







注:该实例需要梯子。
美国月度公布的世界农产品供需平衡表对研究农产品是必不可少的素材,本章是一个完整实例,爬取历年发布的wasde报告。USDA网站中有提供历史数据库查询与下载,但经过核对发现有些类目在wasde报告中有,而数据库中下载的数据中没有,为了更贴近研究需求,直接获取所有的wasde报告。
目录
写在前面
1. wasde报告有提供xls、txt、xml和pdf下载,但不是所有时间点都有这四种方式提供,早期的只有pdf,有些时间点只提供这四种方式中的几样,本例操作中,优先xls,其次txt,最次pdf
2. 获取xls或txt或pdf文件后,需要某项数据需要从文件中提取出来,xls和txt的提取方便,pdf不方便,网站中获取的pdf需要经过ocr转成txt,比较费劲
3. 从爬取到最终获得数据,前后步骤较多,有点复杂,需要耐心
步骤一:获取目录
将目录所在的html文件下载
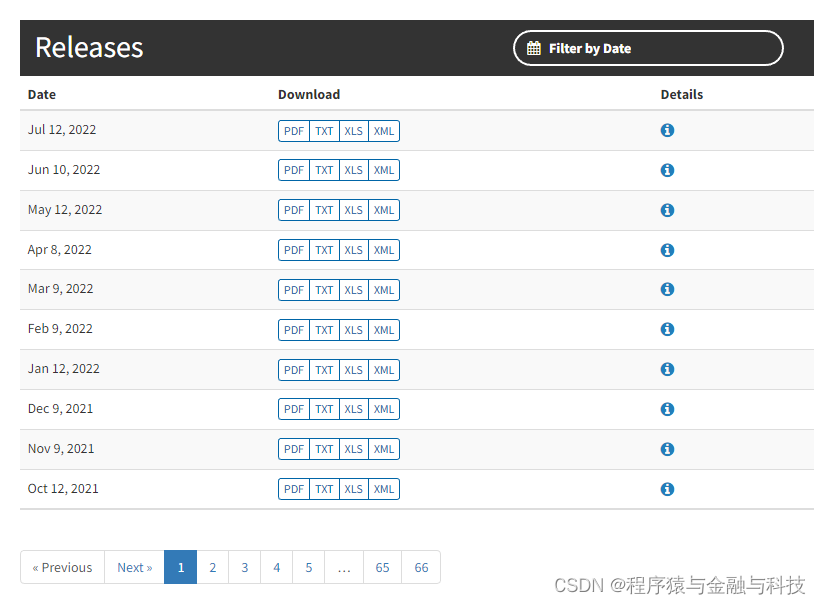
目录共计66页,改变url中的页码,下载这66页目录的html文件
import os,json,requests,urllib3
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
from tools import mongodb_utils,date_tools,string_tools
import xlrd
def wasde_step_one():
pre_dir = r'D:/temp006/'
driver = webdriver.Chrome('../driver/chromedriver.exe')
# 设置超时时间 10s
driver.set_page_load_timeout(10)
for i in range(1, 67):
print(i)
url_str = f"https://usda.library.cornell.edu/concern/publications/3t945q76s?locale=en&page={i}#release-items"
driver.get(url_str)
page_source = driver.page_source
file_path = pre_dir + str(i) + '.html'
with open(file_path, 'w', encoding='utf-8') as fw:
fw.write(page_source)
sleep(2)
driver.close()
driver.quit()
pass步骤二:获取xls链接地址
将存在xls链接的地址都获取下来
def wasde_step_three():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(6, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
xls_save_name = f"{date_str}.xls"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers,proxies=proxies,verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'wb') as fw:
fw.write(r.content)
pass
pass分析节点,提取存在xls的目录,并存储到json文件中,并将json文件存储到指定目录下
步骤三:下载xls文件
在步骤二中获取了xls的下载地址,根据这些下载地址下载xls文件
def wasde_step_three():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(1, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
xls_save_name = f"{date_str}.xls"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers,proxies=proxies,verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'wb') as fw:
fw.write(r.content)
pass
pass步骤四:获取txt链接地址
对于没有提供xls文件的目录,获取txt链接地址
def wasde_step_four():
pic_dir = r'D:/temp005/'
pre_dir = r'D:/temp006/html/'
for file_no in range(1, 67):
# print(file_no)
final_list = []
file_name = f"{file_no}.html"
file_path = pre_dir + file_name
with open(file_path, 'r', encoding='utf-8') as fr:
html_content = fr.read()
soup = BeautifulSoup(html_content, 'lxml')
