







 本文提出了一种开放世界对象检测方法,利用语义拓扑约束特征空间,防止灾难性遗忘并增强未知类别识别。通过预定义语义锚和一致性目标函数,检测器能在新类别增量学习中保持已知类的特征稳定。实验表明,该方法显著降低绝对开集误差,优于现有技术。
本文提出了一种开放世界对象检测方法,利用语义拓扑约束特征空间,防止灾难性遗忘并增强未知类别识别。通过预定义语义锚和一致性目标函数,检测器能在新类别增量学习中保持已知类的特征稳定。实验表明,该方法显著降低绝对开集误差,优于现有技术。
OBJECTS IN SEMANTIC TOPOLOGY

ICLR2022
Code: 好像没有
摘要
一种更现实的对象检测范式,开放世界对象检测,最近在社区中引起了越来越多的研究兴趣。一个合格的开放世界对象检测器不仅可以识别已知类别的对象,还可以发现未知对象,并在它们的注释逐渐到达时增量学习对它们进行分类。
- 以前的工作分别依靠独立的模块来识别未知类别和执行增量学习。在本文中,我们提供了一个统一的视角:语义拓扑。
- 在开放世界对象检测器的终身学习过程中,来自同一类别的所有对象实例都被分配到语义拓扑中它们相应的预定义节点,包括“未知”类别。
- 这种约束建立了对象之间的判别特征表示和一致的关系,从而使检测器能够将未知对象与已知类别区分开来,并且在增量学习新类别时使已知对象的学习特征不失真。
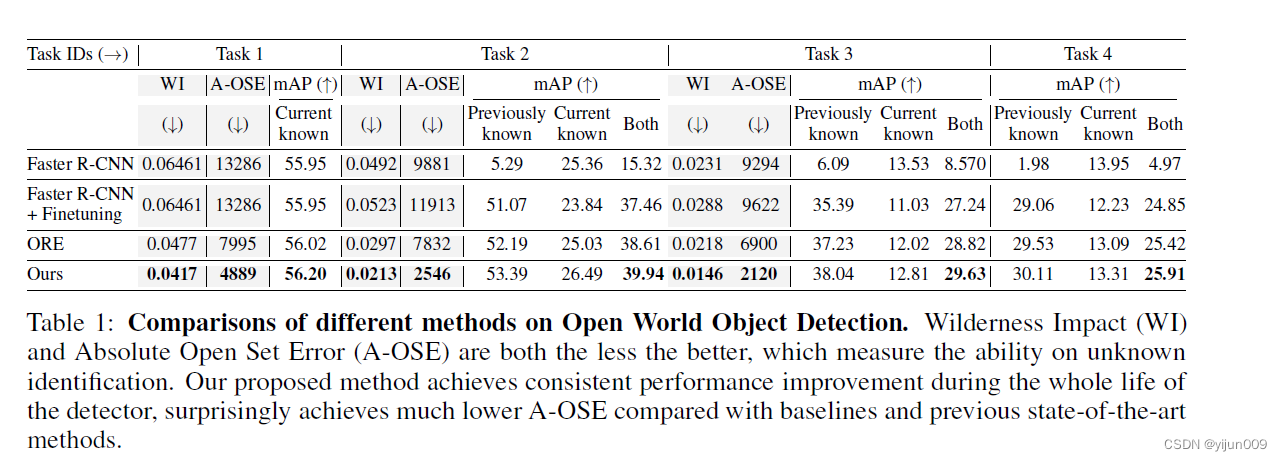
- 大量实验表明,语义拓扑,无论是随机生成的还是从训练有素的语言模型派生的,都可以大大优于当前最先进的开放世界对象检测器,例如绝对开放集误差(被错误标记为已知的未知实例的数量)从 7832 减少到 2546,展示了语义拓扑在开放世界对象检测上的固有优势。
1. 介绍
1.1 大背景
OWOD问题
一个合格的开放世界对象检测器不仅可以识别已知对象,还可以发现未知类别的对象实例,并在它们的注释逐渐到达时逐渐学会识别它们。 新类别的学习总是以增量方式进行,检测器在对新类别进行训练时无法访问所有旧数据。 这种开放世界的学习设置比以前的近距离目标检测更现实,但也更具挑战性。
1.2 小背景
开放世界目标检测对当前检测器提出了两个挑战,即未知类别的识别和增量学习。 一方面,以前的闭集检测器没有明确鼓励类内紧凑性(Liu et al., 2016b; Yang et al., 2021b)。 然而,未知物体识别(发现)非常需要紧凑的特征表示。 如果已知类别占据了大部分特征空间,则检测器可能会将未知对象分类为已知类别之一。 另一方面,目标检测器的普通训练策略缺乏防止增量学习中“灾难性遗忘”的机制(Joseph 等人,2021;Shmelkov 等人,2017a;Peng 等人,2020),即 在学习新类别时,先前已知的对象特征会严重失真。 因此,对新类别的训练会削弱检测器检测先前已知物体的能力。
以前的工作已经努力赋予物体检测器未知识别和增量学习的能力。 代表作品之一,ORE(Joseph et al., 2021) 这是提出OWOD问题的那篇文章的方法 设计了一个聚类损失函数来压缩物体特征,并涉及一种基于能量的失分布识别方法(Liu et al., 2020)来检测未知物体 . 逐步结合这两种独立的技术,使 ORE 成为一个非端到端的框架。 这种开放世界对象检测的解决方案远未达到最佳状态。 此外,ORE (Joseph et al., 2021) 不能保证特征空间拓扑的一致性,这对于有效的新类学习和避免灾难性遗忘至关重要,如Figure 1 所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v4ZTdtdr-1652849273731)(http://qiniu.ruixu.top/1650182492408----6OBJECTS%20IN%20SEMANTIC%20TOPOLOGY.png)]](https://i-blog.csdnimg.cn/blog_migrate/51299a44d077a90933995d482cf65c30.png)
