abs(fft_shifted)
rows, cols = magnitude_spectrum.shape
crow, ccol = rows // 2, cols // 2
high_freq = magnitude_spectrum[crow - 30:crow + 30, ccol - 30:ccol + 30] # 剔除低频中心区域
high_freq_energy = np.sum(high_freq)
# 4. 图像对比度 (Local Contrast)
contrast = (np.max(image) - np.min(image)) / (np.max(image) + np.min(image))
# 5. 边缘像素占比 (Edge Ratio)
edges = cv2.Canny(image, 100, 200)
edge_ratio = np.sum(edges > 0) / edges.size
# 结果存储为字典
results = {
"Variance of Laplacian": laplacian_var,
"Gradient Magnitude - Mean": gradient_mean,
"Gradient Magnitude - Std": gradient_std,
"High Frequency Energy": high_freq_energy,
"Contrast": contrast,
"Edge Ratio": edge_ratio
}
return results
# 示例使用
if __name__ == '__main__':
image_path = 'img_.png' # 替换为实际路径
results = analyze_image_blurriness(image_path)
# 打印结果
for metric, value in results.items():
print(f"{metric}: {value}")
3.4 可视化
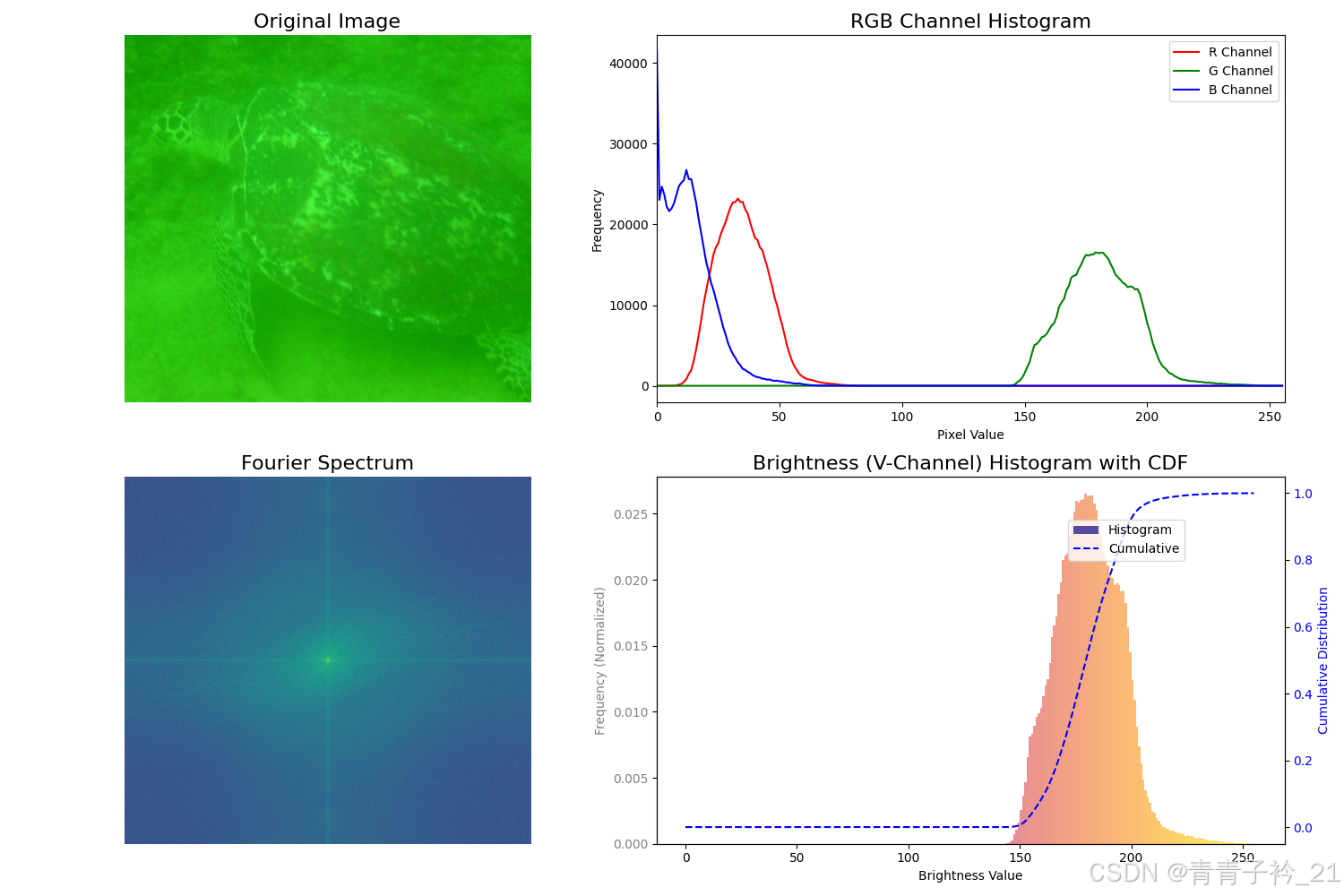
评价色偏、弱光、模糊三类问题,每个问题都有很多的指标,而且这个指标是主观的/侧重不同的,这里分别抽取三个进行分析,分别是RGB频率图,傅里叶图谱(判别模糊性),亮度直方图(判别弱光)。
傅里叶图谱是什么?
傅里叶图谱是傅里叶变换后的频谱图,它表示了信号或图像在不同频率成分上的强度。傅里叶图谱展示了图像中不同频率的振幅信息,以及它们的分布情况。
在图像处理中,傅里叶图谱通常被用来表示图像中的频率成分。在图像的频域中:
-
低频成分:通常表示图像中的平滑区域、整体亮度和大尺度结构。
-
高频成分:通常表示图像中的细节、边缘和小尺度结构。
傅里叶图谱的可视化
傅里叶变换后,得到的频谱通常是一个复数,表示频率的幅度和相位。为了可视化,通常采用幅度谱,即频谱的幅度值,来展示信号在各个频率上的强度分布。傅里叶图谱的一些常见特性:
-
频谱中心:傅里叶变换后的频谱中,低频成分通常出现在频谱的中心。
-
高频成分:图像的细节通常由高频成分表示,这些成分在频谱的边缘。
-
低频成分:图像的整体亮度和结构信息通常由低频成分主导,出现在频谱中心附近。
import cv2
import matplotlib.pyplot as plt
import numpy as np
from numpy.fft import fft2, fftshift
from numpy import log
# 加载图片
image_path = "img_.png" # 替换为图片路径
img = cv2.imread(image_path)
if img is None:
raise FileNotFoundError(f"无法加载图片,请检查路径是否正确:{image_path}")
# 转换为 RGB 格式
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 计算 RGB 通道直方图
colors = ('r', 'g', 'b')
hist_data = {}
for i, color in enumerate(colors):
hist = cv2.calcHist([img_rgb], [i], None, [256], [0, 256])
hist_data[color] = hist