tbody_node = soup.find('tbody', {'id': 'release-items'})
tr_list = tbody_node.find_all('tr')
for tr_node in tr_list:
td_list = tr_node.find_all('td')
td_one = td_list[0]
date_str = td_one.string
res_date_str = date_tools.wasde_trans_date_str(date_str)
td_two = td_list[1]
a_list = td_two.find_all('a')
txt_url = None
has_xls_yeah = False
for a_node in a_list:
if a_node.get('data-label') is None:
continue
data_label = a_node['data-label']
if 'xls' in data_label:
has_xls_yeah = True
break
if 'txt' in data_label:
txt_url = a_node['href']
if has_xls_yeah:
continue
if txt_url is None:
print(f"{file_no}::{date_str}")
continue
final_list.append({
'date': res_date_str,
'url': txt_url
})
save_file_name = f"{file_no}.json"
save_file_path = pic_dir + save_file_name
with open(save_file_path, 'w', encoding='utf-8') as fw:
json.dump(final_list, fw, ensure_ascii=False)
pass承接步骤二,没有提供xls的目录,检查是否提供txt,有则获取并存储到json文件中,并将json文件存储到指定目录下
步骤五:下载txt文件
在步骤四种获取txt下载地址,根据这些下载地址,下载txt文件
def wasde_step_five():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(1, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
xls_save_name = f"{date_str}.txt"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers, proxies=proxies, verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'w',encoding='utf-8') as fw:
fw.write(r.text)
pass步骤六:获取pdf链接地址
对于没有提供xls文件也没有txt文件的目录,获取pdf链接地址
def wasde_step_six():
pic_dir = r'D:/temp005/'
pre_dir = r'D:/temp006/html/'
for file_no in range(1, 67):
# print(file_no)
final_list = []
file_name = f"{file_no}.html"
file_path = pre_dir + file_name
with open(file_path, 'r', encoding='utf-8') as fr:
html_content = fr.read()
soup = BeautifulSoup(html_content, 'lxml')
tbody_node = soup.find('tbody', {'id': 'release-items'})
tr_list = tbody_node.find_all('tr')
for tr_node in tr_list:
td_list = tr_node.find_all('td')
td_one = td_list[0]
date_str = td_one.string
res_date_str = date_tools.wasde_trans_date_str(date_str)
td_two = td_list[1]
a_list = td_two.find_all('a')
pdf_url = None
has_xls_yeah = False
has_txt_yeah = False
for a_node in a_list:
if a_node.get('data-label') is None:
pdf_url = a_node['href']
else:
data_label = a_node['data-label']
if 'xls' in data_label:
has_xls_yeah = True
break
if 'txt' in data_label:
has_txt_yeah = True
break
if 'pdf' in data_label:
pdf_url = a_node['href']
if has_xls_yeah:
continue
if has_txt_yeah:
continue
if pdf_url is None:
print(f"{file_no}::{date_str}")
continue
final_list.append({
'date': res_date_str,
'url': pdf_url
})
save_file_name = f"{file_no}.json"
save_file_path = pic_dir + save_file_name
with open(save_file_path, 'w', encoding='utf-8') as fw:
json.dump(final_list, fw, ensure_ascii=False)
pass承接步骤二,没有提供xls和txt的目录,则获取pdf并存储到json文件中,并将json文件存储到指定目录下
步骤七:下载pdf文件
def wasde_step_seven():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(1, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
if 'pdf' not in url_str:
continue
xls_save_name = f"{date_str}.pdf"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers, proxies=proxies, verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'wb') as fw:
fw.write(r.content)
pass步骤八: 将pdf转成txt文件
该网站下载的pdf文件需要使用ocr识别文本,需要识别的内容为英文和数字,识别效果很好,pdf转换得来的txt文件和直接下载的txt文件在提取数据时需要区分开来,两者无法用同一方法提取
8.1 下载 tesseract-ocr-w64-setup-v5.0.1.20220118.exe 并安装
1). 下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.1.20220118.exe
2)安装时记得勾选安装语言包

3). 选择安装路径,要记得自己所选的安装路径,后面写代码会用到

4). 安装过程时间长,大概要半个小时,并且过程会有多次弹窗, 遇到弹窗都点确定就可以。

8.2 安装Poppler, Poppler主要是协助pdf2image在windows操作系统中操作pdf
1). 下载地址https://blog.alivate.com.au/wp-content/uploads/2018/10/poppler-0.68.0_x86.7z
2). 下载后直接解压,记得解压后的地址,等会代码中需要用到
8.3 安装python需要用到的包
pip install Pillow
pip install pdf2image
pip install pytesseract
8.4 写一个小demo验证tesseract识别文件是否可行
from PIL import Image
import pytesseract
from pdf2image import convert_from_path
def temp_tesseract_demo():
poppler_path = r'D:/python_package/poppler-0.68.0_x86/poppler-0.68.0/bin/'
pytesseract.pytesseract.tesseract_cmd = r'D:\\soft\\ocr\\tesseract.exe'
pdf_file_path = r'E:/temp000/1994_9_12.pdf'
images = convert_from_path(pdf_path=pdf_file_path,poppler_path=poppler_path)
print('开始存储为图片')
pic_pre_dir = r'E:/temp000/pic/'
pic_file_list = []
for count,img in enumerate(images):
img_path = f"{pic_pre_dir}page_{count}.png"
img.save(img_path,'PNG')
pic_file_list.append(img_path)
print('开始转成文本')
txt_pre_dir = r'E:/temp000/txt/'
for file_count,file_item in enumerate(pic_file_list):
print(file_count,file_item)
extracted_text = pytesseract.image_to_string(Image.open(file_item),lang='eng')