1.3 解决办法
本文以统一的视角形式化了未知识别和增量学习,并提出了一个比现有技术更简单但更有效的开放世界对象检测框架。我们建议开放世界对象检测器学习具有这些特征的特征空间,包括
-(a)判别性:未知对象和新类别的对象不能与特征空间中任何先前已知的类别重叠,以及
-(b)一致性:在学习新类别时,先前已知类别的特征拓扑不会被严重扭曲。
1)我们的关键思想是为每个类别(包括“未知”类别)在特征空间中预先定义一个唯一且固定的质心,并在开放世界对象检测器的终身学习期间将对象实例推向其所属质心.预先定义的质心被命名为“语义锚”,所有的语义锚构成了“语义拓扑”的结构。如Figure 2所示,所有特征都绑定到其相应的语义锚以满足区分度,在增量学习新类别以满足一致性时,保持先前已知的对象特征拓扑。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uw6IgNAO-1652849273732)(http://qiniu.ruixu.top/1650182871390----6OBJECTS%20IN%20SEMANTIC%20TOPOLOGY.png)]](https://i-blog.csdnimg.cn/blog_migrate/e151f5be71dbda024229c775b9cb5903.png)
2)我们引入了一个现成的预训练语言模型来设置语义拓扑。 每个类别的语义锚是通过嵌入相应的类别名称从语言模型中得出的。 当涉及新类时,通过增量注册新的语义锚,语义拓扑逐渐增长。
在实验中,我们表明,通过将当前检测器与我们提出的语义锚头相结合,可以全面提高开放世界对象检测性能。 除了在检测器的整个生命周期内一致的 mAP 改进之外,我们提出的方法的未知识别能力大大优于当前最先进的方法,例如,减少了绝对开集误差 2/3,从 7832 到 2546。
更重要的是,我们通过随机生成语义锚而不是利用语言模型来进行比较实验。 尽管随机生成的锚不提供语义先验,但它们的性能仍然超过了最先进的方法。 这有力地证明了拓扑一致性是开放世界学习的最关键特征,而引入语义关系可以进一步提高性能。
2. 相关工作
这篇文章的质量比较高,把related work也做笔记
2.1 目标检测器的普通训练策略缺乏防止增量学习中
现代目标检测框架(Ren 等人,2015;Redmon 等人,2016;Liu 等人,2016a;Lin 等人,2017;Zhang 等人,2019a;Redmon 等人,2016;Redmon & Farhadi , 2018; Girshick, 2015; Duan et al., 2019; Tian et al., 2019; Tan et al., 2020; Zhou et al., 2019b; Jiang et al., 2018; Zhang et al., 2019b; Carion et al., 2020; Sun et al., 2020b) 利用深度神经网络中的大容量表示来定位和分类给定图像和视频中的目标类对象。 这些成熟的检测器可以在 PascalVOC (Everingham et al., 2010)、MSCOCO (Lin et al., 2014) 等封闭数据集中取得出色的性能。 然而,检测器无法处理开放世界的目标检测,这在现实世界中更为常见。 为此,ORE (Joseph et al., 2021) 提出并形式化了开放世界对象检测问题。
2.2 类增量学习
类增量学习旨在逐步学习分类器以识别迄今为止遇到的所有遇到的类,包括先前已知的类和新的类。知识蒸馏通常用于减轻遗忘旧类的情况,其中存储了一些旧类示例以微调模型或计算蒸馏损失。 iCaRL (Rebuffi et al., 2017) 维护样本的“情景记忆”,并逐渐将新颖的类示例添加到记忆中。然后可以增量获得最近邻分类器。 LwF (Li & Hoiem, 2017) 提出了一种改进的交叉熵损失来保留之前任务中的知识。 BiC (Wu et al., 2019) 指出旧类和新类之间的数据不平衡导致网络的预测偏向于新类。然而,现有的类增量方法无法处理开放世界问题,分类器应识别那些“未知”类并逐步学习识别它们,但现有方法会将未知对象识别为背景。
