






线性回归的因变量是定量数据,如果遇到分类变量的情况,则不适合拟合线性回归。比如贷款违约的相关性研究,研究目标只有两种结局,数字1表示违约,数字0表示未违约,如果用线性回归方程来解决该问题,方程等号左侧是只有两种结局0或1,而方程等号右侧的值域是任意解,显然此类问题不能用线性回归方程来解决。
Logistic回归有多种类型,包括二元Logistic回归、多分类Logistic回归、有序Logistic回归,以及条件Logistic回归,在SPSSAU中对应有【二元Logit】、【有序Logit】、【多分类Logit】,以及【条件Logit回归】功能模块。本节主要介绍这四种类型的Logistic回归原理及应用。
Logistic回归,是一种广义的线性回归分析模型,它是研究分类型因变量与某些影响因素之间关系的一种回归分析方法。
1. Logistic回归的类型
如图 5-23所示,根据数据资料的情况,可分为成组数据资料的非条件Logistic回归与配伍资料的条件Logistic回归。其中非条件Logistic回归根据因变量分类水平个数,可分为二元Logistic回归、多分类Logistic回归和有序Logistic回归。
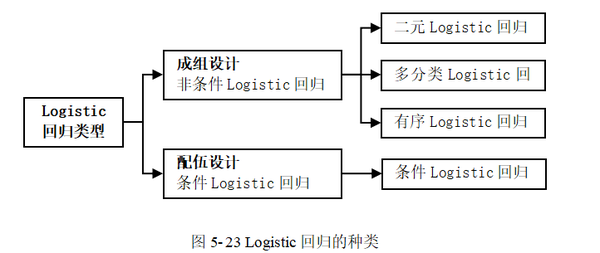
(1) 二元Logistic回归:也称为二项Logistic回归、二分类Logistic回归,因变量只有两种结局,且结局是互斥的,比如死亡与未死亡,癌症淋巴结转移与未转移。
(2) 多分类Logistic回归:也称为多项Logistic回归、多元Logistic回归,因变量是无序多分类变量,比如某研究欲了解不同社区与性别之间成年居民获取健康知识途径是否不同,获取健康知识途径包括三种,分别是传统大众媒介=1,网络=2,社区宣传=3,该因变量即为无序的多分类变量,该问题适合采用多分类Logistic回归进行分析。
(3) 有序Logistic回归:因变量为有序分类变量(等级数据),比如医学研究中关与某病治疗效果,无效=1,有效=2,痊愈=3,如果要研究疗效的影响因素,则采用有序Logistic回归。
(4) 条件Logistic回归:又称配对Logistic回归,其主要用于配对资料或分层资料的多因素分析,包括1:1和 1:M配对资料的研究分析。
2. Logistic回归适用条件
Logistic回归因变量须是二分类、无序多分类、有序分类变量,自变量可以是定量数据也可以是定类数据,多水平的分类自变量应考虑先转换为哑变量。主要包括以下适用条件:
(1) 定量数据的自变量与因变量的Logit转换值之间存在线性关系,这是由Logistic回归原理决定的,一般情况下该条件是满足的;
(2) 自变量之间无多重共线性,和线性回归类似,在考察多个自变量的影响时,如果存在共线性问题会影响Logistic回归的拟合结果;
(3) 样本量的经验要求,结局中比例较低的分组样本量应是自变量个数的10~20倍以上,比如结局阳性与阴性,普遍来说阳性人群比例较低,100个阳性样本最多只能支持10个自变量,或者说研究者需要考察8个自变量那么要求阳性样本至少有80例。
3. Logistic回归一般步骤
线性回归一般采用最小二乘法进行参数估计,而Logistic回归采用的是最大似然估计法,虽然原理上有所不同,但是整体的分析思路是类似的。针对非条件Logistic回归其一般步骤如下图 5-24所示,适合二元logistic回归与多分类logistic回归。

(1) 基本条件判断
首先检查因变量是否为二分类、多分类、有序分类的其中一种,是则采用对应的二元Logistic回归、多分类Logistic回归、有序Logistic回归,如果因变量为定量数据则采用线性回归。
建议在回归开始前检查异常值情况,以及通过【线性回归】模块以结局变量为因变量,输出各自变量的VIF用来判断有无多重共线性的影响。如发现共线性、异常值等问题,考虑进行有针对性的处理措施,常见的比如剔除或替换个别异常值数据,下一步采取逐步回归等操作。
(2) 建立Logistic回归模型
建立Logistic回归模型的过程,最常见的是“先单后多”,即先通过单因素分析筛选自变量,然后仅保留有显著影响的自变量进行多因素回归。这种场景在探索性研究目的和样本量不足的情况下应用较多。
当研究目的为探索性影响因素分析时,研究者一般会从众多潜在因素中筛选探究哪些因素对因变量有影响。在此种场景下,常见的研究思路是先采用单因素分析筛选出现显著的自变量,然后再做多因素分析。单因素分析可以帮助研究者明确单个因素和因变量的关系,另外在样本量较小的情况下,也可以提前将一些影响作用较小的变量剔除,以简化多因素Logistic回归。
单因素分析常见的方法包括卡方检验、t检验、方差分析或秩和检验,差异的显著性水平可以由0.05适当放宽至0.1、0.15,甚至放宽到0.2,单因素分析显著的自变量保留下来继续做多因素Logistic回归。有一点必须明确,多因素Logistic回归前进行单因素分析并不是绝对的,在样本量充足,研究目标明确,有足够专业理论支持的情况下,可以所有自变量一起进行多因素Logistic回归。
和线性回归类似,多因素Logistic回归时,也可以采用逐步回归的方式对变量进行筛选,比如向前逐步、向后逐步或逐步法,尤其是逐步法Logistic回归在科研中使用较多。
(3) Logistic回归模型的检验与评价
和线性回归模型检验类似,先对模型总体显著性进行检验。具体判断时,可以直接读取似然比卡方检验的概率p值,如果p值小于0.05则认为模型总体有统计学意义;反之如果p值大于0.05则说明模型无效。
Logistic回归常用Hosmer-Lemeshow 检验(简称HL检验)进行拟合优度的评价,适用于含有定量自变量的模型拟合优度评价。原假设模型拟合值和观测值的吻合程度一致,如果p值大于0.05则说明通过HL检验,可认为模型拟合良好;反之p值小于0.05则说明模型没有通过HL检验,模型拟合优度一般或较差。
决定系数R方作为线性回归模型拟合优度的重要指标,其结果得到重视和应用。Logistic回归也提供R方,常见的包括McFadden R方、Cox & Snell R方、Nagelkerke R方,它们被称之为伪R方,其含义和线性回归的决定系数R方,类似,但是经验上在Logistic回归中较少使用。
此外模型预测准确率也可用作模型拟合优度的评价,没有严格的标准,具体由专业经验决定。
(4) 偏回归系数与OR值解释与分析
对Logistic回归方程中各自变量偏回归系数、OR值及其置信区间进行解读,分析哪些因素对研究结局有影响,哪些因素无影响,以及通过OR值对影响的程度进行分析。
(5) 结论报告
综合回归模型显著性检验、模型拟合评价,以及偏回归系数和OR值情况,总结呈现最终的分析结果和结论。
以上内容摘自《SPSSAU科研数据分析方法与应用》第5章——相关影响关系研究,书中不仅涵盖了数据清理、统计分析和模型构建等内容,还提供了丰富的案例,以便于读者在实际研究中应用。

















 7534
7534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









