







 本文深入解析YOLO目标检测算法,对比RCNN系列,强调YOLO的one-stage模式及高速特性。阐述其运行流程,从7*7*30特征图到网格划分,解析30维向量信息,包括Anchor的坐标、尺寸与置信度,以及类别打分的计算方法。
本文深入解析YOLO目标检测算法,对比RCNN系列,强调YOLO的one-stage模式及高速特性。阐述其运行流程,从7*7*30特征图到网格划分,解析30维向量信息,包括Anchor的坐标、尺寸与置信度,以及类别打分的计算方法。
参考博客
一、YOLO的概念
YOLO这个名字完整体现了算法的精髓:You Only Look Once
它与RCNN系列算法不同。RCNN系列算法(RCNN/Fast RCNN/Faster RCNN)是two-stage模式,即经过了两次检测,第一次是获取proposal box,第二次才是图像预测。YOLO是one-stage模式,使用统一的网络来完成物体识别和框定位。
YOLO虽然精度不如RCNN,但它的速度非常快,在工业界中得到广泛应用。
二、YOYO的运行流程
它的推理流程图如下:
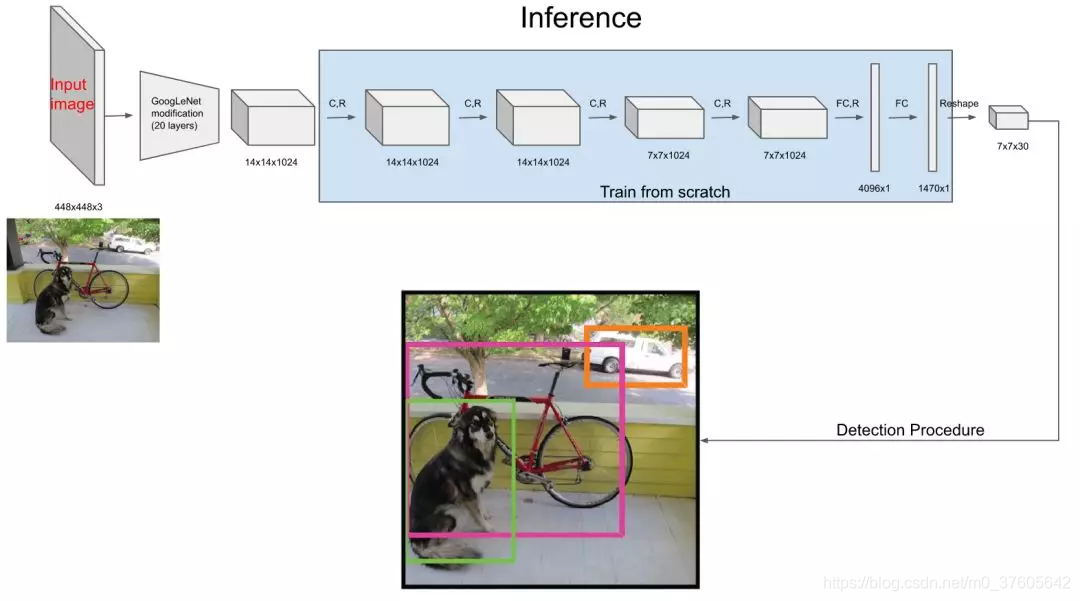
经过网络之后输出为7*7*30的特征图,也就是有49个30维向量。这个特征图意味着什么呢?意味着可以认为将原图划分为7*7的网格,每一个网格对应一个30维的向量。这么说不太严谨,容易误导为:7*7的网格图中的每一个网格的图像信息严格对应7*7*30特征图的每一个向量。要理解这一点先要理解感受野:
如下图,经过卷积得到的3*3的矩阵的元素映射到原矩阵的感受野是2,而并非4/3,且感受野之间是互相重叠的
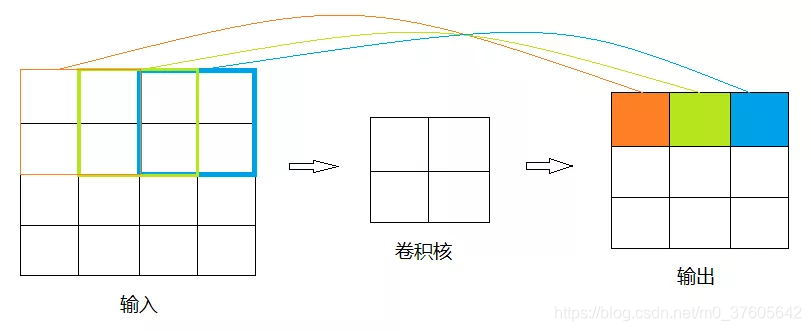
所以说,YOLO流程图里的一个30维向量包含的不仅仅是一个网格的信息,它包含了含有该网格的更大图像范围的信息,这个知识点有利于理解接下来要讲的为什么30维向量里能包含已经超出网格之外的Anchor信息。
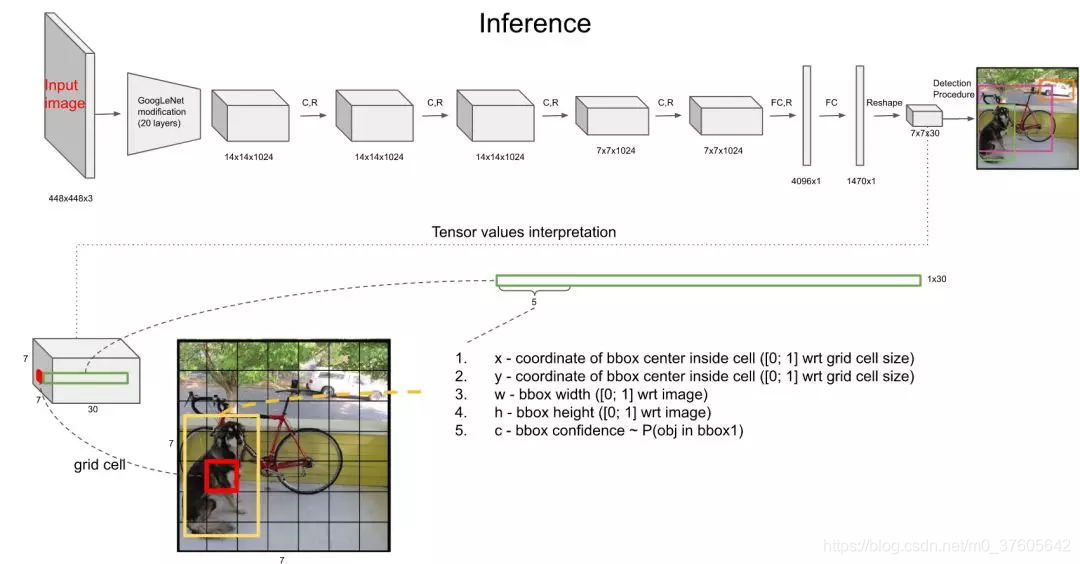
三、30维向量信息解析
30维数据的前5维,是以该网格为中心的第1个Anchor的5个信息:框的x坐标,框的y坐标,框的宽,框的高,框中有物体的置信度
