







文章目录
参考论文 1: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
参考论文 2:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
大模型训练大体可以分为3种模式:
- 预训练(Pretraining)
- 有监督精调(Supervised Fine-Tuning, SFT)
- 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)。
其中,SFT让模型通过学习训练数据数据分布的方式来提高模型在特定任务或指令上的表现,与其不同的是,RLHF使用人类反馈来定义奖励函数,然后通过强化学习算法优化模型。让模型能生成符合人类喜好的回复。
主流的RLHF算法有PPO(Proximal Policy Optimization)、DPO(Direct Preference Optimization)、GRPO等。
一、PPO 和 GRPO 的区别
1.1 PPO
在强化学习领域,PPO 算法被广泛认为是强化学习中的基准算法之一。PPO 采用了 Actor-Critic 架构,通过最大化下面的目标函数来优化模型:
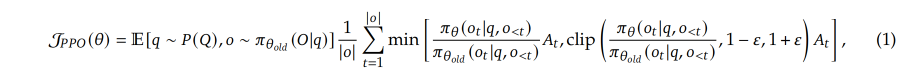
- π θ \pi_{\theta} πθ 是当前的 policy model(最终训练好使用的就是这个模型), π θ o l d \pi_{\theta_{old}} πθold 是老的 policy model
- q 是从 question data 采样的
- o 是从 π θ o l d \pi_{\theta_{old}} πθold 中采样的
- ϵ \epsilon ϵ 是clipping-related的超参数,用于稳定训练
- A t A_t At 是使用 Generalized Advantage Estimation (GAE) 基于 reward 和 value function 计算得到的 advantage,所以 PPO 中 value function 需要同时和 policy model 训练
为了缓解对奖励模型的过度优化,标准方法是在每一步生成的词元(token)的奖励中,加入来自参考模型的逐词元KL散度惩罚,即:
r t = r φ ( q , o ≤ t ) − β log π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) r_t = r_{\varphi}(q, o_{\leq t}) - \beta \log \frac{\pi_{\theta}(o_t | q, o_{<t})}{\pi_{ref}(o_t | q, o_{<t})} rt=rφ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t)
其中:
- r φ r_{\varphi} rφ 是奖励模型
- π r e f \pi_{ref} πref 是参考模型(通常为初始的监督微调模型)
- β \beta β 是KL惩罚系数
PPO使用了四个模型:
- Policy 模型(又称 Actor):输入一段上文,输出下一个token的概率分布。该模型需要训练,是我们最终得到的模型。输出下一个token即为Policy模型的“行为”。
- Value 模型(又称 Critic):用于预估当前模型回复的总收益。该总收益不仅局限于当前token的质量,还需要衡量当前token对后续文本生成的影响。该模型需要训练。value 模型更关注当前和未来的总收益,倾向于更长远的优化。