txt_file_path = f"{txt_pre_dir}txt_{file_count}.txt"
with open(txt_file_path,'w',encoding='utf-8') as fw:
fw.write(extracted_text)
pass图片文件夹 :
文本文件夹:
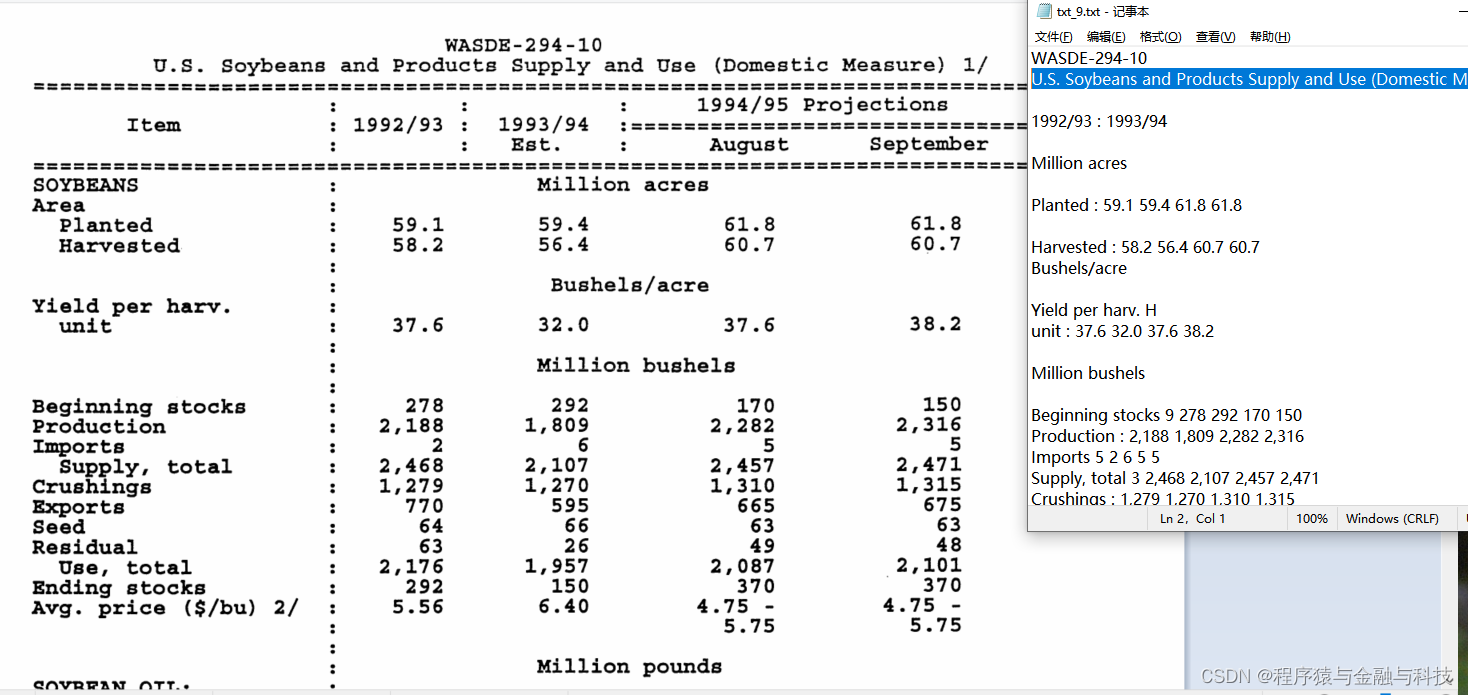
 图片与文本内容对比:
图片与文本内容对比:
 8.5 将pdf文件转png
8.5 将pdf文件转png
def wasde_step_eight_02_00():
poppler_path = r'D:/python_package/poppler-0.68.0_x86/poppler-0.68.0/bin/'
pre_dir = r'E:/temp003/'
save_dir = r'E:/temp002/'
dir_two_list = os.listdir(pre_dir)
for two_dir in dir_two_list:
save_dir_two = save_dir + two_dir
if os.path.exists(save_dir_two):
pass
else:
os.mkdir(save_dir_two)
pre_dir_two = pre_dir + two_dir
pdf_file_list = os.listdir(pre_dir_two)
for pdf_item in pdf_file_list:
print(two_dir,pdf_item)
pdf_name = pdf_item.split('.')[0]
pdf_item_path = pre_dir_two + os.path.sep + pdf_item
pdf_pic_dir = save_dir_two + os.path.sep + pdf_name
if os.path.exists(pdf_pic_dir):
pass
else:
os.mkdir(pdf_pic_dir)
images = convert_from_path(pdf_path=pdf_item_path, poppler_path=poppler_path)
for count, img in enumerate(images):
img_path = f"{pdf_pic_dir}{os.path.sep}page_{count}.png"
img.save(img_path, 'PNG')
pass8.6 将png转txt文本
def wasde_step_eight_02_01():
pytesseract.pytesseract.tesseract_cmd = r'D:\\soft\\ocr\\tesseract.exe'
png_one_dir = r'E:/temp002/'
txt_one_dir = r'E:/temp001/'
png_two_dir_list = os.listdir(png_one_dir)
for two_dir in png_two_dir_list:
txt_two_dir = txt_one_dir + two_dir
if not os.path.exists(txt_two_dir):
os.mkdir(txt_two_dir)
png_two_dir = png_one_dir + two_dir
png_three_dir_list = os.listdir(png_two_dir)
for three_dir in png_three_dir_list:
print(two_dir,three_dir)
txt_three_dir = txt_two_dir + os.path.sep + three_dir + os.path.sep
if not os.path.exists(txt_three_dir):
os.mkdir(txt_three_dir)
png_three_dir = png_two_dir + os.path.sep + three_dir + os.path.sep
png_file_list = os.listdir(png_three_dir)
png_count = len(png_file_list)
for i in range(0,png_count):
png_file_path = f"{png_three_dir}page_{i}.png"
extracted_text = pytesseract.image_to_string(Image.open(png_file_path), lang='eng')
txt_file_path = f"{txt_three_dir}txt_{i}.txt"
with open(txt_file_path, 'w', encoding='utf-8') as fw:
fw.write(extracted_text)
pass至此,整个项目完毕,具体需要的数值到指定的xls、txt或txt(pdf)中提取。















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









