






文章目录
1. 简介
在强化学习 (RL) 中,仅仅知道“你得了多少分”通常是不够的。单纯追求高分可能会导致各种副作用,例如过度探索、模型不稳定,甚至偏离合理策略的“捷径”行为。为了应对这些挑战,RL 采用了多种机制,例如Ctritic(价值函数)、Clip操作、Reference模型以及较新的组相对策略优化 (GRPO)。
为了使这些概念更加直观,我们打个比方:将强化学习的训练过程想象成小学考试场景。我们(正在训练的模型,Actor)就像努力取得高分的学生,给我们考试评分的老师就像奖励模型,而根据我们的成绩发放零花钱的父母就像评论家(Ctritic)。接下来,让我们逐步了解为什么仅有期末成绩是不够的,评论家(Ctritic)、Clip 和Reference模型如何发挥作用,以及最后 GRPO 如何扩展这些想法。
2. 仅使用奖励的简单方法,会有什么问题?
假设我和弟弟在同一个小学班。老师给我们的考试打分,并给出一个“绝对分数”。我通常能得 80 分以上(满分 100 分),而弟弟通常只能得 30 分左右。然后我们直接拿着这些分数去找爸爸要零花钱——这意味着我们的“奖励”(在现实生活中)就是我们的原始考试成绩。谁的分数更高,谁就能得到更多的零花钱。
乍一看,这似乎没什么问题。但很快就出现了两个大问题:
- 不公平:如果我弟弟通过努力从 30 分提高到 60 分,他仍然比不上我平时的 80 多分。他得不到应有的鼓励。
- 不稳定性:追求更高的分数可能会导致我采取极端的学习方法(例如,整天死记硬背,熬夜)。有时我可能会得到 95 分,有时只有 60 分,所以我的分数(以及奖励信号)波动很大。
因此,使用绝对分数作为奖励会导致奖励波动很大,而我的弟弟最终觉得不值得尝试以小幅度的方式提高。
数学公式
在 RL 中,如果我们简单地这样做:
J
naive
(
θ
)
=
E
(
q
,
o
)
∼
(
data
,
π
θ
)
[
r
(
o
)
]
,
\mathcal{J}_{\text {naive }}(\theta)=\mathbb{E}_{(q, o) \sim\left(\text { data }, \pi_{\theta}\right)}[r(o)],
Jnaive (θ)=E(q,o)∼( data ,πθ)[r(o)],
即“只优化最终奖励”,我们可能会遇到方差过大和部分改进激励不足的问题。换句话说,Actor 缺乏与自身当前水平相匹配的基线,这会阻碍训练效率。
3. 引入评价者:使用“预测分数线”来提高奖励
意识到这个问题后,爸爸意识到“这不仅仅关乎绝对的分数,还关乎你相对于现有水平进步了多少”。
因此他决定:
- 将我的“预计分数线”设为 80 分,将我弟弟的“预计分数线”设为 40 分。
- 如果我们的考试成绩超过这些分数线,我们就可以得到更多的零花钱;如果没有,我们得到的零花钱就很少甚至一分钱都没有。
因此,如果我弟弟努力学习,成绩从 30 分跃升至 60 分,那么他就比“预计分数线”高出 20 分,这意味着他可以获得丰厚的奖励。而如果我的成绩保持在 80 分左右,那么增量收益较小,因此我获得的奖励不一定比他多。这种安排鼓励每个人从自己的基准开始进步,而不是单纯比较绝对分数。
当然,爸爸很忙,所以一旦定下标准,它就不会一成不变——他需要随着我们的进步不断“重新调整”。如果我弟弟的水平上升到 60 分,那么 40 分的底线就不再公平了。同样,如果我一直在 85 分左右徘徊,爸爸可能也需要调整我的标准。换句话说,爸爸也需要学习,特别是了解我和弟弟进步的速度。
数学对应