- Reward 模型:事先用偏好数据进行训练,用于对Policy模型的预测进行打分,评估模型对于当前输出的即时收益。reward 模型只考虑当前模型的回答带来的收益。
- Reference 模型:与 Policy 模型相同,但在训练过程中不进行优化更新,用于维持模型在训练中的表现,防止在更新过程中出现过大偏差。
PPO 在大模型的 RLHF 阶段被成功应用,不断提升模型回复表现的上限。然而,PPO 在计算成本和训练稳定性方面仍然存在一定的挑战。GRPO 算法对此进行了优化,其核心目标是去除 Value 模型,以此来减少训练的计算资源。
下面是两者的对比,图像来源于 Deepseek-math
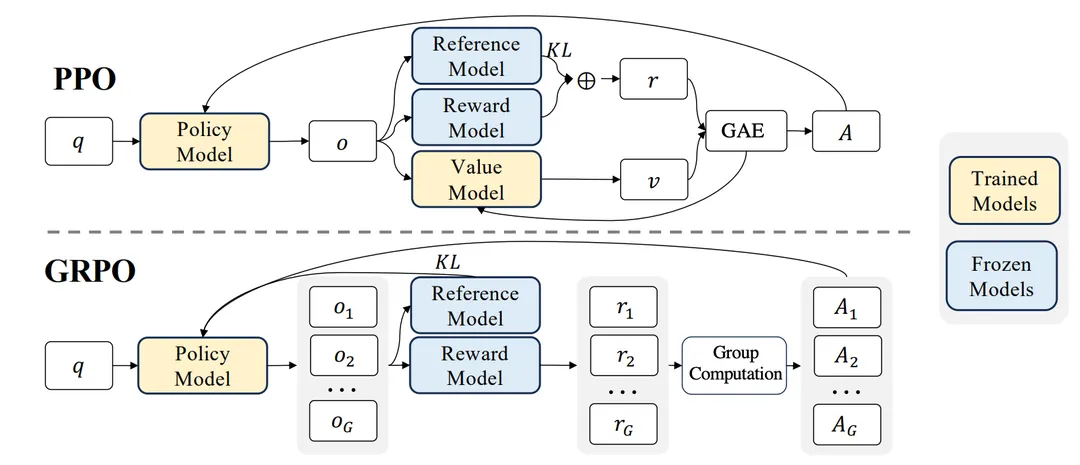
1.2 GRPO
由于PPO需要critic模型来衡量token的得分,GRPO 丢掉了这个模型,使用组内的评价得分来衡量每个响应的质量,不需要独立的为每个响应打分,如果该响应高于组内平均分,则会给一个高分,反之则给一个低分。
对于每个question q, GRPO 会先使用 π θ o l d \pi_{\theta_{old}} πθold 生成一组响应 o 1 , o 2 , . . . , o G o_1, o_2, ..., o_G o1,o2,...,oG,然后通过最大化下面的目标函数来优化 policy model:
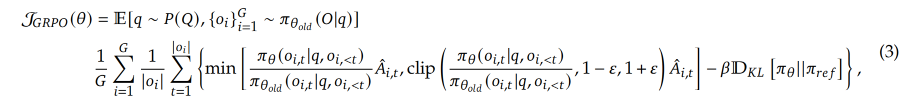
- 𝜀 和 𝛽 是超参数,且 $\hat{A}{i,t} $ 是基于每个组内输出的相对奖励计算的优势
- G是采的回复总数
- o_i是第i个采到的回复,其模就是回复里有多少token
- A ^ i , t \hat{A}_{i,t} A^i,t 是第i个回复的第t个token的优势的估计
- GRPO并不在 reward model 中使用 KL 散度,而是在 policy model 和 reward model 之间计算 KL 散度并直接添加到损失函数中进行正则化,这样可以避免复杂的 A ^ i , t \hat{A}{i,t} A^i,t 计算。
- clip 这里表示更新比率在(1-𝜀 ,1+𝜀 )之间,如果 π θ \pi_{\theta} πθ 和 π θ o l d \pi_{\theta_{old}} πθold 一样,则 clip 更新比率为1
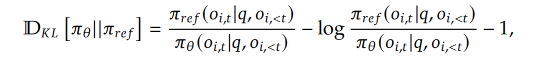
GRPO 的整体过程:

1.2.1 GRPO 的结果监督强化学习
具体来说,对于每个问题𝑞,从旧的策略模型KaTeX parse error: Double subscript at position 13: \pi_{\theta}_̲{old}中采样一组输出{𝑜1, 𝑜2, ···, 𝑜𝐺}。然后使用一个奖励模型对这些输出进行评分,相应地得到𝐺个奖励r = {𝑟1, 𝑟2, ···, 𝑟𝐺}。
接着,将这些奖励进行归一化:减去组平均值后再除以组标准差。结果监督在每个输出𝑜𝑖的末端提供归一化的奖励,并将所有token的优势 A ^ i , t \hat{A}_{i,t} A^i,t设置为归一化的奖励,即 A ^ i , t = e r i = r i − mean ( r ) std ( r ) \hat{A}_{i,t} = e_{r_i} = \frac{r_i - \text{mean}(r)}{\text{std}(r)} A^i,t=eri=std(r)ri−mean(r),随后通过最大化目标函数来优化策略。
1.2.2 GRPO 的过程监督强化学习
