






命令
命令格式
perf stat [<options>] [<command>]
例如:
perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] \-- <command> [<options>]
perf stat [-e <EVENT> | --event=EVENT] [-a] record [-o file] \-- <command> [<options>]
perf stat report [-i file]
-
<command>可以是任何一个在 shell 中执行的命令;如果没有 commond ,则代表系统范围
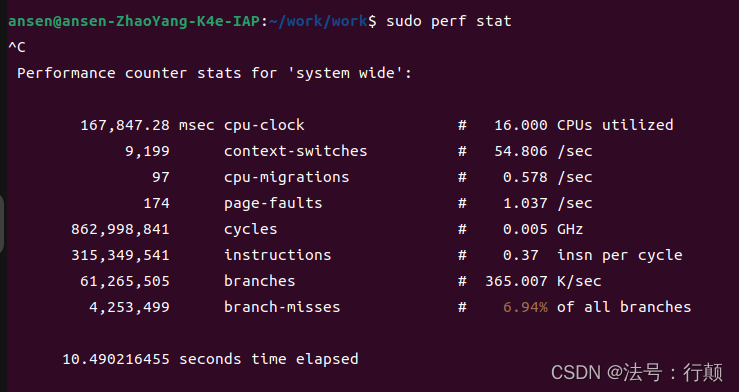
-
record参见 STAT RECORD 部分 -
report参见 STAT REPORT 部分
描述
运行一个命令,并统计该命令的性能计数器的信息
选项
-
-a, --all-cpus
在系统范围搜集所有 CPU 的性能 -
-A, --no-aggr
不汇总所有受监控 CPU 的计数 -
-B, --big-num
根据环境设置显示带有千位分隔符的大数字。 默认启用。可以通过参数 “–no-big-num” 来禁用,也可以通过使用 “perf config stat.big-num=false” 来更改默认设置。 -
-C, --cpu <cpu>
仅提供的 CPU 列表内的计数。 多个 CPU 可以以逗号分隔的列表形式提供,不带空格,例如:0,1; CPU 的范围用 - 指定,例如:0-2。
在每线程模式下,该选项被忽略。 -a 选项对于激活系统范围的监控仍然是必需的。 默认值是依赖所有 CPU。 -
-D, --delay <n>
启动程序后,在测量之前等待几毫秒(-1:在禁用事件的情况下启动)。 这对于过滤掉程序的启动阶段很有用,该阶段通常非常不同。 -
-d, --detailed
显示更详细的统计信息,可以最多定义 3 次参数 描述 -d 增加 L1 & LLC 事件 -d -d 除了上面增加的外,再增加 dTLB & iTLB 事件 -d -d -d 除了上面增加的外,增加预取事件 -
-e, --event <event>
选择 PMU 事件。可以选择如下事件:- 使用 “perf list” 列出的符号事件中的一个
- 使用 rN 形式的原始 PMU 事件,其中 N 是十六进制值,表示带有事件控制寄存器的布局的原始寄存器编码。可以在如下条目中找到所述:
/sys/bus/event_source/devices/cpu/format/*
如果是混合构架的 cpu (例如 intel 12 代 CPU)则命令中的 “cpu” 部分会有不同。
- 一个被冒号和修饰符列表修饰的符号 MPU 或者原始 MPU,例如 cpu-cycles:p,参考 《perf学习笔记(1)》的事件修饰符部分
- 一个参数化的事件,例如
'pmu/param1=0x3,param2/'参数 param1 & param2 在 PMU 的格式在/sys/bus/event_source/devices/<pmu>/format/*文件夹下可以找到定义。
" percore “ 事件限定符表示为 CPU 每个核心的硬件线程单独统计事件。例如perf stat -A -a -e cpu/event,percore=1/,otherevent ... - 以符号形式形成的事件,如
“pmu/config=M,config1=N,config2=K/”,其中 M、N、K 是数字(十进制、十六进制、八进制格式)。每个“config”、“config1”和“config2”参数的可接受值由/sys/bus/event_source/devices/<pmu>/format/*中的相应条目定义。