在 RL 中,这个“得分线”被称为价值函数, V ψ ( s t ) V_{\psi}\left(s_{t}\right) Vψ(st),它充当 baseline。我们的训练目标从“公正的奖励”演变为“我们比基线表现得好多少”,用优势来表达:
A t = r t − V ψ ( s t ) A_{t}=r_{t}-V_{\psi}\left(s_{t}\right) At=rt−Vψ(st)
对于给定状态 s t s_{t} st 和行动 o t o_{t} ot ,如果实际奖励超过了评价者的预期,则意味着该操作的表现优于预期。如果低于预期,则该操作表现不佳。在最简单的公式中,我们优化了类似以下内容的内容:
J adv ( θ ) = E [ A ( o ) ] , where A ( o ) = r ( o ) − V ψ ( o ) \mathcal{J}_{\text {adv }}(\theta)=\mathbb{E}[A(o)], \quad \text { where } A(o)=r(o)-V_{\psi}(o) Jadv (θ)=E[A(o)], where A(o)=r(o)−Vψ(o)
通过减去这条“分数线”,我们减少了训练中的差异,对超出预期的行为给予更高的梯度信号,对未达到预期的行为进行惩罚。
4. 添加 Clip 和 Min 操作:防止过度更新
即使有了“分数线”,也会出现新的问题。例如:
- 如果我突然在考试中取得突破,获得 95 分或 100 分,爸爸可能会给我丰厚的奖励,促使我在下次考试前采取过于激进的学习模式。我的成绩可能会在两个极端之间波动(95 分和 60 分),导致巨大的奖励波动。
因此,爸爸决定限制我每一步更新学习策略的幅度——他不会因为一次考试成绩好就给我成倍的零花钱。如果他给的太多,我可能会陷入极端探索;如果给的太少,我就不会有动力。所以他必须找到一个平衡点。
数学对应
在PPO(近端策略优化)中,这种平衡是通过“Clip”机制实现的。PPO 目标的核心包括:
min
(
r
t
(
θ
)
A
t
,
clip
(
r
t
(
θ
)
,
1
−
ε
,
1
+
ε
)
A
t
)
\min \left(r_{t}(\theta) A_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\varepsilon, 1+\varepsilon\right) A_{t}\right)
min(rt(θ)At,clip(rt(θ),1−ε,1+ε)At)
其中,
r
t
(
θ
)
=
π
θ
(
o
t
∣
s
t
)
π
θ
old
(
o
t
∣
s
t
)
r_{t}(\theta)=\frac{\pi_{\theta}\left(o_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(o_{t} \mid s_{t}\right)}
rt(θ)=πθold (ot∣st)πθ(ot∣st)
表示该动作的新旧策略之间的概率比。如果该比率与 1 偏差太大,则将其限制在 [ 1 − ε , 1 + ε ] [1-\varepsilon, 1+\varepsilon] [1−ε,1+ε],它限制了策略在一次更新中可以转变的程度。
简单来说:
考 100 分会给我带来额外的奖励,但爸爸会给我设定一个“上限”,这样我就不会考得太高。下次考试时,他会重新评估我的成绩,保持稳定,而不是加剧极端波动。
5. Reference模型:防止作弊和极端策略
即便如此,如果我只执着于高分,我可能会采取一些可疑的策略——例如,作弊或恐吓老师给我满分。显然,这违反了所有规则。在大型语言模型领域,类似的情况是制作有害或虚构的内容来人为地提高某些奖励指标。