结果监督只在每个输出的末端提供奖励,这在处理复杂的数学任务时可能不足且不高效。GRPO 还探索了过程监督,它在每个推理步骤结束时提供奖励。具体来说,给定问题𝑞和从旧策略模型中采样的𝐺个输出{o1, o2, ···, o𝐺},一个过程奖励模型会对每个输出的每个步骤进行评分,产生相应的奖励:
R = { { r i n d e x ( 1 ) 1 , ⋅ ⋅ ⋅ , r i n d e x ( K 1 ) 1 } , ⋅ ⋅ ⋅ , { r i n d e x ( 1 ) G , ⋅ ⋅ ⋅ , r i n d e x ( K G ) G } } R = \{ \{r_{index(1)}^1, ···, r_{index(K1)}^1\}, ···, \{r_{index(1)}^G, ···, r_{index(KG)}^G\} \} R={{rindex(1)1,⋅⋅⋅,rindex(K1)1},⋅⋅⋅,{rindex(1)G,⋅⋅⋅,rindex(KG)G}}
其中,( index(j) ) 是第𝑗步的末端token索引,( K_i ) 是第𝑖个输出的步骤总数。我们还使用平均值和标准差对这些奖励进行归一化,即
r ^ i n d e x ( j ) i = r i n d e x ( j ) i − mean ( R ) std ( R ) \hat{r}_{index(j)}^i = \frac{r_{index(j)}^i - \text{mean}(R)}{\text{std}(R)} r^index(j)i=std(R)rindex(j)i−mean(R)
随后,过程监督将每个token的优势计算为从后续步骤归一化奖励的总和,即
A ^ i , t = ∑ i n d e x ( j ) ≥ t r ^ i n d e x ( j ) i \hat{A}_{i,t} = \sum_{index(j) \geq t} \hat{r}_{index(j)}^i A^i,t=index(j)≥t∑r^index(j)i
然后通过最大化第(3)式中定义的目标函数来优化策略。
1.2.3 GRPO 的迭代强化学习
随着强化学习训练过程的进行,旧的奖励模型可能不足以监督当前的策略模型。因此如算法1中所示,在迭代GRPO中,会基于策略模型的采样结果生成新的奖励模型训练集,并使用重放机制(包含10%的历史数据)不断训练旧的奖励模型。随后,将参考模型设置为策略模型,并使用新的奖励模型不断训练策略模型。
1.3 DeepSeek-R1 中是如何使用的 GRPO

Reward Modeling: DeepSeek-R1-Zero 中使用了基于规则(rule-based)的 reward model,由两部分组成:
-
Accuracy rewards:准确性奖励,准确性奖励模型用于评估响应是否正确。例如,对于结果确定的数学问题,模型需要以规定的格式(例如在一个框内)提供最终答案,从而可以进行可靠的基于规则的正确性验证。同样地,对于LeetCode问题,可以使用编译器基于预定义的测试用例生成反馈。
-
Format rewards:格式奖励,除了准确性奖励模型外,还使用格式奖励模型,要求模型将其思考过程放在 和 标签之间。
1.4 PPO 和 GRPO 的对比
PPO 的特点:
- 依赖 Critic 模型,PPO 需要一个额外的 critic 模型来估算每个回答的价值,这会使内存和计算成本翻倍。
- Critic 模型的训练过程复杂,容易出错,尤其是在涉及主观或细微评估的任务中。
- 高计算成本,RL 训练通常需要大量计算资源来不断评估和优化模型的输出。在大规模 LLM 上应用这些方法会进一步加剧计算成本。
- 可扩展性问题,绝对奖励评估在处理多样化任务时存在困难,导致泛化能力受限,难以适用于不同的推理场景。
GRPO 如何应对这些挑战?