请注意,最后两种语法支持 PMU 名称中的前缀和全局匹配,以简化大型系统(例如内存控制器 PMU)中相同类型 PMU 的多个实例之间的事件创建。
多个 PMU 实例对于非核心 PMU 来说是典型的,因此在执行此匹配时也会忽略前缀“uncore_”。
-
-G, --cgroup <name>
仅监视名为“name”的容器(cgroup)。 此选项仅在 per-cpu 模式下可用。 必须安装 cgroup 文件系统。 属于容器“name”的所有线程在受监控的 CPU 上运行时都会受到监控。 可以提供多个 cgroup。 每个 cgroup 应用于相应的事件,即第一个 cgroup 应用于第一个事件,第二个 cgroup 应用于第二个事件,依此类推。 可以使用 -G foo,bar 等提供一个空的 cgroup(始终监控)。 Cgroup 必须有相应的事件,即它们始终引用之前在命令行上定义的事件。 如果用户想要跟踪特定 cgroup 的多个事件,用户可以使用“-e e1 -e e2 -G foo,foo”或仅使用“-e e1 -e e2 -G foo”。如果想要监控某个 cgroup 以及系统范围内的“周期”,可以使用此命令行:“perf stat -e Cycles -G cgroup_name -a -e Cycles”。
-
-g, --group
perf stat --group是Linux系统上perf工具的一个命令选项,用于将多个性能计数器组合成一个组,并同时输出它们的计数结果。使用perf stat --group命令,可以将多个性能计数器组合成一个组,并输出每个计数器的计数结果。这样可以方便地比较不同计数器之间的关系和影响。perf stat --group命令的语法如下:
perf stat --group <group1>,<group2>,...,<groupN> command其中,<group1>,<group2>,…,<groupN>表示要组合的性能计数器组,多个组之间用逗号分隔;command表示要执行的命令或应用程序。
下面的命令将将L1缓存命中率和L2缓存命中率组合成一个组,并输出它们的计数结果:
$ perf stat --group L1-dcache-load-misses,L2-rqsts.miss commandTips
使用perf stat --group命令可以方便地组合和比较不同的性能计数器,从而更好地了解应用程序的性能瓶颈和优化方向。需要注意的是,在不同的硬件架构和操作系统环境下,性能计数器的实现和计算方式可能会有所不同,需要根据具体情况选择相应的性能计数器和计算方式。 -
-I, --interval-print <n>
间隔 n 毫秒输出一个计数器的值
例如:'perf stat -I 1000 -e Cycles -a sleep 5'Tips
在某些情况下,开销百分比可能会很高,例如间隔较小、低于 100 毫秒。 谨慎使用。 -
-i, --no-inherit
使用perf stat --no-inherit命令可以禁止子进程继承父进程的性能计数器状态,从而在采集和分析性能数据时更加准确。Tips
需要注意的是,使用perf stat --no-inherit命令可能会影响应用程序的性能,因为每个子进程都需要重新设置性能计数器。另外,在不同的硬件架构和操作系统环境下,性能计数器的实现和计算方式可能会有所不同,需要根据具体情况选择相应的性能计数器和计算方式。 -
-M, --metrics <metric/metric group list>
打印以逗号分隔的列表中指定的指标或指标组。
对于一个组,该组中的所有指标都会被添加。
指标中的事件是自动测量的。 -
-n, --null
不启动任何计数器
这对于测量已用的挂钟时间很有用,或者在不运行任何计数器的情况下评估 perf stat 本身的原始开销。 -