2.3 开放集学习
在开放集学习中,训练集中包含的知识是不完整的,即推理过程中遇到的示例可能属于训练集中没有出现的类别。 OpenMax (Bendale & Boult, 2016) 使用 Weibull 分布来识别深度网络特征空间中的未知实例。 OLTR (Liu et al., 2019) 提出通过深度度量学习来解决数据不平衡设置中的开放集识别问题。除了开放集分类,Dhamija 等人。 (Dhamija et al., 2020b) 发现物体检测器表现出很高的错误率,会以高置信度将未知类错误分类为已知类。为了解决这个问题,许多工作(Miller 等人,2021;2018a;Dhamija 等人,2020b)旨在测量检测器输出的不确定性以拒绝开集错误。米勒等人。 (Miller et al., 2018a) 使用 Monte Carlo Dropout 采样来估计 SSD 检测器的不确定性。之后,米勒等人。建议为检测器特征空间中的每个类建模一个高斯混合分布,以拒绝未知类。 ORE (Joseph et al., 2021) 使用基于能量的分布外识别方法 (Liu et al., 2020) 来区分已知和未知。然而,这种方法需要在评估过程中计算所有实例(包括已知实例和未知实例)之间的能量得分分布,使得 ORE 成为一种非端到端的方法。我们将开集识别问题和类增量学习制定为一个统一的框架。与 (Joseph et al., 2021) 不同,我们的方法不访问任何未知实例,但实现了更优越的性能。
2.4 零次学习
将图像和文本对齐到一个共同的特征空间一直是一个活跃的研究课题(Frome et al., 2013; Joulin et al., 2016; Li et al., 2017; Desai & Johnson, 2021; Yang et al., 2019 ; 2021a),尤其是在零样本学习方面 (Xian et al., 2017; Bansal et al., 2018; Zareian et al., 2021; Gu et al., 2021)。许多零样本学习研究利用语言模型中的信息来辅助零样本图像分类(Xian 等人,2017)或零样本对象检测(Bansal 等人,2018;Zareian 等人,2021;Gu等人,2021)。然而,这篇论文解决了一个不同的问题,并且对语言模型有不同的用法。我们确定一致的特征流形拓扑在开放世界对象检测中起着至关重要的作用,并且语言模型用于生成可增长且一致的语义拓扑以约束开放世界检测的特征空间学习。此外,本文是第一个结合语言模型(例如 CLIP)来辅助开放世界对象检测的论文,这导致了简单的训练框架和强大的经验性能。
3. 方法
3.1 problem definition
一个开放世界的对象检测器应该检测所有先前看到的对象类,并且还可以识别测试实例是已知的还是未知的(是否属于先前看到的类)。 如果未知,则检测器应在其注释逐渐到达时逐渐学习未知类,而无需从头开始重新训练。
在每个时间点 t t t,我们假设存在
- 一组已知对象类 C k n t = { l 1 , l 2 , … , l C } \mathcal{C}_{k n}^{t}=\left\{l_{1}, l_{2}, \ldots, l_{C}\right\} Cknt={l1,l2,…,lC} 和
- 一组未知对象类 C unk t = { l C + 1 , l C + 2 , … } \mathcal{C}_{\text {unk }}^{t}=\left\{l_{C+1}, l_{ C+2}, \ldots\right\} Cunk t={lC+1,lC+2,…}.