# 提取亮度直方图(V 通道)
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
v_channel = img_hsv[:, :, 2]
# 计算傅里叶频谱
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
f = fft2(gray)
fshift = fftshift(f)
magnitude_spectrum = 20 * np.log1p(np.abs(fshift)) # 使用 log1p 避免 log(0)
# 绘制图像,布局为 2 行 3 列
fig = plt.figure(figsize=(15, 10))
# 1. 原图(第1列的上方)
ax1 = fig.add_subplot(2, 2, 1)
ax1.imshow(img_rgb)
ax1.set_title("Original Image",fontsize=16)
ax1.axis('off')
# 2. 傅里叶频谱(第1列的下方)
ax2 = fig.add_subplot(2, 2, 3)
ax2.imshow(magnitude_spectrum, cmap='viridis')
ax2.set_title("Fourier Spectrum",fontsize=16)
ax2.axis('off')
# 创建双 Y 轴图
ax3 = fig.add_subplot(2, 2, 4)
# 主坐标轴:绘制亮度直方图
n, bins, patches = ax3.hist(
v_channel.ravel(),
bins=256,
range=(0, 256),
color='gray',
alpha=0.7,
label="Histogram",
density=True # 归一化直方图
)
# 为直方图添加伪彩色
for i in range(len(patches)):
patches[i].set_facecolor(plt.cm.plasma(bins[i] / 256)) # 使用伪彩色映射
# 设置主坐标轴标签
ax3.set_xlabel("Brightness Value")
ax3.set_ylabel("Frequency (Normalized)", color="gray")
ax3.tick_params(axis="y", labelcolor="gray")
# 次坐标轴:绘制累积直方图
ax3_cdf = ax3.twinx() # 创建次坐标轴
cdf = n.cumsum() / n.sum() # 计算累积分布函数
ax3_cdf.plot(bins[:-1], cdf, color="blue", linestyle="--", linewidth=1.5, label="Cumulative")
# 设置次坐标轴标签
ax3_cdf.set_ylabel("Cumulative Distribution", color="blue")
ax3_cdf.tick_params(axis="y", labelcolor="blue")
# 添加标题
ax3.set_title("Brightness (V-Channel) Histogram with CDF",fontsize=16)
# 添加图例
fig.legend(loc="upper right", bbox_to_anchor=(0.85, 0.9), bbox_transform=ax3.transAxes)
# 4. RGB 通道直方图(占据第3列)
ax4 = fig.add_subplot(2, 2, 2)
for color in colors:
ax4.plot(hist_data[color], color=color, label=f"{color.upper()} Channel")
ax4.set_title("RGB Channel Histogram",fontsize=16)
ax4.set_xlim([0, 256])
ax4.set_xlabel("Pixel Value")
ax4.set_ylabel("Frequency")
ax4.legend()
# 调整布局并显示
plt.tight_layout()
plt.savefig('abcd.png')