-o, --output <file>
将输出打印到指定文件中 -
-p, --pid <pid>
在现有进程 pid 上的统计事件(逗号分隔列表) -
-r, --repeat <n>
重复命令并打印平均值 + stddev(最大值:100)。 0表示永远
例如:perf stat ls -r 10输出为:
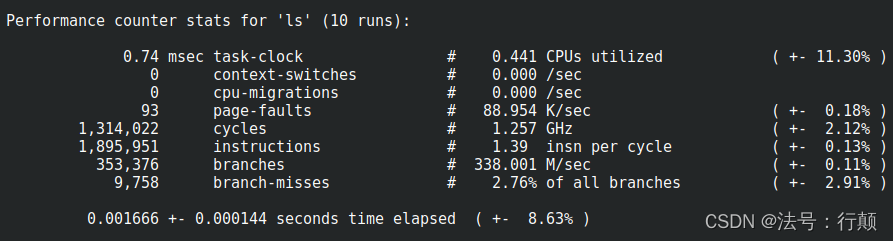
Tips
stddev 是 Linux 系统上 perf 工具的一个命令选项,用于计算性能计数器的标准差,从而了解性能计数器的稳定性和精度。 -
-S, --sync
在开始运行之前调用 sync(),用于将显示的内容同步输出到一个指定的文件中
例如:perf stat --sync -o perf.data ls会在当前文件夹下生成一个 perf.data 文件,文件内容如下:
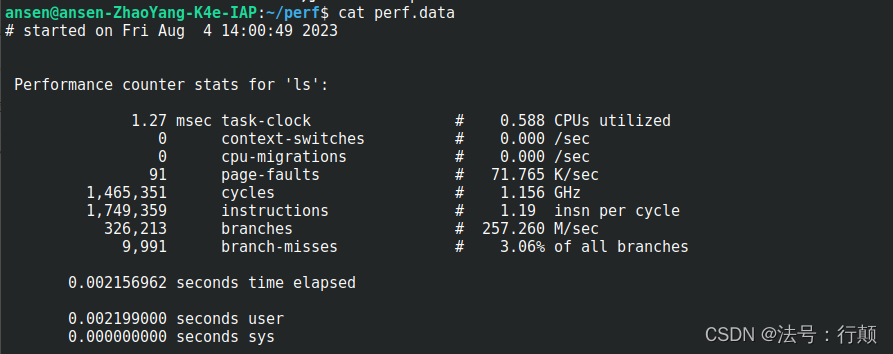
-
-t, --tid <tid>
在现有线程 tid 上的统计事件(逗号分隔列表) -
-T, --transaction
用于采集事务性内存访问(Transactional Memory Access)的性能计数器数据 —— 如果支持。Tips
事务性内存访问是一种新型的多线程并发控制机制,可以提高多线程程序的性能和可扩展性。在事务性内存访问中,多个线程可以同时访问共享内存,而不需要使用传统的锁机制。事务性内存访问通常会使用硬件支持来实现,因此需要使用特定的性能计数器来采集和分析性能数据。需要注意的是,事务性内存访问的性能计数器数据通常与硬件架构和操作系统环境密切相关,不同的硬件架构和操作系统环境可能会有不同的性能计数器和计算方式。因此,在采集和分析事务性内存访问的性能数据时,需要根据具体情况选择相应的性能计数器和计算方式。同时,在使用事务性内存访问时,需要遵循特定的编程规范和限制,以确保程序的正确性和性能。
-
-v, --verbose
用于显示更详细的性能计数器信息;包括每个计数器的名称、描述、事件代码、计数器类型和计数器值等。
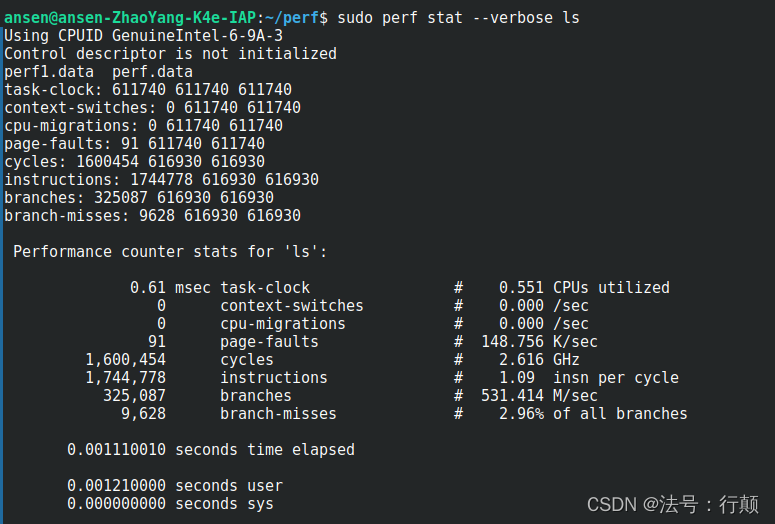
-
-x, --field-separator <separator>
使用 CSV 样式输出打印计数,以便轻松直接导入到电子表格中。 -
–all-kernel
将所有用到的事件运行在内核空间 -
–all-user
将所有用到的事件运行在内核空间 -
–append
将信息追加到 “-o” 参数指定的文件中,如果没有指定 “-o”,则忽略该参数。 -
–control <fd:ctl-fd[,ack-fd] or fifo:ctl-fifo[,ack-fifo]>
ctl-fifo / ack-fifo 打开并用作 ctl-fd / ack-fd,如下所示。
监听 ctl-fd 描述符以获取控制测量的命令(“enable”:启用事件,“disable”:禁用事件)。 可以使用 --delay=-1 选项禁用事件来开始测量。 可以选择将控制命令完成(‘ack\n’)发送到 ack-fd 描述符以与控制进程同步。
用于在测量期间启用和禁用事件的 bash shell 脚本示例:#!