- 检测器 D t \mathcal{D}_{t} Dt 在时间点 t t t 只训练了 C k n t \mathcal{C}_{k n}^{t} Cknt 的类,而在评估期间可能遇到包括 C k n t {C}_{k n}^{t} Cknt 和 C u k n t \mathcal{C}_{uk n}^{t} Cuknt在内的所有类评。
- 除了从已知类 C k n t \mathcal{C}_{k n}^{t} Cknt 中正确分类对象实例外,检测器 D t \mathcal{D}_{t} Dt 还应该标记来自未知类集 C u k n t \mathcal{C}_{uk n}^{t} Cuknt的所有实例。
在时间点 t + 1 t+1 t+1,
- 未知实例将被转发给人类用户,该用户可以选择 n n n 个感兴趣的新类别进行注释并将它们返回给模型。
- 检测器 D t \mathcal{D}_{t} Dt 应该增量学习这些 n n n 新类并将自身更新为 D t + 1 \mathcal{D}_{t+1} Dt+1,而无需从头开始重新训练整个数据集。时间点 t + 1 t+1 t+1的已知类集 C k n t + 1 \mathcal{C}_{k n}^{t+1} Cknt+1也更新为 C k n t + 1 = C k n t + { l C + 1 , … , l C + n } \mathcal{C}_{k n}^{t+1} =\mathcal{C}_{k n}^{t}+\left\{l_{C+1}, \ldots, l_{C+n}\right\} Cknt+1=Cknt+{lC+1,…,lC+n}。
假设已知类 C k n \mathcal{C}_{k n} Ckn 中的数据实例以 { x , y } \{x, y\} {x,y} 的形式标记,其中 x x x 表示图像, y y y 表示注释包括类标签 l l l 和对象坐标,即 y = [ l , x , y , w , h ] y=[l, x, y, w, h] y=[l,x,y,w,h] 其中 x , y , w , h x, y, w, h x,y,w,h 分别表示边界框中心坐标、宽度和高度。
3.2 方法总览
可以识别未知的区域建议网络 (RPN) 和具有判别性和一致性的特征空间是开放世界检测器的两个关键组件。在这里,我们采用 (Joseph et al., 2021) 中提出的 Unknown-Aware RPN,并建议使用预定义的语义拓扑来约束检测器的特征空间拓扑。
