







 本文深入探讨了主成分分析(PCA)与本征正交分解(POD)的理论与应用,强调这两种方法在数据降维和流场分析中的作用。通过对矢量数据的统计分析,介绍了POD作为优化问题的解决思路,以及PCA在图像处理和机器学习领域的应用实例。
本文深入探讨了主成分分析(PCA)与本征正交分解(POD)的理论与应用,强调这两种方法在数据降维和流场分析中的作用。通过对矢量数据的统计分析,介绍了POD作为优化问题的解决思路,以及PCA在图像处理和机器学习领域的应用实例。
思来想去还是把题目从“简介”改成了“入门(详解)”,其实详解主要就是针对可能没接触过矩阵论的同学,我也是研一才学的,入门是指的我会解释一些名词,方便理解。另外PCA(主成分分析)本质上就是POD,只是我最近翻的热工学论文大部分都用的POD这个名字,而数据分析(或机器学习)方面似乎用PCA这个名字多一些,所以还是以这个名字做了。
本来大部分内容早就完成了,但是一直苦于对降维后的数据处理问题不甚了解,所以翻了很久的资料。因为降维后的数据与元数据并没有直接的数值上的联系,并且也没有明确的物理意义,因此这里的理解卡了很久,现在才知道,降维后的数据与原数据的联系其实中间还包括有均值、特征向量、主成分之间的数值关系,也就是重建的过程。迷惑在这个地方的同学还要重点理一下降维种的两种方法:特征选择和特征抽取。特征选择是从全集中选出子集,而特征抽取则是通过已有特征的组合建立一个新的特征子集。
本征正交分解(Proper orthogonal decomposition),也称为主成分分析法(Principal Components Analysis, PCA)[1-2]。第一次读文献时翻译成了“适当的正交分解”,一头雾水。然后查了半天“适当的正交分解”也没找到,后来直接搜的POD才知道这东西叫本征正交分解。与另一个名字相比,本征正交分解实在不常见:主成分分析。本文是参考文献 [3] 和博客按自己理解写的,有不正确之处恳请指出,互相学习。
1、标准本征正交分解数学模型简介
本征正交分解(以下均称为POD)是一种源于矢量数据统计分析的方法,广泛应用于数据降维,流场分析等等(自己理解的)。
考虑对同一种现象测量 m 次,每次测量值为包含大量 n 个实数项的向量 (这里
为第k个 n 行列向量),
(例如
可以是在第 k 次实验中获得的数字图像)。数据统计分析的一个重要目标就是发现数据中的相互依赖性,并将数据集减少到参数
的更小数量。数学上这种情况可以描述为一种优化问题:
![]()
为实数空间
中的随机实向量,E 为期望值,上式本质上就是求最小均方差,P 为秩 r 的投影算子,即:
![]()
设矩阵 W ,则上述问题对于协方差矩阵的 r 主特征向量有一个解:
![]()
设 ![]() 为 W 的有序特征值
为 W 的有序特征值![]() ,且 vk 对应的正交归一化特征向量,即:
,且 vk 对应的正交归一化特征向量,即:
![]()
则一个最佳的 P 是正交投影:
![]()
当且仅当 ![]() 时,P唯一。
时,P唯一。
在统计学应用中,Wx常用估计值代替:
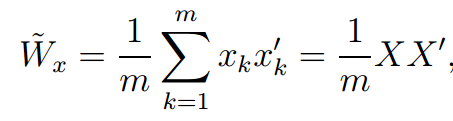
其中xk为测量向量,并假设其独立,并且 X 为 n*m 矩阵,其列为 xk 。
以上推到参考麻省理工的讲义[6],有需要且找不到的私聊。
2、一些名词就是
这部分就针对已经学过线性代数和统计的同学说了,没学过的话那你可以学一遍再搞这些东西了,真的很重要。
(1)优化:优化问题基本就不需要解释了,高中应该就有,比如线性规划、最小二乘等等。
(2)矩阵的秩r(rank):通过矩阵的初等变换,获得(行/列)秩,基本形式见线性代数。
(3)期望值E(Expected value):其实就是平均值。
(4)投影算子:投影和算子其实是分开的,我们通常也可以看到某某算子(sobel算子等),算子的概念就是函数概念的推广,你可以把它理解成函数,但是它实际上就是你在高中学函数之前的“映射”概念!投影就比较有意思了。投影其实就有了降维的含义,根据[5]:
设P是X上的有界线性算子,如果 ,则称P为投影算子。
当P是投影算子时,I-P也是投影算子,且X=PX+(I-P)X。
其实上面讲到投影算子时,P=VU,UV = Ir 就是根据 推出来的。即 P 为投影算子。则
,令
,则
,且
,显然
。
(5)散布矩阵:协方差矩阵。
3、MATLAB 中的函数为pca,可以通过查看帮助文档查看参数。
注:其实理论部分早就写完了,但是在实际做的过程中做到降维之后不知道怎么用数据了,后来看到有些文献里发现是对降维后的数据加上均值,主要在数字图像处理中看到的。
4、算例及其他补充
其实从PCA的角度来说有很多非常详细的推到,PCA最早源于通信理论中的K-L变换。1901年由Pearson第一次提出主要成分分析的方法,直到1963年Karhunan Loeve对该问题的归纳经历了多次的修改[7]。
以下参考主要来源于《精通Matlab数字图像处理与识别》(理论推到十分详细,自行参考):
PCA计算实例:
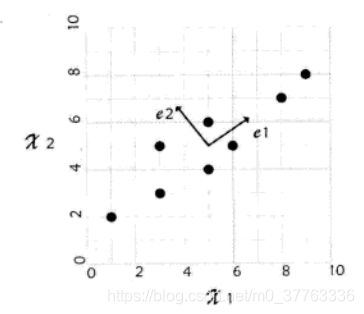
(1)问题描述:计算下面两维数据集合的主成分,并利用PCA方法将数据降至一维和二维。然后尝试利用1个和两个主成分实现对第一个样本的重构。
(2) 计算散布矩阵S的本征向量:
首先计算协方差矩阵S(n-1 倍的系数不会影响本征向量的计算):
样本均值:
(3)计算协方差矩阵特征值(自行计算)
(4)计算特征向量(MATLAB结果):