plt.show()3.5 统计指标及其输出
3.5.1 结构化数据输出
import os
import csv
import cv2
from one_low_light_analysis import analyze_image_brightness
from one_color_bias_analysis import analyze_color_cast
from one_fuzzy_analysis import analyze_image_blurriness
def process_image_folder(folder_path, output_csv):
"""
遍历指定文件夹中的所有图片文件,并对每个图片进行颜色偏差、亮度/对比度分析、模糊度分析。
最终将所有结果保存到CSV文件中。
参数:
folder_path (str): 目标文件夹路径,包含图片文件。
output_csv (str): 输出的CSV文件路径。
"""
# 打开CSV文件以写入结果
with open(output_csv, mode='w', newline='') as file:
writer = csv.writer(file)
# 写入CSV的表头
writer.writerow([
'File Name',
'Color_Cast', 'Deviation (R)', 'Deviation (G)', 'Deviation (B)',
'Std_Diff', 'Gray_World_Bias', 'White_Point_Distance',
'Mean Brightness', 'Skewness', 'Low Brightness Ratio', 'Brightness Std',
'Mean Dark Channel', 'Max Brightness', 'Contrast',
'Variance of Laplacian', 'Gradient Magnitude - Mean', 'Gradient Magnitude - Std',
'High Frequency Energy', 'Contrast', 'Edge Ratio'
])
# 遍历文件夹中的所有图片文件
for filename in os.listdir(folder_path):
# 只处理图片文件(以常见图片扩展名为例)
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
image_path = os.path.join(folder_path, filename)
try:
# 调用每个分析函数
color_results = analyze_color_cast(image_path)
brightness_results = analyze_image_brightness(image_path)
blurriness_results = analyze_image_blurriness(image_path)
# 将文件名及其分析结果写入CSV
writer.writerow([filename] +
list(color_results.values()) +
list(brightness_results.values()) +
list(blurriness_results.values()))
except Exception as e:
print(f"无法处理文件 {filename}:{e}")
# 示例使用
folder_path = 'ori_picture' # 替换为您的文件夹路径
output_csv = 'output/statistical_index.csv' # 替换为您希望保存的CSV文件路径
process_image_folder(folder_path, output_csv)
3.5.2 指标判别
首先进行阈值检验(主观设定,但业界有常用阈值),其次进行0/1输出,最后附加三列,分别是{是否色偏、是否弱光、是否模糊},最后输出的结果是对csv文件附加判别列,因此不重复展示。
可以根据需求不同,选择不同的指标来进行判别,也可采用and语句进行多指标联合判别,又或采用模糊匹配等技术,进行多指标模糊判别,这里只列出常规数值判别,关于模糊匹配技术,笔者会在之后单独出一个blog去讲解。
import os
import csv