- 具体来说,我们为特征空间中的每个类别创建一个唯一且固定的质心,称为语义锚。 所有类的语义锚都是通过将它们的类名前馈到预先训练的语言模型来获得的。
- 我们的关键思想是在检测器的整个生命周期中操纵检测器的特征空间,使其与语义锚构成的语义拓扑保持一致。
- 由于特征维度的差异,使用全连接层(语义投影仪)来对齐 RoI 特征和语义锚之间的维度。
- 在训练阶段,语义投影仪输出的语义特征被设计的“SA(语义锚)头”强制聚集在其相应的语义锚周围。
- 当增量学习时,语义锚逐渐为新类注册新的语义锚,并不断拉近新的类特征及其语义锚。
- 为了减轻由旧类特征失真引起的“灾难性遗忘”,SA Head 语义锚还在学习新类时最小化了一些存储的旧类示例与其语义锚之间的距离。
- 为了更好地利用结构良好的特征空间,我们附加了一个额外的分类层来对语义特征进行分类。
图 3 显示了所提出的开放世界对象检测器的训练流程。在推理时,我们将两个分类头产生的类后验概率相乘,得到最终预测。
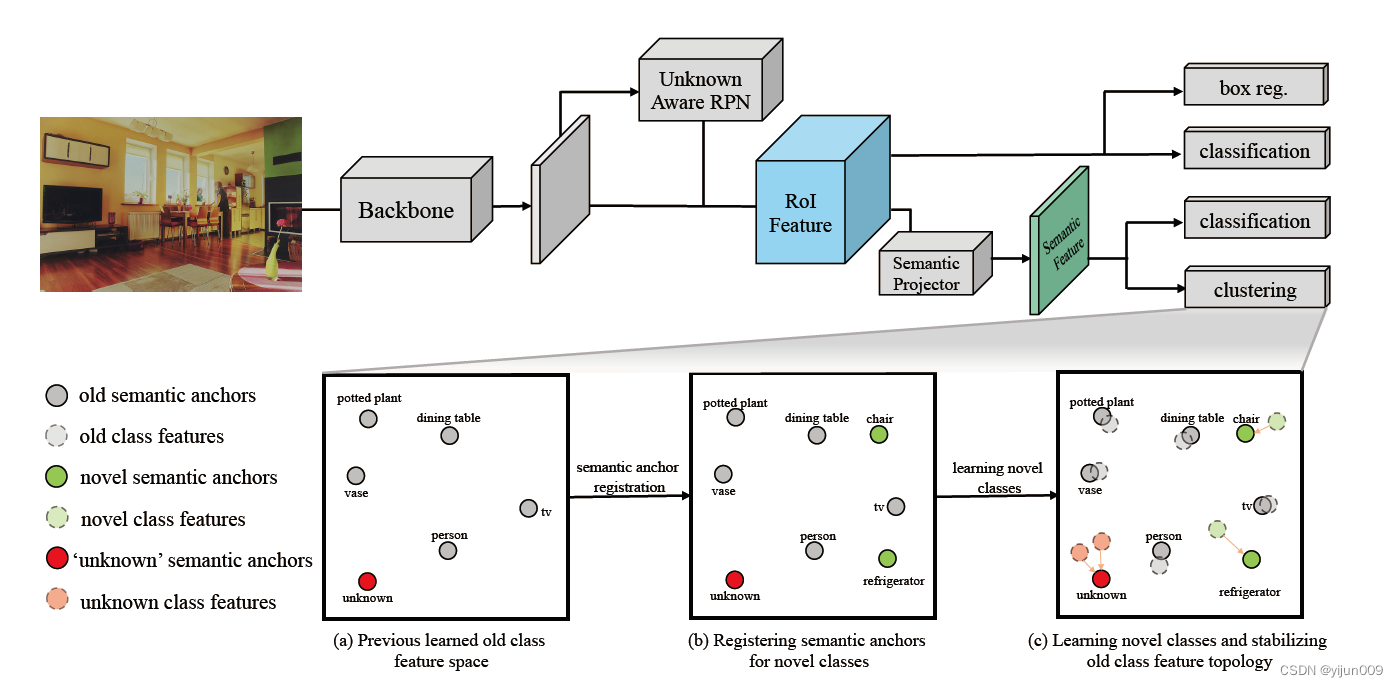
Figure 3. 在训练过程中的特定时间点,将两个新类别(例如椅子和冰箱)的插图引入开放世界对象检测器。 语义拓扑中的每个节点,称为语义锚,在开始训练过程之前由随机生成的向量预定义或从训练良好的语言模型中派生。 当检测器学习到新的类别时,首先将相应的语义锚注册到语义拓扑中,然后将同一类别的对象特征约束到接近其语义锚。 在推理阶段,融合 RoI 特征分类器和语义特征分类器进行预测。
3.3 UNKNOWN-AWARE RPN
需要开放世界对象检测器将潜在的未知对象与背景分离。 因此,我们需要对区域提案网络(RPN)进行一些特定的设计。 在本文中,我们采用了 (Joseph et al., 2021) 中提出的 unknown-ware RPN,它选择 top-k 背景区域建议,按其对象性分数排序,作为未知对象。 未知感知的 RPN 依赖于 Region Proposal Network 与类别无关的事实。 给定输入图像,RPN 生成前景和背景实例的边界框预测,以及相应的对象性分数。 未知感知 RPN 将那些具有高客观性分数但不与任何真实对象重叠的提议标记为潜在的未知对象。
3.4 SEMANTIC TOPOLOGY
我们建议为检测器的特征空间预先定义语义拓扑,而不是从数据中学习。 语义拓扑由语义锚构成。 每个语义锚是对象类的预定义特征质心。 语义锚可以通过使用预先训练的语言模型嵌入相应的类名来生成。 语义拓扑可以随着新类被引入开放世界检测器而动态增长。
在我的理解中,语义拓扑就是类别名字在语义上的映射,可能表示能力更强?