/bin/bash ctl_dir=/tmp/ ctl_fifo=${ctl_dir}perf_ctl.fifo test -p ${ctl_fifo} && unlink ${ctl_fifo} mkfifo ${ctl_fifo} exec {ctl_fd}<>${ctl_fifo} ctl_ack_fifo=${ctl_dir}perf_ctl_ack.fifo test -p ${ctl_ack_fifo} && unlink ${ctl_ack_fifo} mkfifo ${ctl_ack_fifo} exec {ctl_fd_ack}<>${ctl_ack_fifo} perf stat -D -1 -e cpu-cycles -a -I 1000 \ --control fd:${ctl_fd},${ctl_fd_ack} \ \-- sleep 30 & perf_pid=$! sleep 5 && echo 'enable' >&${ctl_fd} && read -u ${ctl_fd_ack} e1 && echo "enabled(${e1})" sleep 10 && echo 'disable' >&${ctl_fd} && read -u ${ctl_fd_ack} d1 && echo "disabled(${d1})" exec {ctl_fd_ack}>&- unlink ${ctl_ack_fifo} exec {ctl_fd}>&- unlink ${ctl_fifo} wait -n ${perf_pid} exit $? -
–cputype <hybrid cpu type>
对于混合平台,在指定类型的 cpu 上启用事件,cpu 类型可以为 core/atom
例如:
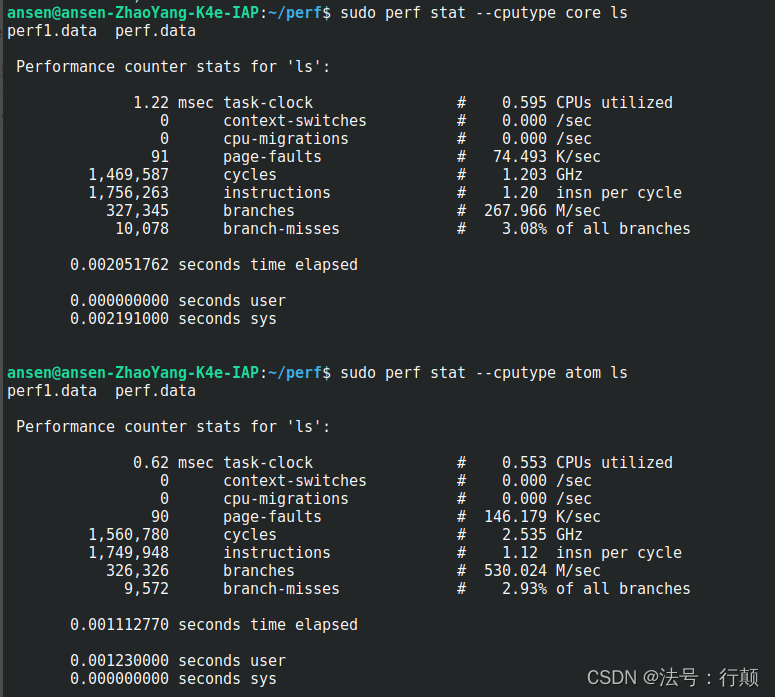
Tips
CPU 的类型可以从/sys/devices/下查看到 -
–filter <filter>
用于对性能计数器的采样事件进行过滤。使用perf stat --filter命令,可以只采集指定的事件,避免采集过多的无用数据,从而更好地分析和优化应用程序的性能。perf stat -e <event> --filter <event1,event2,...> command其中,<event1,event2,…>表示要采集的事件列表,可以是多个事件,用逗号分隔;command表示要执行的命令或应用程序。
-
–for-each-cgroup <name>
展开 “name” 中每个 cgroup 的事件列表(允许用逗号分隔多个 cgroup)。 它还支持正则表达式模式来匹配多个组。 这与为每个事件 x 重复使用 -e 选项和 -G 选项具有相同的效果。 此选项不能与 -G/–cgroup 选项一起使用。 -
–hybrid-merge
合并所有 PMU 的混合事件计数。
对于混合事件,默认情况下,统计数据会聚合并报告每个 PMU 的事件计数。 但有时,聚合所有 PMU 的事件计数也很有用。 此选项启用该行为并报告无需 PMU 的计数。 -
–interval-clear
用于清除perf工具中的计数器和计时器的值。使用perf stat --interval-clear命令,可以在从头开始统计计数器和计时器的值,从而更好地分析和优化应用程序的性能。Tips
需要注意的是,使用perf stat --interval-clear命令时,需要在每次执行perf工具之前使用该命令,以确保计数器和计时器的值从头开始统计。另外,在不同的硬件架构和操作系统环境下,性能计数器的实现和计算方式可能会有所不同,需要根据具体情况选择相应的性能计数器和计算方式。 -
–interval-count <n>
用于设置 perf 工具的统计间隔次数。
示例:perf stat -I 1000 --interval-count 2 -e cycles -a ls该命令使 perf 工具以 1000 毫秒的时间间隔,每2次采样一次CPU周期计数器(cycles),并采集所有进程的事件。最后,perf工具会执行ls命令并输出命令的结果
Tips
该参数需要与 --interval-print 一起使用 -
–iostat[=<default>]
