







本篇带你理解特征蒸馏的基本思路、经典方法(如 FitNet 和 Attention Transfer),并实现一个 PyTorch 示例。
一、什么是 Feature-based 蒸馏?
相较于上一篇介绍的 Soft Target(输出蒸馏),Feature-based 蒸馏强调的是:
让学生模型模仿 教师模型中间层的特征表示。
这就好比学生不仅要学会“答对题”(预测分类),还要“思考方式一样”(中间表示一致)。
二、为什么使用 Feature-based 蒸馏?
✅ 优点:
| 特性 | 说明 |
|---|---|
| 更细粒度 | 中间层特征保留更多结构与空间信息 |
| 泛化更强 | 早期层能引导学生捕捉关键模式 |
| 可用于多任务 | 特征蒸馏适用于目标检测、分割等任务 |
局限:
-
教师和学生结构差异大时对齐较难;
-
特征对齐会增加内存和训练复杂度
三、经典方法简析
① FitNet(Romero et al., 2015)
核心思想:让学生中间层 mimick 教师中间层。
-
教师层输出:
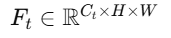
-
学生层输出:
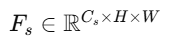
使用一个 regressor(卷积层)把 F_s投影到 C_t维度,再与 F_t计算 L2 loss。
![]()
✅ 强调“低层语义一致性”。
ttention Transfer(Zagoruyko & Komodakis, 2017)
核心思想:不是直接对齐特征,而是对齐“注意力图”。
-
注意力图计算如下:
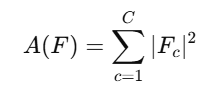
即:对通道求平方再求和,得到一个 H×WH \times WH×W 的注意力热图。
-
蒸馏损失:
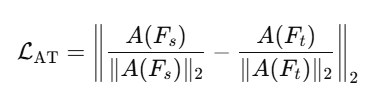
✅ 更关注“学生关注了哪里”。
四、PyTorch 实践:实现 Attention Transfer 蒸馏
我们以 CIFAR-10 分类为例,教师用 ResNet18,学生为简化网络。
✅ Step 1:定义注意力图函数
def attention_map(feature):
# feature: [B, C, H, W]
return torch.norm(feature, p=2, dim=1) # [B, H, W]
✅ Step 2:定义 AT 损失函数
def at_loss(student_feature, teacher_feature):
student_att = attention_map(student_feature)
teacher_att = attention_map(teacher_feature)
student_att = nn.functional.normalize(student_att.view(student_att.size(0), -1), p=2, dim=1)
teacher_att = nn.functional.normalize(teacher_att.view(teacher_att.size(0), -1), p=2, dim=1)
return ((student_att - teacher_att)**2).mean()
✅ Step 3:提取中间特征(hook 方式)
student_feats, teacher_feats = [], []
def get_activation(name, feat_list):
def hook(model, input, output):
feat_list.append(output)
return hook
# Hook 中间层
teacher_model.layer2.register_forward_hook(get_activation('t_layer2', teacher_feats))
student_model.features[2].register_forward_hook(get_activation('s_layer2', student_feats))
✅ Step 4:训练流程
for inputs, labels in dataloader:
student_feats.clear()
teacher_feats.clear()
with torch.no_grad():
_ = teacher_model(inputs)
outputs = student_model(inputs)
loss_ce = nn.CrossEntropyLoss()(outputs, labels)
loss_at = at_loss(student_feats[0], teacher_feats[0])
loss = alpha * loss_ce + (1 - alpha) * loss_at
optimizer.zero_grad()
loss.backward()
optimizer.step()
五、特征蒸馏技巧汇总
| 项 | 建议 |
|---|---|
| 蒸馏层选择 | 可选 shallow、middle 或 deep layers,建议做 ablation |
| 匹配方式 | 可用 conv、1×1 conv、MLP 做维度对齐 |
| 多层蒸馏 | 多层加权融合损失更稳定 |
| AT vs FitNet | AT 对结构兼容性要求低;FitNet 适合有特征对齐机制的结构 |
六、进阶:融合 Soft + Feature 蒸馏
蒸馏损失可以是组合形式:
total_loss = α * CE + β * KL + γ * AT
多源信息引导,能进一步提升学生模型的泛化能力。
七、小结
| 内容 | 说明 |
|---|---|
| ⭐ 蒸馏类型 | Feature-based 提供中间层监督信号 |
| 🔧 方法代表 | FitNet、Attention Transfer |
| 🚀 应用场景 | 分类、检测、分割等多任务模型压缩 |
下一篇预告
📘 第04篇:Relation-based 蒸馏——建模教师与学生间的“结构关系”
-
如何建模特征间的空间/语义关系;
-
介绍 RKD、PKD 等方法;
-
PyTorch 实现实例。

















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