import cv2
from one_low_light_analysis import analyze_image_brightness
from one_color_bias_analysis import analyze_color_cast
from one_fuzzy_analysis import analyze_image_blurriness
def process_image_folder(folder_path, output_csv):
"""
遍历指定文件夹中的所有图片文件,并对每个图片进行颜色偏差、亮度/对比度分析、模糊度分析。
最终将所有结果保存到CSV文件中。
参数:
folder_path (str): 目标文件夹路径,包含图片文件。
output_csv (str): 输出的CSV文件路径。
"""
# 打开CSV文件以写入结果
with open(output_csv, mode='w', newline='') as file:
writer = csv.writer(file)
# 写入CSV的表头
writer.writerow([
'File Name',
'Color_Cast', 'Deviation (R)', 'Deviation (G)', 'Deviation (B)',
'Std_Diff', 'Gray_World_Bias', 'White_Point_Distance',
'Mean Brightness', 'Skewness', 'Low Brightness Ratio', 'Brightness Std',
'Mean Dark Channel', 'Max Brightness', 'Contrast',
'Variance of Laplacian', 'Gradient Magnitude - Mean', 'Gradient Magnitude - Std',
'High Frequency Energy', 'Contrast', 'Edge Ratio'
])
# 遍历文件夹中的所有图片文件
for filename in os.listdir(folder_path):
# 只处理图片文件(以常见图片扩展名为例)
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
image_path = os.path.join(folder_path, filename)
try:
# 调用每个分析函数
color_results = analyze_color_cast(image_path)
brightness_results = analyze_image_brightness(image_path)
blurriness_results = analyze_image_blurriness(image_path)
# 将文件名及其分析结果写入CSV
writer.writerow([filename] +
list(color_results.values()) +
list(brightness_results.values()) +
list(blurriness_results.values()))
except Exception as e:
print(f"无法处理文件 {filename}:{e}")
# 示例使用
folder_path = 'ori_picture' # 替换为您的文件夹路径
output_csv = 'output/statistical_index.csv' # 替换为您希望保存的CSV文件路径
process_image_folder(folder_path, output_csv)
3.5.3 统计指标可视化
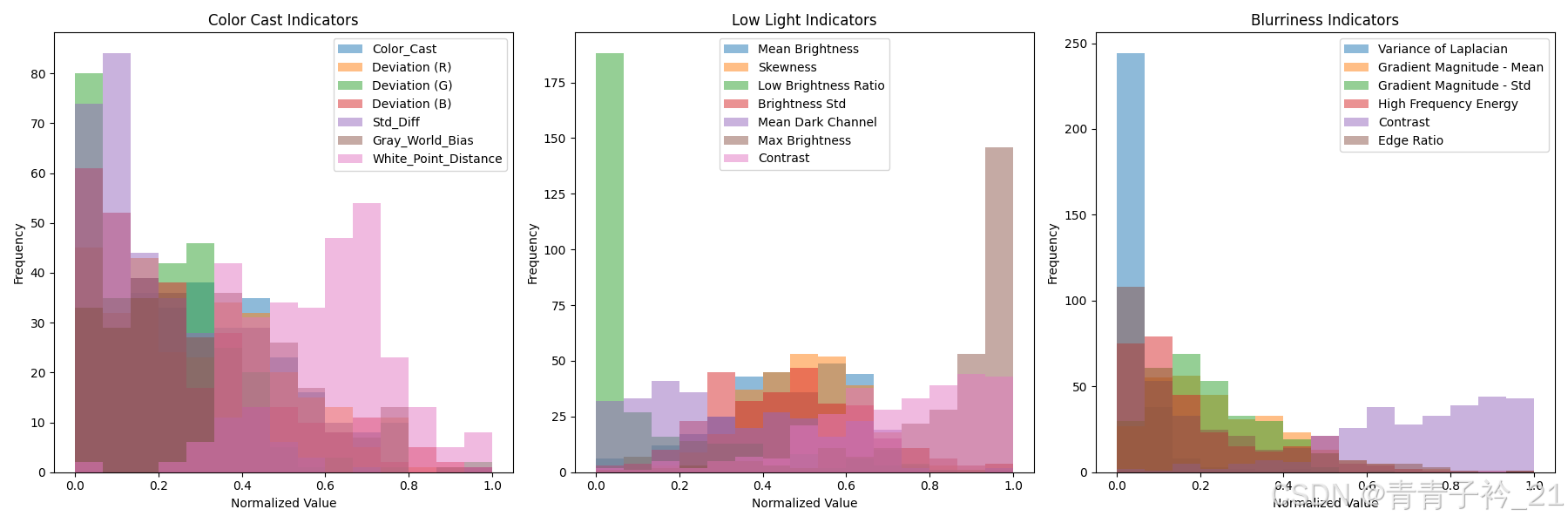
可以看出,对同一问题,不同指标的分布不同,或者说侧重点不同,看读者需求而定,举例如下:
拉普拉斯方差(Variance of Laplacian)
-
定义:这种方法通过计算图像中拉普拉斯算子结果的方差来衡量图像的清晰度。拉普拉斯算子是一种二阶导数算子,它强调图像中的快速变化部分,即边缘。
-
工作原理:对图像应用拉普拉斯滤波器后,如果图像清晰,则其边缘会非常明显,导致结果的方差较大;反之,若图像模糊,边缘不明显,方差则较小。
-