用于显示与输入/输出(I/O)相关的统计信息。使用perf stat --iostat命令,可以监测系统中的I/O活动,例如磁盘读写操作的数量、传输速率、I/O队列长度等,从而更好地分析和优化应用程序的性能。 -
–log-fd <n>
将输出记录到 fd,而不是 stderr。 -
–metric-no-group
默认情况下,计算指标的事件被放置在弱组中。 该小组尝试强制安排所有活动或不安排任何活动。 --metric-no-group 选项将事件放在组之外,并且可能会增加安排事件的机会 - 从而提高准确性。 然而,由于事件可能不会一起调度,因此每个周期的指令等指标的准确性可能会较低 - 因为两个指标可能不再同时测量。 -
–metric-no-merge
默认情况下,如果一个组包含另一组所需的所有事件,则可以共享不同弱组中的指标事件。 在这种情况下,将消除一组,减少事件复用并使某些指标组的总和达到 100%。 共享组的缺点是该组可能需要多路复用,因此不需要多路复用的小组的准确性会降低。 此选项禁止事件合并逻辑在组之间共享事件,并且可用于提高这种情况下的准确性。 -
–metric-only
仅打印计算的指标。 将它们打印在一行中。不显示任何原始值。 不支持 --per-thread -
–no-csv-summary
不要在 CVS 摘要输出的第一列打印“摘要”。 此选项必须与 -x 和 --summary 一起使用。可以通过设置变量在 perf 配置中启用此选项
'stat.no-csv-summary'。
可以使用如下命令进行配置:
perf config stat.no-csv-summary=true -
–no-merge
不合并来自相同 PMU 的结果。
当从单个事件规范创建多个事件时,stat 默认情况下将聚合事件计数并在单行中显示结果。 此选项禁用该行为并显示各个事件和计数。在以下情况下,会根据单个事件规范创建多个事件:
- PMU 名称使用前缀或全局匹配。
- 使用别名,这些别名在 perf list 的内核 PMU 事件之后立即列出。
-
–per-core
用于系统范围模式测量的每个物理处理器的合并计数。 这是检测物理核心之间不平衡的有用模式。 要启用此模式,除了 --per-core 之外,还可以使用 -a(全系统范围)。 输出包括该物理处理器上的核心数量和在线逻辑处理器的数量。 -
–per-die
用于系统范围模式测量的每个 cpu die 上的合并计数。 -
–per-node
用于系统范围模式测量的每个 numa 节点上的合并计数。这是检测 numa 节点之间不平衡的有用模式。 要启用此模式,除了 --per-core 之外,还可以使用 -a(全系统范围)。 -
–per-socket
用于系统范围模式测量的每个 cpu socket 上的合并计数。 -
–per-thread
监视线程(-t 选项)或进程(-p 选项)时,每个受监视线程的聚合计数。 -
–percore-show-thread
事件修饰符“percore”支持对内核中所有硬件线程的事件计数进行求和并显示每个内核的计数。启用事件修饰符“percore”的此选项还会汇总内核中所有硬件线程的事件计数,但显示每个硬件线程的总计数。 这本质上是any bit的替代品并且方便后处理。
-
–post <command>
-
–pre <command>
前后测量挂钩
例如:perf stat --repeat 10 --null --sync --pre 'make -s O=defconfig-build/clean' \-- make -s -j64 O=defconfig-build/ bzImage -
–quiet
不要打印输出、警告或消息。 这对于下面的 perf stat 记录非常有用,仅将数据写入 perf.data 文件。 -
–scale