-
- 无需 Critic,降低成本, GRPO 通过组内回答比较消除了对独立评估器的依赖,从而大幅降低了计算资源的需求。
-
- 相对评估机制, 它通过对比同一组回答的表现来衡量质量,而非单独打绝对分,这使得模型能够更直观地识别哪些回答更优。
-
- 高效训练,易于扩展 聚焦于组内优势的计算,使得奖励估计过程更简单,进而使训练过程既高效又便于扩展到大规模模型上。
GRPO 的核心思想是 相对评估,具体而言:
-
每个输入,模型会生成一组可能的回答。
-
这些回答不会单独评估,而是通过相互比较来确定优劣。
-
奖励机制,基于回答相对于组内平均水平的优势或劣势,而非绝对得分。
-
PPO 使用 Value 模型来估计模型回复的总收益,这实际上是对未来模型回复各种可能性的一个平均分值估计
-
GRPO 是通过大模型根据当前的上文输入进行多次采样,生成多个预测结果,并分别使用 Reward 模型对这些预测结果进行评分得到,最后取这些评分的平均值来替代 Value 模型的预期总收益估计。通过这种方式,GRPO 在训练过程中可以减少一个模型的前向和反向传播计算,从而降低计算资源的消耗。
这种方法不仅提升了训练效率,还通过组内竞争不断推动模型优化推理能力。
二、GRPO 的 🌰
GRPO 完整流程解析
步骤1:选取查询 (q)
从训练数据集
P
(
Q
)
P(Q)
P(Q) 中随机选取一个查询
q
q
q。例如:
- 案例1: q 1 q_1 q1 = “8 + 5 的和是多少?”
- 案例2: q 2 q_2 q2 = “圆的面积公式是什么?”
- 案例3: q 3 q_3 q3 = “用五言绝句描述春天”
步骤2:生成回答组
{
o
1
,
o
2
,
.
.
.
,
o
G
}
\{o_1, o_2, ..., o_G\}
{o1,o2,...,oG}
语言模型为查询生成
G
G
G 个候选回答:
o
i
∼
π
θ
(
o
∣
q
)
,
i
=
1
,
2
,
.
.
.
,
G
o_i \sim \pi_{\theta}(o|q), \quad i=1,2,...,G
oi∼πθ(o∣q),i=1,2,...,G
步骤3:计算奖励
r
i
r_i
ri
通过多维度评分函数
R
(
o
i
,
q
)
R(o_i, q)
R(oi,q) 计算奖励:
r
i
=
R
acc
+
R
format
+
R
lang
r_i = R_{\text{acc}} + R_{\text{format}} + R_{\text{lang}}
ri=Racc+Rformat+Rlang
其中:
- 准确性奖励 R acc R_{\text{acc}} Racc:答案是否正确(0/1或连续值)
- 格式奖励 R format R_{\text{format}} Rformat:是否符合指定格式(如数学符号、诗歌平仄)
- 语言一致性奖励 R lang R_{\text{lang}} Rlang:是否出现语言混杂、逻辑断裂
步骤4:组内优势计算
计算每个回答的相对优势(Advantage):
A
i
=
r
i
−
r
ˉ
,
其中
r
ˉ
=
1
G
∑
j
=
1
G
r
j
A_i = r_i - \bar{r}, \quad \text{其中 } \bar{r} = \frac{1}{G}\sum_{j=1}^G r_j
Ai=ri−rˉ,其中 rˉ=G1j=1∑Grj
优势值
A
i
A_i
Ai 反映回答在组内的相对质量。
案例1:数学公式题
查询: q q q = “圆的面积公式是什么?”