3.4.1 SEMANTIC ANCHOR REGISTRATION
我们通过将类名输入到现成的预训练语言模型中来为所有类生成语义锚。
- 将 l i ∈ C k n t l_{i} \in \mathcal{C}_{k n}^{t} li∈Cknt 表示为在时间 t t t 的第 i i i 个已知类的类名,并将 M \mathcal{M} M 表示为现成的预训练语言模型。
- l i l_{i} li 类的语义锚定义为 A i = M ( l i ) \mathcal{A}_{i}=\mathcal{M}\left(l_{i}\right) Ai=M(li),其中 A i ∈ R n \mathcal{A}_ {i} \in \mathbb{R}^{n} Ai∈Rn,维度 n n n 取决于预训练的语言模型。
- 在 t + 1 t+1 t+1 时,只要已知类集更新 C k n t → C k n t + 1 \mathcal{C}_{k n}^{t} \rightarrow \mathcal{C}_{k n}^{t+1} Cknt→Cknt+1,就重复执行语义锚注册。
请注意,我们还为所有被未知感知 RPN 标记为未知的实例注册了一个语义锚,以更好地将未知实例与已知实例区分开来。 遵循相同的策略,未知类的语义锚也是由未知文本的word embedding生成的。
3.4.2 OBJECTIVE FUNCTION
RoI 特征 f ∈ R d f \in \mathbb{R}^{d} f∈Rd 是由对象检测器的中间层生成的特征向量,用于类别分类和边界框回归。我们操纵 RoI 特征 f f f 来构建检测器的特征流形拓扑。
- 将 f i f_{i} fi 表示为第 i i i个已知类的 RoI 特征,我们首先使用具有 d × n d \times n d×n 维权重的全连接层将 f i f_{i} fi 的维度对齐为其对应的语义锚 A i \mathcal{A}_{i } Ai。对应的语义特征记为 f ^ i ∈ R n \hat{f}_{i} \in \mathbb{R}^{n} f^i∈Rn。
- 我们通过围绕相应的语义锚点聚类语义特征来约束检测器的特征流形拓扑,学习目标形式化为
L s a = ∥ f ^ i − A i ∥ . \mathcal{L}_{s a}=\left\|\hat{f}_{i}- \mathcal{A}_{i}\right\| . Lsa=∥∥∥f^i−Ai∥∥∥.
最小化这种损失将确保所需的特征空间拓扑。 - 为了更好地利用构建的特征空间,我们使用一个额外的分类头来对语义特征 f ^ i \hat{f}_{i} f^i 进行分类,具有与 RoI 分类头相同的标签空间。
- 总的训练目标是语义锚损失
L
s
a
\mathcal{L}_{s a}
Lsa、语义特征分类损失
L
c
l
s
s
e
\mathcal{L}_{cl s_{s e}}
Lclsse、RoI特征分类损失和边界框的组合回归损失:
L total = L s a + L c l s s e + L c l s r o i + L r e g 。 \mathcal{L}_{\text {total }}=\mathcal{L}_{s a}+\mathcal{L}_{c l s_{s e}}+\mathcal{L}_{ c l s_{r o i}}+\mathcal{L}_{r e g} 。 Ltotal =Lsa+Lclsse+Lclsroi+Lreg。
3.4.3 TOPOLOGY STABILIZATION
为了存储旧类的检测能力,存储了一组平衡的样本,并用于在每次增量学习会话之后对模型进行微调,就像之前的开放世界对象检测方法一样(Joseph 等人,2021 年)。 然而,我们认为,忽略旧知识拓扑(Joseph et al., 2021)中的检测器微调仍然存在严重的“灾难性遗忘”问题。 得益于预先定义的特征空间拓扑,我们的方法可以在微调阶段保证一致的特征空间。 存储的旧类和新类实例仍然被迫围绕其预定义的质心进行聚类,以保证特征空间拓扑不变。
4. 实验
和OWOD的实验数据集以及metric一样
4.1 表格
4.2 图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GSyEIkgJ-1652849273735)(http://qiniu.ruixu.top/1650185664359----6OBJECTS%20IN%20SEMANTIC%20TOPOLOGY.png)]](https://i-blog.csdnimg.cn/blog_migrate/7b2fd2700c932204e171519ee8f00b75.png)
图 4:在任务 1 (T1) 和任务 4 (T4) 训练后,ORE 和我们提出的方法的可视化。 在任务 1 中,ORE 经常将未知对象错误分类为已知对象类别之一。 在对任务 4 进行训练后,ORE 成功地检测到了新类,但忘记了在任务 1 中学习到的对象。通过在检测器中明确引入语义先验以约束特征空间拓扑,我们提出的方法在开放世界对象检测中表现良好。

















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