优点:实现简单,计算速度快。
-
缺点:可能受到噪声的影响,因为拉普拉斯算子同样会对噪声敏感。
高频成分能量(High Frequency Energy)
-
定义:此方法基于傅里叶变换,通过分析图像的频率域来评估其清晰度。具体来说,它关注的是图像频谱中高频部分的能量占比。
-
工作原理:将图像转换到频率域后,清晰图像通常在高频区域含有更多的能量,因为这些部分代表了图像中的细节和边缘信息;而模糊图像在高频区域能量较少。
-
优点:能更准确地反映图像中真实边缘与细节的情况,且可以通过调整阈值来减少噪声影响。
-
缺点:计算复杂度相对较高,需要进行傅里叶变换等操作。
import pandas as pd
import matplotlib.pyplot as plt
# 数据文件路径
file_path = 'output/statistical_index.csv'
# 加载数据
df = pd.read_csv(file_path)
# 各个列表
color_cast_list = [
'Color_Cast', 'Deviation (R)', 'Deviation (G)', 'Deviation (B)',
'Std_Diff', 'Gray_World_Bias', 'White_Point_Distance'
]
low_light_list = [
'Mean Brightness', 'Skewness', 'Low Brightness Ratio', 'Brightness Std',
'Mean Dark Channel', 'Max Brightness', 'Contrast'
]
blurriness_list = [
'Variance of Laplacian', 'Gradient Magnitude - Mean', 'Gradient Magnitude - Std',
'High Frequency Energy', 'Contrast', 'Edge Ratio'
]
# 绘制图像
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
# 子图 1: 色偏指标
axes[0].set_title('Color Cast Indicators')
for col in color_cast_list:
if col in df.columns:
norm_data = (df[col] - df[col].min()) / (df[col].max() - df[col].min()) # 归一化
axes[0].hist(norm_data, bins=15, alpha=0.5, label=col)
axes[0].legend()
axes[0].set_xlabel('Normalized Value')
axes[0].set_ylabel('Frequency')
# 子图 2: 低光指标
axes[1].set_title('Low Light Indicators')
for col in low_light_list:
if col in df.columns:
norm_data = (df[col] - df[col].min()) / (df[col].max() - df[col].min()) # 归一化
axes[1].hist(norm_data, bins=15, alpha=0.5, label=col)
axes[1].legend()
axes[1].set_xlabel('Normalized Value')
axes[1].set_ylabel('Frequency')
# 子图 3: 模糊检验指标
axes[2].set_title('Blurriness Indicators')
for col in blurriness_list:
if col in df.columns:
norm_data = (df[col] - df[col].min()) / (df[col].max() - df[col].min()) # 归一化
axes[2].hist(norm_data, bins=15, alpha=0.5, label=col)
axes[2].legend()
axes[2].set_xlabel('Normalized Value')