注意:这里要使特征向量正交归一化,而MATLAB的eig函数好像是具有这个能力的。e1,e2维特征向量加了均值得到的主轴。
(5)降至1维:
通过将8个样本点向其主 e1 投影可以得到这8个样本点的一维表示(偷个懒,截图了),这里向e1 投影而不向 e2 投是有原因的,按数学原理,应对特征值按从大到小排列,e1 对应的特征值最大:
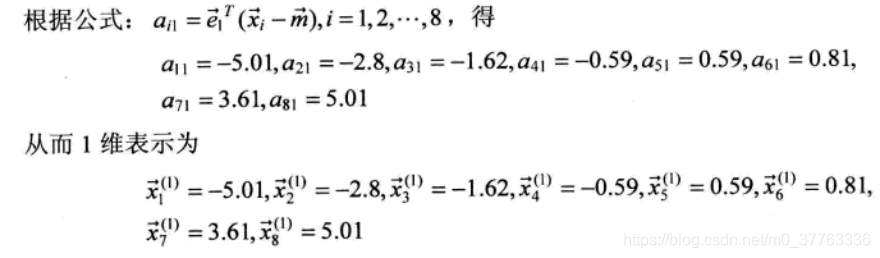
(6)降至2维

(7)重构:
利用第一个主成分分析得到的降维数据进行重构,如果只对第一个(1,2)进行,则:
![]()
重构就是:均值+sum(基*主成分)
当然用于衡量精度的方法可以采用欧式距离:

最后的结论说明:PCA算法中,一般取主成分得分来表示降维后所含有的信息量,而所选用的主成分越多,则其所含有的信息越大,重构得到的数值也就精度越高(这种说法是自己总结的,可能不是很准确)。
参考:
1、https://ww2.mathworks.cn/matlabcentral/fileexchange/58737-pod-moo-m
2、冯俞楷, 杜小泽, 杨立军. 非稳态导热基于温度梯度的本征正交分解降维方法[J]. 中国科学:技术科学, 2018(1).
3、Taehyun Jo, Bonchan Koo, Hyunsoo Kim, Dohyung Lee, Joon Yong Yoon,Effective sensor placement in a steam reformer using gappy proper orthogonal decomposition,Applied Thermal Engineering,Volume 154,2019,Pages 419-432,ISSN 1359-4311,
4、http://blog.codinglabs.org/articles/pca-tutorial.html
5、陈永林. 加权投影算子与加权广义逆矩阵[J]. 应用数学学报, 1983, 6(3):282-291.
6、Proper Orthogonal Decomposition,Massachusetts Institute of Technology,Department of Electrical Engineering and Computer Science,2004。
7、张铮. 精通Matlab数字图像处理与识别[M]. 2013.


















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