紧接着的5维,是以该网格为中心的第2个Anchor的5个同上的信息
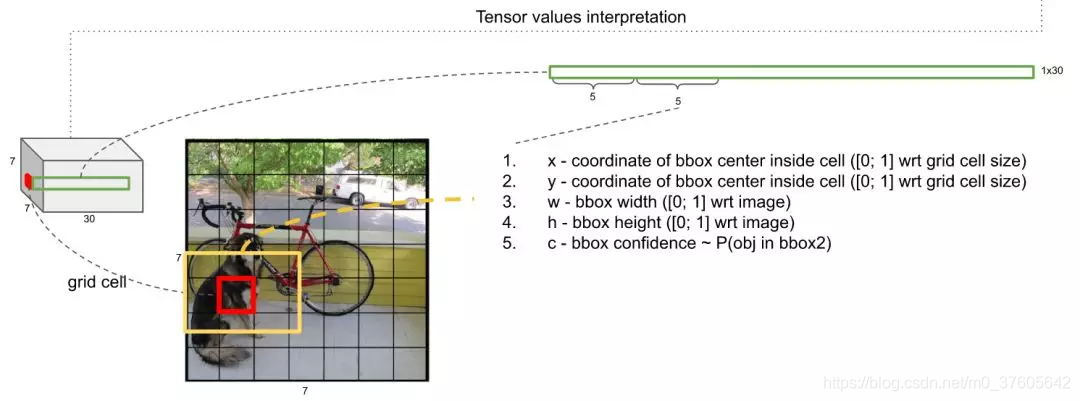
之后的20维中的任何1维度,是该网格为中心的2个Anchor里的图像为某一个类别的打分,这样对每个网格(它的2个Anchor)得到20个打分
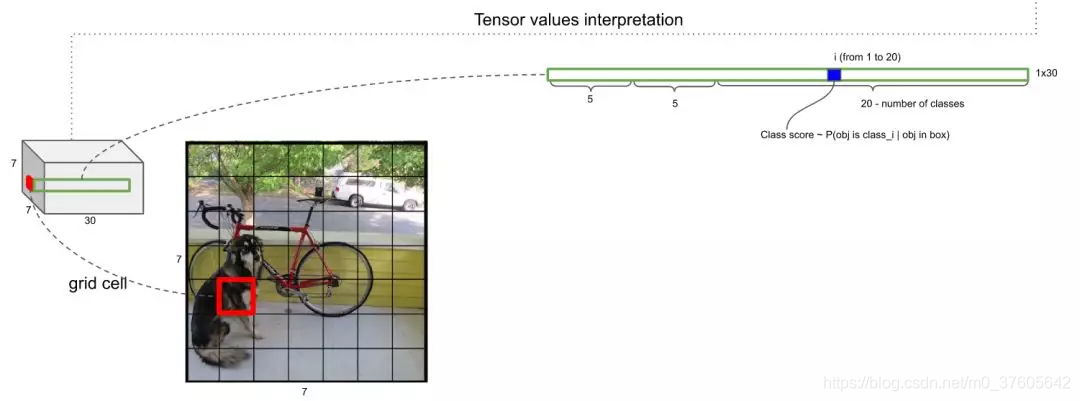
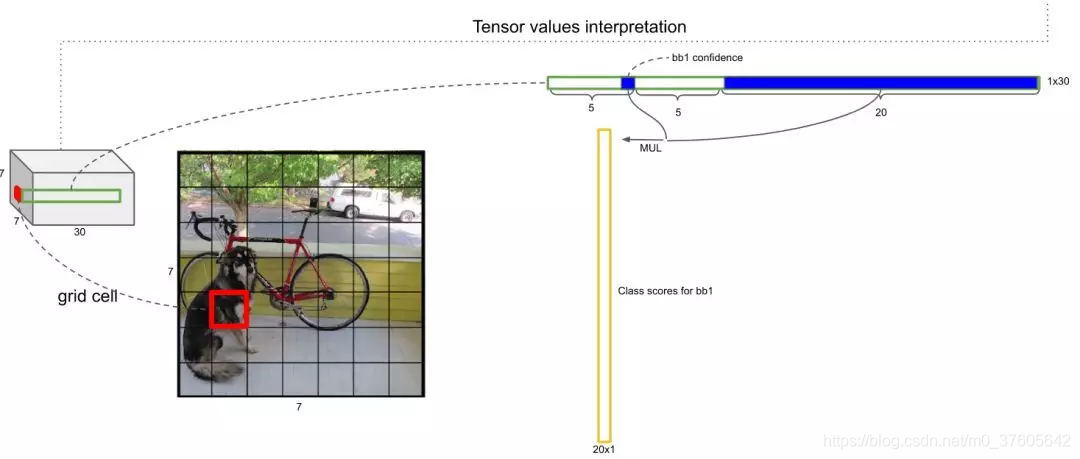
如何获取某个Anchor是某个类的概率呢?——将上述的打分乘以该Anchor有物体的置信度即可,那么每一个Anchor就相当于有一个20维的概率向量:
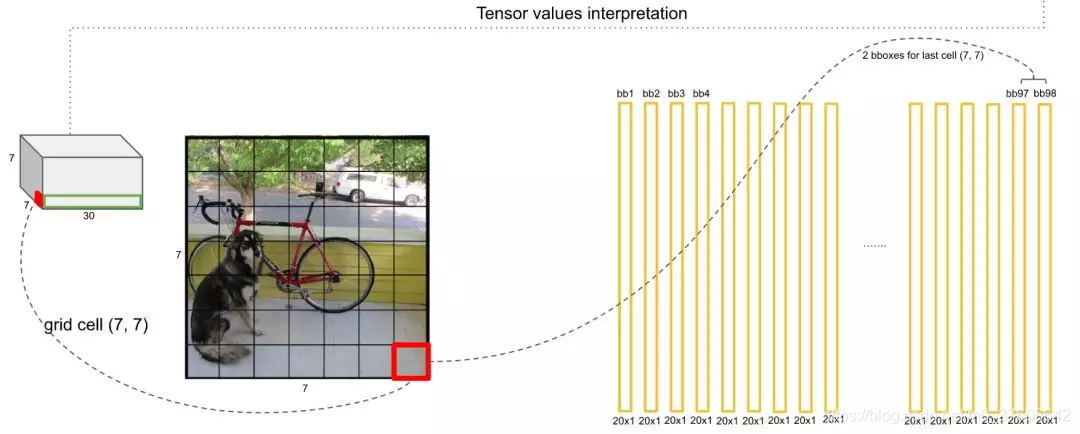
由此,每个网格两个Anchor,也就是有2个20维概率向量,7*7个网格一共有98个20维向量:


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