axes[2].set_ylabel('Frequency')
plt.tight_layout()
plt.savefig('好图当赏.png')
plt.show()
3.5.4 判别结果可视化
每张图片上有一个形状为(3,)的元组,如(1,0,1)表示 图像存在色偏,不存在弱光,存在模糊 的问题。

import os
import pandas as pd
import cv2
import matplotlib.pyplot as plt
def create_image_collage(csv_path, image_folder, output_image_path):
"""
根据 CSV 文件中的信息,生成一个 3x3 的子图大图。
每个子图显示对应的图片,并将 (Is_Color_Cast, Is_Low_Light, Is_Blurry) 显示为标题。
参数:
- csv_path: str,CSV 文件路径。
- image_folder: str,图片文件夹路径。
- output_image_path: str,保存大图的路径。
"""
# 读取 CSV 文件
df = pd.read_csv(csv_path)
# 仅取前 9 条记录
selected_data = df.head(9)
print(df.columns)
# 初始化子图
fig, axes = plt.subplots(3, 3, figsize=(12, 12))
axes = axes.flatten() # 将二维的子图数组展平
# 遍历前 9 条数据
for idx, (file_name, is_color_cast, is_low_light, is_blurry) in enumerate(
zip(selected_data["File Name"].astype(str),
selected_data["Is_Color_Cast"],
selected_data["Is_Low_Light"],
selected_data["Is_Blurry"])):
# 构造图片路径
image_path = os.path.join(image_folder, file_name)
if os.path.exists(image_path):
# 读取图片
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 显示图片
axes[idx].imshow(image_rgb)
axes[idx].axis("off")
# 设置标题为元组形式
axes[idx].set_title(f"({is_color_cast}, {is_low_light}, {is_blurry})")
else:
# 如果图片不存在,用空白填充
axes[idx].axis("off")
axes[idx].set_title("Image not found")
# 如果不足 9 张图片,隐藏多余的子图
for idx in range(len(selected_data), 9):
axes[idx].axis("off")
# 保存大图
plt.tight_layout()
plt.savefig(output_image_path,dpi=1000)
plt.close()
# 示例用法
csv_path = "output/statistical_test_result.csv" # 替换为你的 CSV 文件路径
image_folder = "ori_picture" # 替换为图片文件夹路径
output_image_path = "visual_show.png" # 输出大图路径
create_image_collage(csv_path, image_folder, output_image_path)
(小贴士:dpi参数控制分辨率,一般竞赛,论文对分辨率有要求,一遍清晰度越高越好,但如果图片太大的话,也会导致资源占用过多,总而言之,尽可能的dpi越大越好)
4、尾言
本文主要实现了图像的统计分析及三大问题的功能判别,但对于问题图像的增强,及数据预处理,笔者将在后续发表blog说明,如果看到这里觉得还有些用处的话,麻烦给笔者点个赞,感谢您的支持。

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