因此,爸爸又制定了一条规则:
“不管怎样,你都不能偏离你原来诚实的学习态度太多。如果你偏离基准太远,即使你分数很高,我也会取消你的资格并扣留你的零花钱。”
这类似于从学期开始就划定一条“参考线” (即在最初的监督微调之后)。你不能偏离最初的策略太远,否则你会面临处罚。
数学对应
在 PPO 中,这通过对参考模型(初始策略)添加 KL 惩罚来体现。具体来说,我们在损失中包括以下内容:
−
β
D
K
L
(
π
θ
∥
π
r
e
f
)
-\beta \mathbb{D}_{\mathrm{KL}}\left(\pi_{\theta} \| \pi_{\mathrm{ref}}\right)
−βDKL(πθ∥πref)
这可以防止 Actor 偏离原始的合理策略太远,避免“作弊”或其他严重越界的行为。
6. GRPO:用“多重模拟平均值”取代价值函数
有一天,爸爸说:“我没时间一直评估你的学习进度,也无暇画新的分数线。为什么不先做五组模拟测试,然后取它们的平均分作为你的预期分数呢?如果你在真正的测试中超过了平均分,说明你比自己的预期表现更好,所以我会奖励你。否则,你得不到多少。” 我和弟弟,以及可能更多的同学,都可以依靠一套个人的模拟测试,而不是爸爸必须不断调整的外部“价值网络”。
到目前为止,我们看到 PPO 依赖于 Actor + Critic + Clip + KL 惩罚框架。然而,在大型语言模型 (LLM) 场景中,Critic(价值函数)通常需要与 Actor 一样大才能准确评估状态,这可能成本高昂且有时不切实际——尤其是当您最后只有一个最终奖励(如最终答案质量)时。
因此,组相对策略优化(GRPO)应运而生。其核心思想是:
- 评论家没有单独的价值网络,
- 针对同一问题或状态,从旧策略中抽取多个输出样本,
- 将这些输出的平均奖励视为baseline,
- 任何高于平均水平的事情都会产生“正优势”,任何低于平均水平的事情都会产生“负优势”。
同时,GRPO保留了PPO的Clip和KL机制,以确保稳定、合规的更新。
数学对应
根据DeepSeekMath的技术报告,GRPO目标(省略部分符号)是:
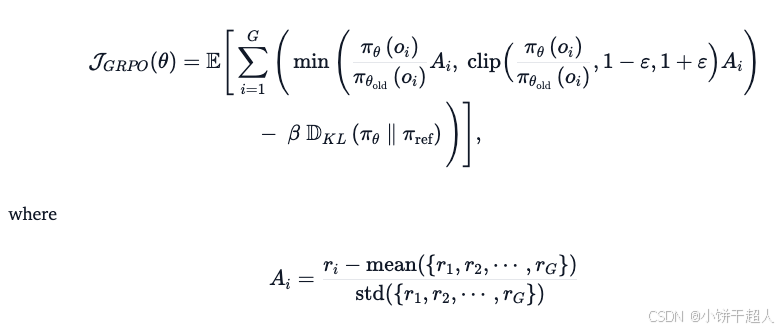
通过对同一问题的多个输出进行平均并进行归一化来计算“相对分数”。这样,我们不再需要专用的值函数,但我们仍然可以获得动态的“分数线”,从而简化训练并节省资源。
7. 结论:反思与未来展望
用小学考试的类比,我们从原始的绝对分数一步步发展到 PPO 的完整机制(Critic、Advantage、Clip、Reference Model),最后发展到GRPO(利用多个输出的平均分来消除价值函数)。以下是一些关键点:
- Critic(批评家)的作用:为每个状态提供“合理期望”,显著减少训练差异。
- Clip 和 Min 机制:限制更新幅度,防止对单次“突破性”检查反应过度。
- Reference模型:不鼓励“作弊”或极端偏差,确保政策与初始状态保持合理一致。
- GRPO 的优点:在大型语言模型中,它消除了对单独价值网络的需求,从而降低了内存和计算成本,同时与“比较”奖励模型设计很好地保持一致。
就像爸爸改用“让孩子们自己模拟多场考试,然后将他们的平均成绩作为基准”的方式一样,GRPO 避免了维持大量的批评,同时仍然提供相对的奖励信号。它保留了 PPO 的稳定性和合规性特征,但简化了流程。

















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