用于控制perf工具在输出报告时是否对计数器值进行缩放。使用perf stat --scale命令,可以将计数器值缩放到合适的单位,例如将字节转换为千字节或兆字节,从而更好地理解计数器的实际含义。 -
–smi-cost
如果支持 msr/aperf/ 和 msr/smi/ 事件,则测量 SMI 成本。在测量过程中,/sys/device/cpu/freeze_on_smi 将被设置为冻结 SMI 上的核心计数器。
aperf 计数器不会受该设置的影响。
SMI 的成本可以通过(aperf - 未停止的核心周期)来衡量。实际上,SMI 周期的百分比对于面向性能的分析非常有用。 默认情况下将应用 --metric_only。
输出为 SMI 周期百分比,等于 (aperf - 未停止的核心周期) / aperf想要获取实际值的用户可以应用–no-metric-only。
-
–summary
为间隔模式(-I)的显示摘要。 -
–table
以表格格式显示每次运行的时间(-r 选项)perf stat --null -r 5 --table perf bench sched pipe输出
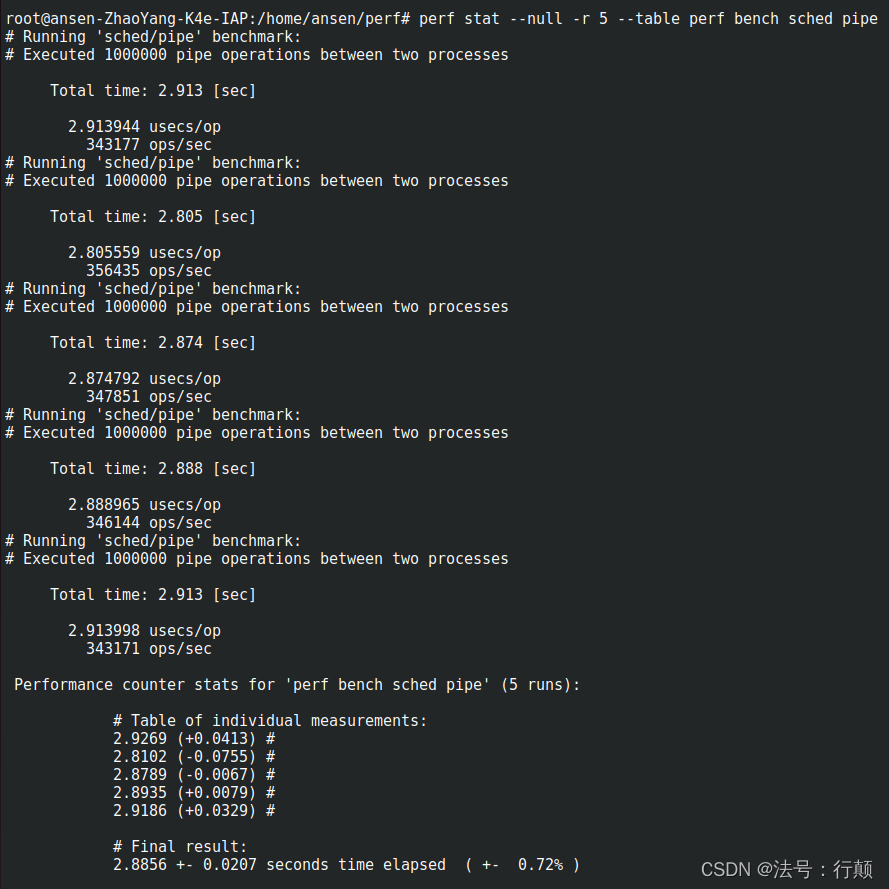
-
–td-level <n>
打印自上而下等于或低于输入级别的统计信息。
它允许用户打印感兴趣的自上而下指标级别,而不是完整的自上而下指标。自上而下指标级别的可用性取决于硬件。 例如,Ice Lake 仅支持 L1 自顶向下指标。 Sapphire Rapids 支持 L1 和 L2 自上而下指标。
默认值:0表示当前硬件支持的最大级别。
如果输入高于支持的最大级别,则会出错。 -
–timeout <n>
“perf stat” 会话在 N 毫秒(最小值:10 毫秒)后停止,并打印计数值。
“-I” 选项不支持此选项。 -
–topdown
打印 CPU 支持的完整自上而下指标。 通过将消耗的周期分解为前端限制、后端限制、不良推测和退出,可以确定 CPU 流水线中 CPU 限制工作负载的瓶颈。- 前端限制(Frontend bound)意味着 CPU 无法足够快地获取和解码指令;
- 后端限制(Backend bound)意味着计算或内存访问是瓶颈;
- 错误推测(Bad Speculation)意味着 CPU 由于分支错误预测和类似问题而浪费了周期;
- 退役(Retiring)意味着 CPU 的计算没有明显的瓶颈;
只有当工作负载实际上受 CPU 而不是其他因素限制时,瓶颈才是真正的瓶颈。为了获得最佳结果,通常最好将其与 -I 1000 等间隔模式一起使用,因为工作负载的瓶颈可能经常发生变化。这将启用 --metric-only,除非用 --no-metric-only 覆盖。
Topdown 使用完整的性能监控单元,并且需要禁用 NMI 看门狗(作为 root):echo 0 > /proc/sys/kernel/nmi_watchdog以获得最佳结果。 否则,随着阶段的变化,工作负载的瓶颈可能会不一致。
为了解释结果,通常需要知道工作负载在哪些 CPU 上运行。 如果需要,可以使用 taskset 命令强制任务运行在指定的 CPU 上。
记录和报告
- 使用
-o file或者--output file可以将结果输出到指定文件中 - 使用
-i file或者--input file可以从指定文件中读取或者报告统计数据·
用法示例
perf stat ls
Performance counter stats for 'ls':
1.35 msec task-clock # 0.615 CPUs utilized
0 context-switches # 0.000 /sec
0 cpu-migrations # 0.000 /sec
92 page-faults # 68.040 K/sec
1,547,041 cycles # 1.144 GHz