生成回答:
- o 1 o_1 o1: “面积公式为 S = π r 2 S = \pi r^2 S=πr2,其中 r r r 是半径。”
- o 2 o_2 o2: “ π r \pi r πr 的平方。”
- o 3 o_3 o3: “圆的面积等于半径乘以周长。”
- o 4 o_4 o4: “面积是 πd²/4,d为直径。”
奖励计算:
| 回答 | 准确性 R acc R_{\text{acc}} Racc | 格式 R format R_{\text{format}} Rformat(LaTeX) | 语言 R lang R_{\text{lang}} Rlang | 总奖励 r i r_i ri |
|---|---|---|---|---|
| o 1 o_1 o1 | 1.0 | 1.0 | 1.0 | 3.0 |
| o 2 o_2 o2 | 0.8(符号不完整) | 0.8(缺少定义) | 1.0 | 2.6 |
| o 3 o_3 o3 | 0.0(错误) | 0.0(无公式) | 0.5(表述模糊) | 0.5 |
| o 4 o_4 o4 | 1.0(正确但非常见形式) | 0.9(LaTeX正确) | 1.0 | 2.9 |
组内优势( r ˉ = 3.0 + 2.6 + 0.5 + 2.9 4 = 2.25 \bar{r} = \frac{3.0+2.6+0.5+2.9}{4} = 2.25 rˉ=43.0+2.6+0.5+2.9=2.25):
- A 1 = 3.0 − 2.25 = + 0.75 A_1 = 3.0 - 2.25 = +0.75 A1=3.0−2.25=+0.75(最优)
- A 4 = 2.9 − 2.25 = + 0.65 A_4 = 2.9 - 2.25 = +0.65 A4=2.9−2.25=+0.65(次优)
案例2:诗歌创作题
查询: q q q = “用五言绝句描述春天”
生成回答:
- o 1 o_1 o1: “春风拂绿柳,细雨润花红。燕舞莺歌处,人间四月天。”
- o 2 o_2 o2: “春天来了,树木发芽,鸟儿在唱歌。”
- o 3 o_3 o3: “Spring breeze blows gently, flowers bloom everywhere.(中英混杂)”
- o 4 o_4 o4: “桃红柳绿时,蝶舞绕芳枝。日暖寒冰化,山川尽展眉。”
奖励计算:
| 回答 | 准确性 R acc R_{\text{acc}} Racc(符合五言绝句) | 格式 R format R_{\text{format}} Rformat(平仄押韵) | 语言 R lang R_{\text{lang}} Rlang | 总奖励 r i r_i ri |
|---|---|---|---|---|
| o 1 o_1 o1 | 1.0 | 0.9(末句稍失对仗) | 1.0 | 2.9 |
| o 2 o_2 o2 | 0.0(非诗歌体) | 0.0 | 0.8(口语化) | 0.8 |
| o 3 o_3 o3 | 0.0(语言混杂) | 0.0 | 0.0 | 0.0 |
| o 4 o_4 o4 | 1.0 | 1.0 | 1.0 | 3.0 |
组内优势( r ˉ = 2.9 + 0.8 + 0.0 + 3.0 4 = 1.675 \bar{r} = \frac{2.9+0.8+0.0+3.0}{4} = 1.675 rˉ=42.9+0.8+0.0+3.0=1.675):
- A 4 = 3.0 − 1.675 = + 1.325 A_4 = 3.0 - 1.675 = +1.325 A4=3.0−1.675=+1.325(最优)
- A 1 = 2.9 − 1.675 = + 1.225 A_1 = 2.9 - 1.675 = +1.225 A1=2.9−1.675=+1.225(次优)
关键点总结
- 组内竞争替代Critic模型:通过组内回答相互比较( A i = r i − r ˉ A_i = r_i - \bar{r} Ai=ri−rˉ),直接利用相对奖励更新策略,无需额外训练价值函数。
- 多维度奖励设计:可根据任务需求灵活调整奖励权重(如数学题侧重准确性,诗歌题侧重格式)。
- 批量生成优化:单次生成多个回答( { o i } \{o_i\} {oi})后排序,比PPO的逐个回答评估更高效。



















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