1,909,225 instructions # 1.23 insn per cycle
355,704 branches # 263.068 M/sec
11,084 branch-misses # 3.12% of all branches
0.002197920 seconds time elapsed
0.000000000 seconds user
0.002316000 seconds sys
如上例所示,我们可以显示 3 种类型的计时。
我们总是显示计数器启用/活动的时间:
0.002197920 seconds time elapsed
对于工作负载会话,我们还显示工作负载在用户态/系统态中花费的时间:
0.000000000 seconds user
0.002316000 seconds sys
其他
CSV 格式
使用 -x,perf stat 能够输出不完全是 CSV 格式的输出,输出中的逗号不会放入“”中。 为了便于解析,建议使用不同的字符,例如 -x ;
字段按此顺序排列:
- optional usec time stamp in fractions of second (with -I xxx)
- optional CPU, core, or socket identifier
- optional number of logical CPUs aggregated
- counter value
- unit of the counter value or empty
- event name
- run time of counter
- percentage of measurement time the counter was running
- optional variance if multiple values are collected with -r
- optional metric value
- optional unit of metric
JSON 格式
使用 -j,perf stat 能够打印出可用于解析的 JSON 格式输出。
- timestamp : optional usec time stamp in fractions of second (with -I)
- optional aggregate options:
- core : core identifier (with --per-core)
- die : die identifier (with --per-die)
- socket : socket identifier (with --per-socket)
- node : node identifier (with --per-node)
- thread : thread identifier (with --per-thread)
- counter-value : counter value
- unit : unit of the counter value or empty
- event : event name
- variance : optional variance if multiple values are collected (with -r)
- runtime : run time of counter
- metric-value : optional metric value
- metric-unit : optional unit of metric
参考文档
ChatGpt 输出
Linux 源码的说明文档 tools/perf/Documentation

















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









